









pytesseract识别中文并且获得识别的字符的位置信息,识别中文随便找找就能找到相关资料,但是获得位置信息的中文资料有点少呀,下面通过学习这个获得了怎么得到位置信息的方法了。总体来说有两个方法。一个是image_to_boxes,该方法只会返回识别后的位置信息,没有字符;另一个是image_to_data,它返回的信息就多了,位置信息,识别的字符等等(详情可以看上面的链接)。还需要注意的是,image_to_data可以通过output_put参数选择返回数据格式。
image_to_data(image, lang=None, config='', nice=0, output_type=Output.STRING, timeout=0)实验性质的代码如下:
import cv2
import pytesseract
from pytesseract import Output
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import numpy as np
def recoText(im):
"""
识别字符并返回所识别的字符及它们的坐标
:param im: 需要识别的图片
:return data: 字符及它们在图片的位置
"""
data = {}
d = pytesseract.image_to_data(im, output_type=Output.DICT, lang='chi_sim')
for i in range(len(d['text'])):
if 0 < len(d['text'][i]):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
data[d['text'][i]] = ([d['left'][i], d['top'][i], d['width'][i], d['height'][i]])
cv2.rectangle(im, (x, y), (x + w, y + h), (255, 0, 0), 1)
# 使用cv2.putText不能显示中文,需要使用下面的代码代替
#cv2.putText(im, d['text'][i], (x, y-8), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (255, 0, 0), 1)
pilimg = Image.fromarray(im)
draw = ImageDraw.Draw(pilimg)
# 参数1:字体文件路径,参数2:字体大小
font = ImageFont.truetype("simhei.ttf", 15, encoding="utf-8")
# 参数1:打印坐标,参数2:文本,参数3:字体颜色,参数4:字体
draw.text((x, y-10), d['text'][i], (255, 0, 0), font=font)
im = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
cv2.imshow("recoText", im)
return data
if __name__ == '__main__':
img = cv2.imread('2.png')
#cv2.imshow("src", img)
data = recoText(img)
cv2.waitKey(0)
cv2.destroyAllWindows()
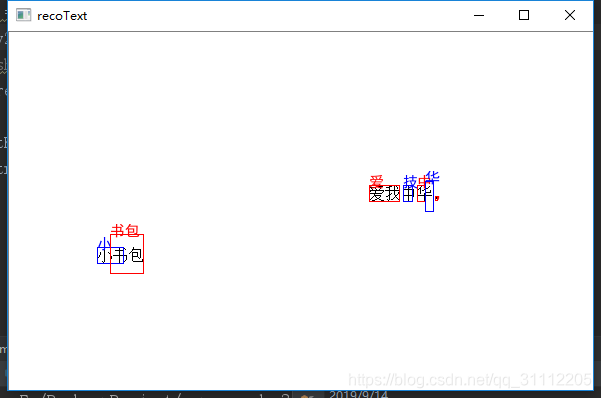
效果如下(从图中可以看出自带的chi_sim识别字库识别效果不是很好呀):

















 4750
4750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









