







参考张大神的这篇文章
主要使用的是node中的fs文件系统的模块
1 图片批量重命名
var fs = require("fs");
var src = 'D:\Testing/img';
//路径写了半天不对,原来是这么写的,如果进入的是子文件,要用反斜线
如果是一个,可以直接使用 var src = 'D:\images';
fs.readdir(src, function(err, files) {
files.forEach(function(filename) {
var oldPath = src + '/' + filename,
newPath = src + '/myImg_' + filename;
fs.rename(oldPath, newPath, function(err) {
if (!err) {
console.log(filename + '图片改名成功!');
}
})
});
});尝试按照文件名称重新排序
var fs = require("fs");
var src = 'D:\Testing/img';
fs.readdir(src, function(err, files) {
files.forEach(function(filename,index) {
var imgEnd = filename.split(".");
var oldPath = src + '/' + filename,
newPath = src + '/myImgs_' + index + "."+ imgEnd[1];
fs.rename(oldPath, newPath, function(err) {
if (!err) {
console.log(filename + '图片改名成功!');
}
})
});
});效果如下
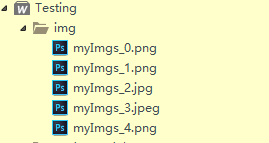
解析:
node 中的 fs 模块是处理关于文件的
其中的fs.readdir方法 用来读取文件目录
fa.readdir(' 文件路径 ',function(err,file){
if(err){
console.log(err)
}else{
console.log(file)
}
//files是一个包含 “ 指定目录下所有文件名称的” 数组
})fs.rename 方法
用来修改文件名称,可更改文件的存放路径。
参考实例
//同以目录下的文件更名:
var fs = require('fs');
fs.rename('125.txt','126.txt', function(err){
if(err){
throw err;
}
console.log('done!');
})
//不同路径下的文件更名 + 移动:(新的路径必须已存在,路径不存在会返回异常)
var fs = require('fs');
fs.rename('125.txt','new/126.txt', function(err){
if(err){
throw err;
}
console.log('done!');
})2 node 分割静态页面
【经常写静态的福利】
代码在这里就不在贴了,和张大神的一样,需要注意的是
这个正则
/<link\srel="import"\shref="(.*)">/gi对应页面中查找的是<link rel="import" href="header.html">
一个空格 而且末尾没有斜杠
由于我I是一个乱敲空格的人【捂脸】,所以把这个正则改了
data.replace
(/<link\s+rel="import"\s+href="(.*)"\s*\/?>/gi, ...)这样对应的html文档应该是 ,哦,还加了一个斜杠
<link rel="import" href="header.html" />然后就是注意这个文件目录问题,
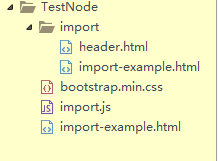
需要组装的字代码的文件放在一个文件夹,但是与你要 NODE 的 import.js 不是同级关系
反正我是在这里摔倒了

3 NODE静态页面分割扩展
因为需要控制的页面不只一个,所以在这个部分就不太合适了,

这里是只是写了一个文件。所以需要改动成,监控所有子静态块
于是用了一个 fs.readdir 去读取文件夹中所有 html文件
改动之后的import。js 内容如下
// 引入fs文件处理模块
var fs = require("fs");
// 测试用的HTML页文件夹地址和文件名称
var src = 'import';
//这里读取所有的文件出来
fs.readdir(src, function(err, files) {
files.forEach(function(filename,index) {
var filename = filename;
// 默认先执行一次
fnImportExample(src, filename);
// 监控文件,变更后重新生成
fs.watch(src + '/' + filename, function(event, filename) {
if (event == 'change') {
console.log(src + '/' + filename + '发生了改变,重新生成...');
fnImportExample(src, filename);
}
});
});
});
var fnImportExample = function(src, filename) {
// 读取HTML页面数据
// 使用API文档中的fs.readFile(filename, [options], callback)
fs.readFile(src + '/' + filename, {
// 需要指定编码方式,否则返回原生buffer
encoding: 'utf8'
}, function(err, data) {
// 下面要做的事情就是把
// <link rel="import" href="header.html">
// 这段HTML替换成href文件中的内容
// 可以求助万能的正则
var dataReplace = data.replace(/<link\srel="import"\shref="(.*)">/gi, function(matchs, m1) {
// m1就是匹配的路径地址了
// 然后就可以读文件了
return fs.readFileSync(src + '/' + m1, {
encoding: 'utf8'
});
});
// 由于我们要把文件放在更上一级目录,因此,一些相对地址要处理下
// 在本例子中,就比较简单,对../进行替换
dataReplace = dataReplace.replace(/"\.\.\//g, '"');
// 于是生成新的HTML文件
// 文档找一找,发现了fs.writeFile(filename, data, [options], callback)
fs.writeFile(filename, dataReplace, {
encoding: 'utf8'
}, function(err) {
if (err) throw err;
console.log(filename + '生成成功!');
});
});
};
最近写了一个文件批量重命名的包,发到npm上了















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









