






我们假设迄今为止讨论的所有数据结构都是单线程访问的。
但 DBMS 需要允许多个线程安全地访问数据结构,以充分利用额外的 CPU ,并隐藏磁盘 I/O 停顿。
并发控制协议【concurrency control protocol】是 DBMS 用于确保在共享对象上的并发操作得到“正确”结果的方法。
协议的正确性标准可能会有所不同:
- 逻辑正确性【Logical Correctness】:线程能否看到它应该看到的数据?比如我插入元素 5 ,然后再来查询元素 5,那么我应该可以查的该元素,如果我删除元素 5 ,那么就不能再查得该元素。
- 物理正确性【Physical Correctness】:对象的内部表示是否健全??比如我们跟随 Page ID 到一个页面内,我们期望在这个页面是我们想看到的页面,而不想里面都是无关的垃圾数据。
1 Latches Overview
1.1 LOCKS V S . LATCHES
Locks (Transactions)
- 保护数据库的逻辑内容【logical contents】(比如 元组【tuple】,数据库【databases】,表【table】)免受其他事务的影响。
- 在事务【transaction】期间持有。
- 需要能够回滚更改。
在我们并发协议中会有一些更高级别的机制来确保我们不会出现死锁,当死锁出现时,数据库系统将有一种机制来回滚事务所做的更改,这样我们就不会有任何部分更新。
Latches (Workers) 它是低级原语
- 保护 DBMS 内部数据结构的关键部分免受其他 worker(例如线程)的影响。
- 在操作【operation】期间持有。
- 不需要能够回滚更改。
| Lock | Latch | |
| Separate… | 事务 | Workers (threads, processes) |
| Protect… | 数据库内容 【Database Contents】 | 内存数据结构 【In-Memory Data Structures】,比如内存中的 b+ 树 |
| During… | 整个事务 | 临界区 |
| Modes… | 共享【share】 排他【exclusive】 更新【update】 意图【intention】 | 读,写 |
| Deadlock | Detection & Resolution | 避免【Avoidance】 |
| …by… | 等待【Waits-for】 超时【Timeout】 崩溃【Aborts】 | Coding Discipline,开发人员会仔细编码来确保不会有死锁发生 |
| Kept in… | Lock Manager | 受保护的结构 |
1.2 Latch Mode
Read 模式
- 多个线程可以同时读取同一个对象。
- 如果一个线程处于读模式,则另一个线程可以立即获取读锁存器。
Write 模式
- 只有一个线程可以访问该对象。
- 如果一个线程在任何模式(无论是读还是写模式)下拥有锁存器,则其他的线程无法获取写锁存器。

1.3 锁存器实现的目标
- 内存占用小,我们不希望为了实现锁存器而存储非常多的元数据
- 无争用时,即没有两个 worker 或者 threads 在同时获取锁存器,我们想以最小的开销执行得越快越好,我得到了锁存器,并把事情做好了
- 每个锁存器不必实现自己的队列来跟踪等待线程(即没有得到锁存器而处于等待中的 worker)
而这些能力,OS 已经提供了
1.4 锁存器的实现
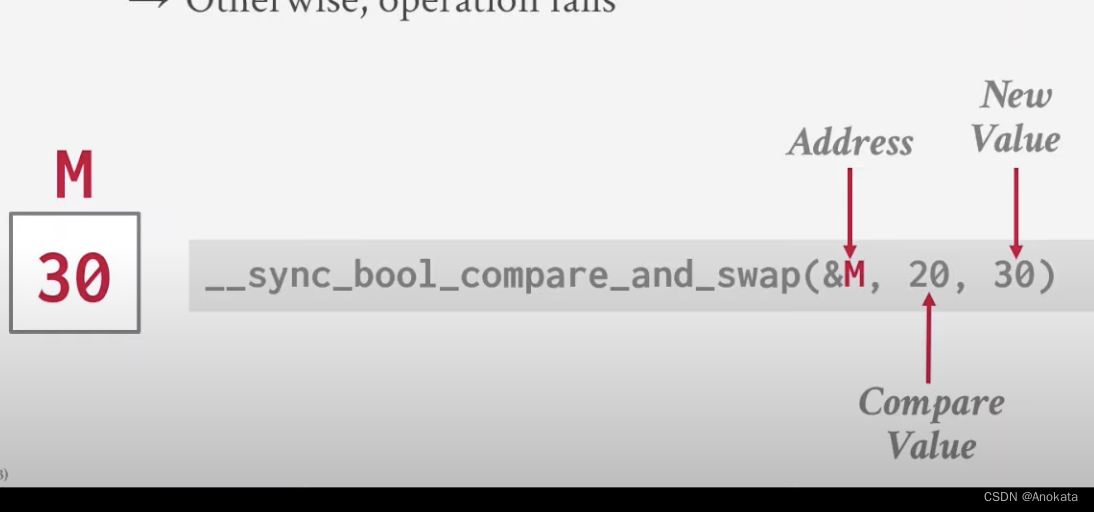
Compare And Swap [CAS]
CAS 是一个原子指令,负责将内存位置M的内容与给定值V进行比较:
- 如果相等,则将新值插入内存M处
- 否则,插入失败
方法1 Test-and-Set Spin Latch (TAS)
- 非常高效(单指令锁存/解锁)
- 不可扩展、缓存不友好、OS 不友好。
- 示例:std::atomic<T>
下面是代码大概的样子:

我们会发现这种实现的弊端:
- 你基本上是在自旋循环,这会让CPU一遍又一遍地检查,可能会带来资源的浪费
- 即某个 CPU 基座【socket】正在尝试获取在另一个 CPU 基座【socket】的内存中持有的锁存器,而这个过程是非常慢的
方法2 Blocking OS Mutex
- 使用简单,它是库包提供的,而我们要做的只是获取【acquire】和释放【release】它,他没有很多机制
- 不可扩展(每次锁定/解锁调用大约 25ns)
- 示例:std::mutex -> pthread_mutex -> futex

这个方案依然是有弊端的,当锁存器没有被获取时,我们获取操作知识用户空间的一个简单 CAS,但是如果锁存器被其他 worker 持有,那么当前 worker 会被阻塞,而操作系统也会有诸如哈希表的数据结构来维护线程执行状态,因此 OS 也会有自己的锁存器来保护这种内部结构,所以如果我无法得到锁存器,那么就会进入内核态,并等待重新调度,而这个过程时非常昂贵的。
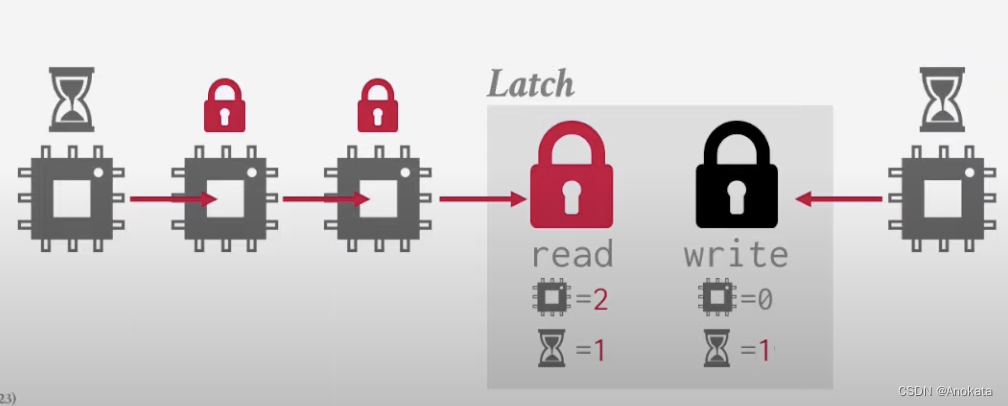
方法3 Reader-Writer Latches
- 允许并发读,但是必须管理读/写队列以避免饥饿【starvation】。
- 可以在自旋锁的基础上实现。
- 示例:std::shared_mutex -> shared_mutex -> pthread_rwlock
栗子
1️⃣ 当我们有一个 worker 尝试获取读锁,我们去看看是否有 worker 等待读锁,否则我们增加读锁存器的计数器,表明有人正在持有该锁存器。
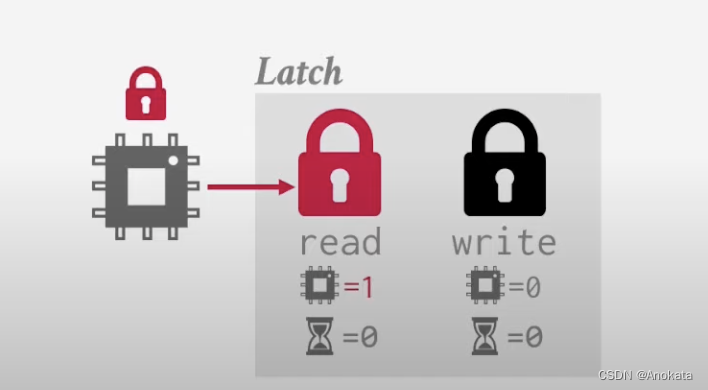
2️⃣ 现在又来了一个来做查询的 worker ,锁存器知道自己现在正处于读模式,它可以立即对该 worker 做授权访问
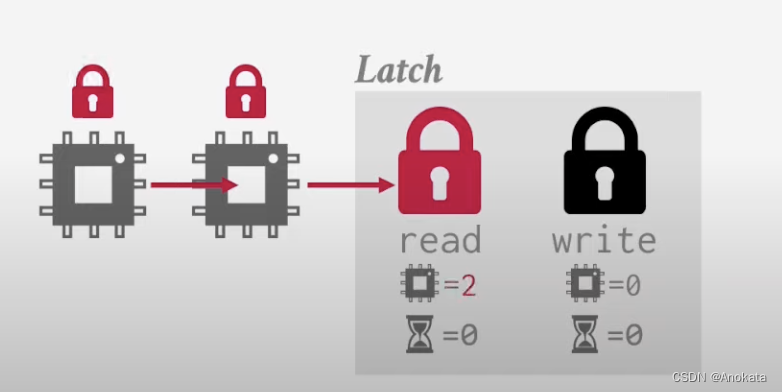
3️⃣ 现在来了一个做写入的 worker,而现在锁存器正以读模式被两个读 worker 持有着。那么它就需要挂起,然后维护一个内部优先级队列,以便跟踪哪些线程正在等待它
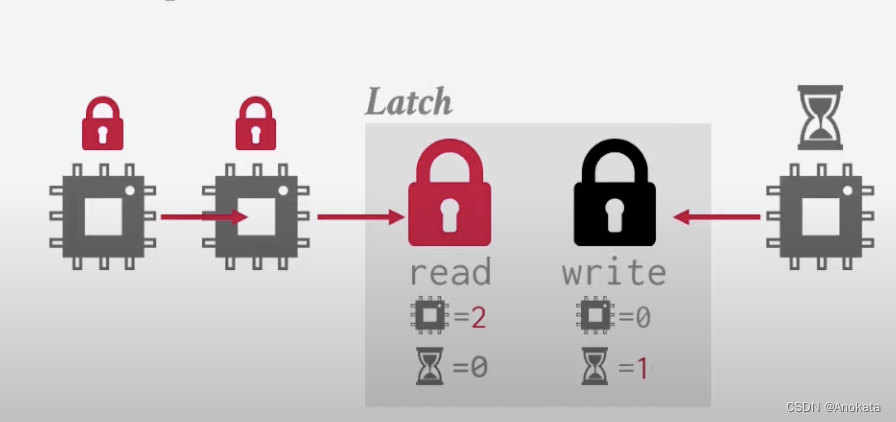
4️⃣ 然后又来了一个查询 workder,虽然目前锁存器处于读模式,按道理我可以立即授权访问,但是基于我们的优先级,我们知道有一个其他线程正在等待,因此也只能进入等待
2 Hash Table Latching
由于线程访问数据结构的方式有限,因此易于支持并发访问。
- 所有线程都朝同一方向移动(比如在现行探测哈希中,访问元素都是从上往下的扫描),并且一次仅访问单个页/槽。
- 不可能出现死锁,因为打架都是从上到下访问,没有任何线程可以从下往上访问
要调整表的大小,请在整个表上(例如,在 header page 中)采用全局写锁存器【write latch】。
方法1 Page Latches
- 每个页面都有自己的读写锁存器,可以保护其全部内容。
- 线程在访问页面之前获取读或写锁存器
更小的空间占用,但是并发低。
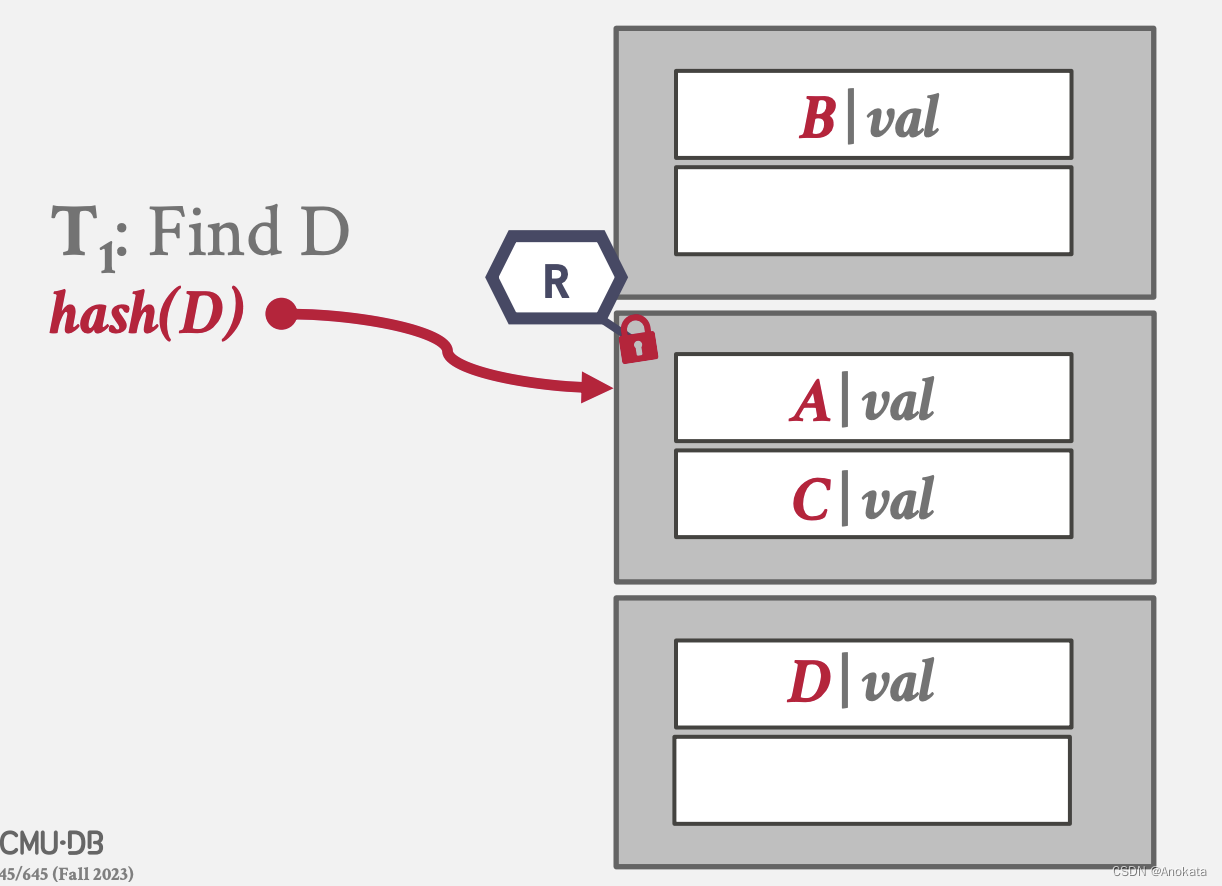
栗子
1️⃣ 假设现在有这样一个哈希表,我们打算查找元素 D ,我们根据哈希结果找到对应的位置,我们获取整个页上的一个读锁存器【R】,然后就是查找我们想要的元素 D
2️⃣ 此时其他线程想要插入元素 E ,根据哈希计算得出相同的地址,但是该页面正以读模式被其他线程锁存, 它无法与写操作兼容,因此该线程挂起,基于锁存器的实现,它可能在用户空间中自旋,或者在内核空间等待调度。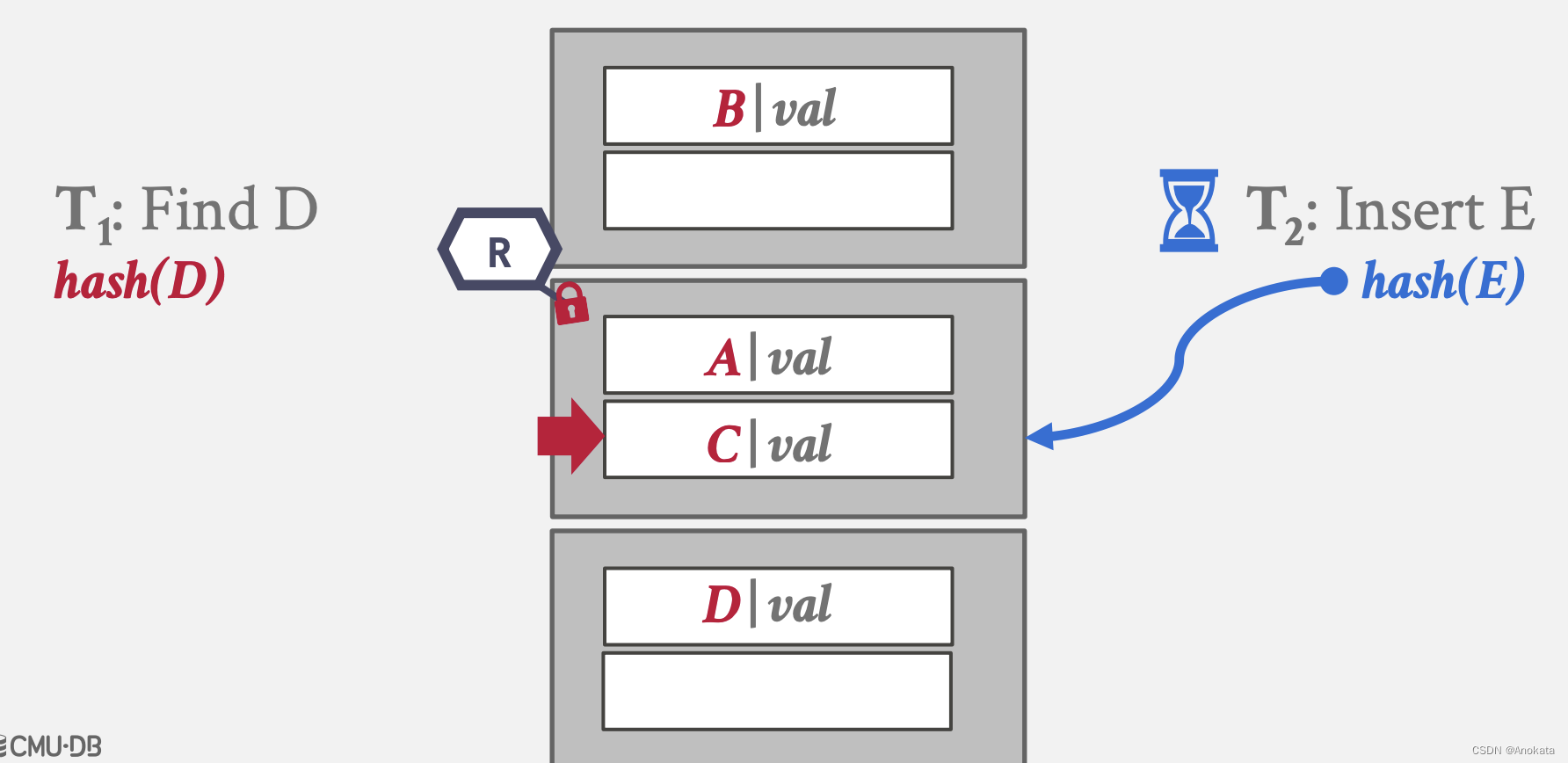
3️⃣ 而此时,读线程向下扫描,发现数据不在该页上,它需要跳转到下一页上,而它此时还持有着该页的读锁存器。
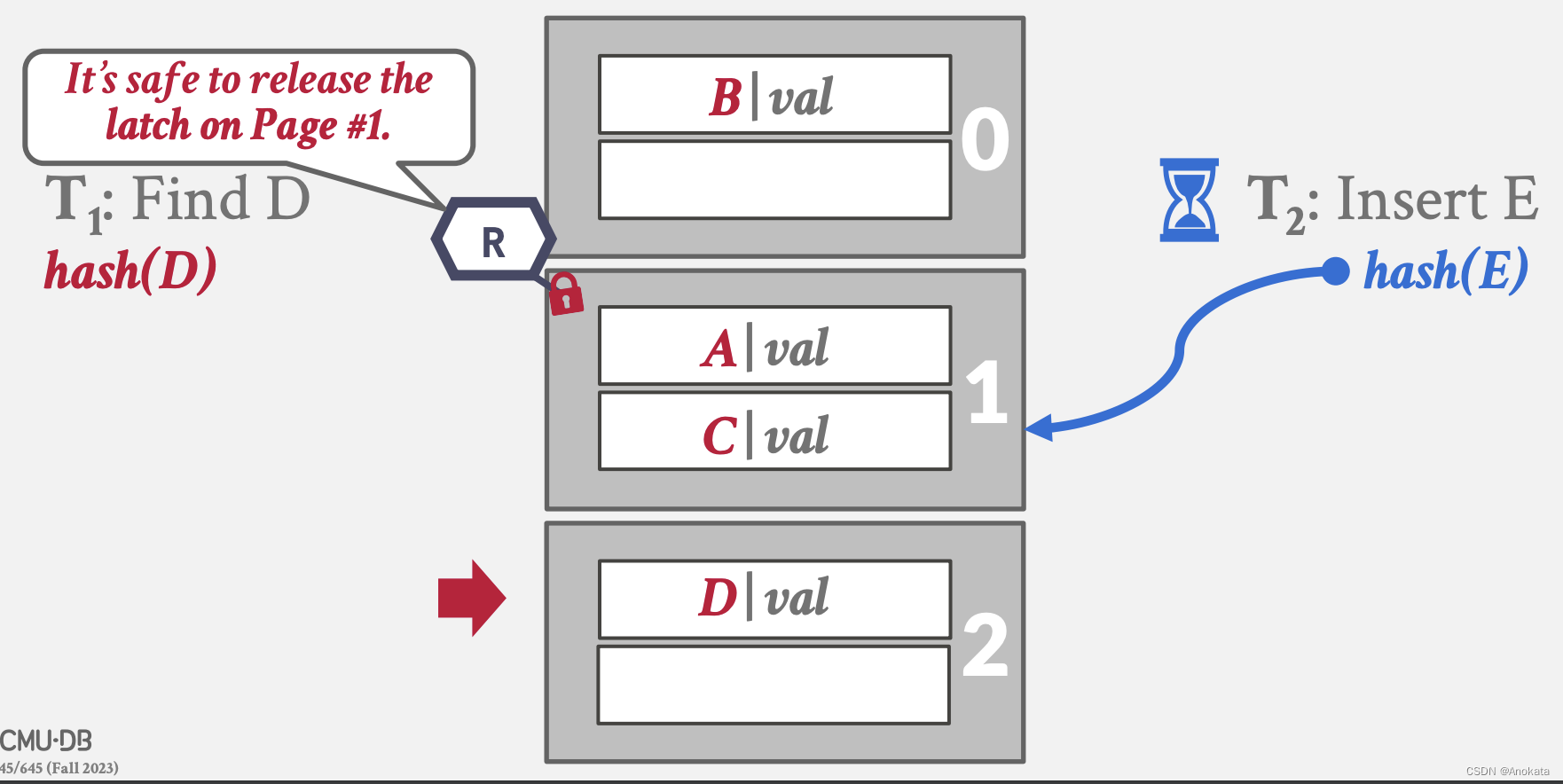
4️⃣ 现在,读线程可以释放页1的读锁存器,获取页2的读锁存器
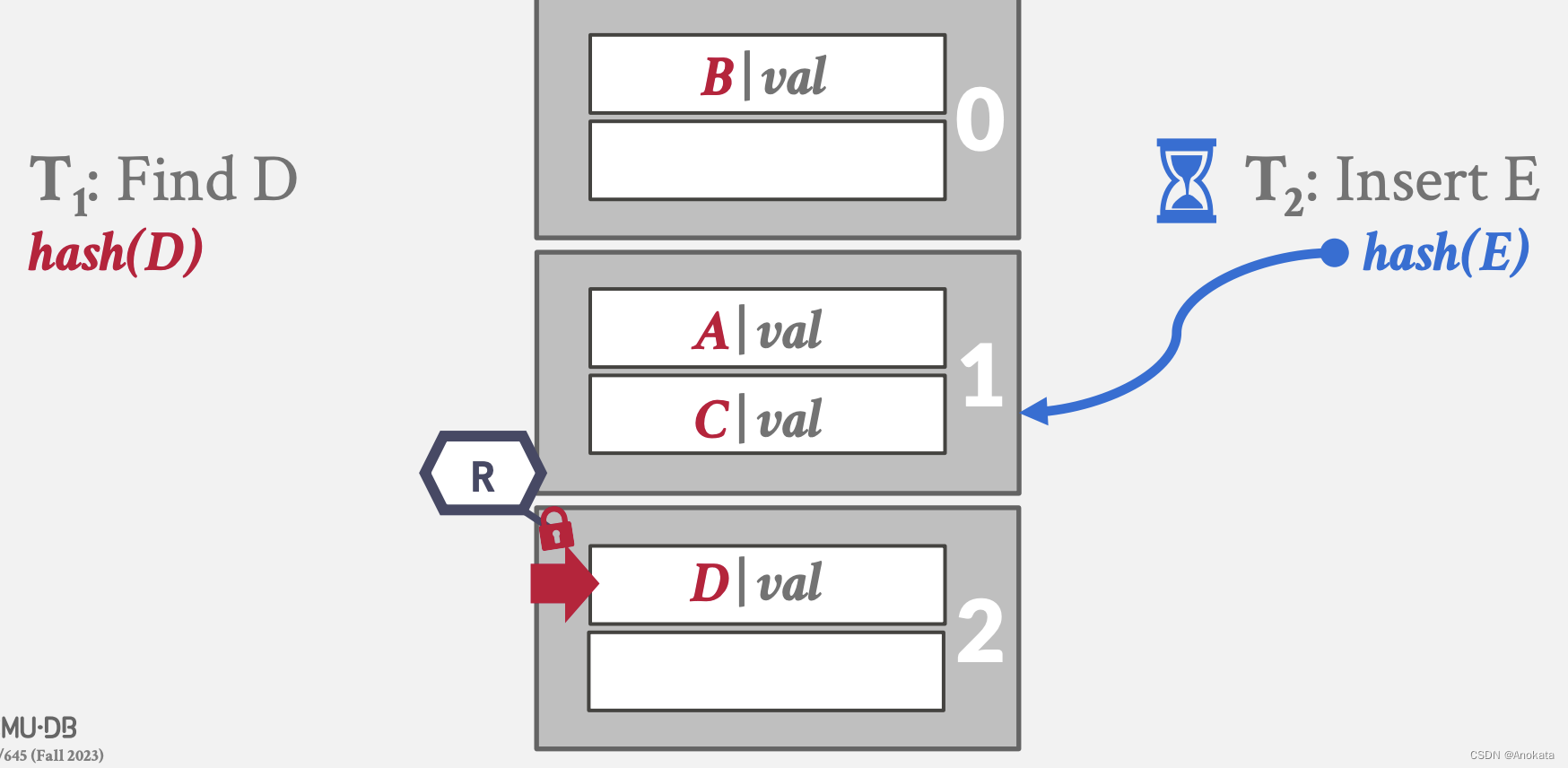
5️⃣ 而写线程也可以获取页1的写锁存器了

6️⃣ 很快写线程也意识到页1没有空间了,转而获取页2的写锁存器,由于读线程持有页2的读锁存器,因此不得不挂起
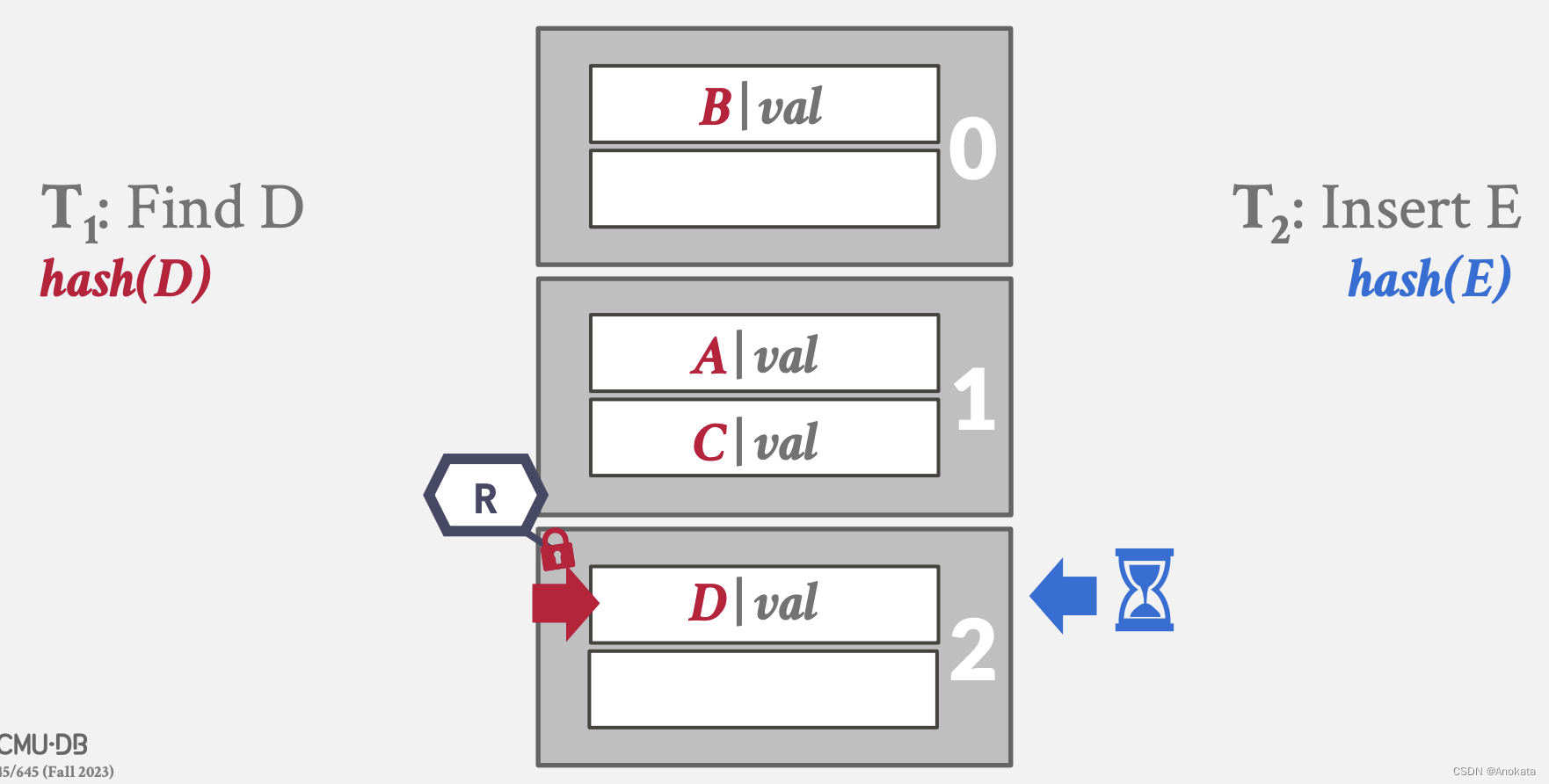
7️⃣ 等读线程释放了页2的读锁存器后,写线程会立即获取页2上的写锁存器
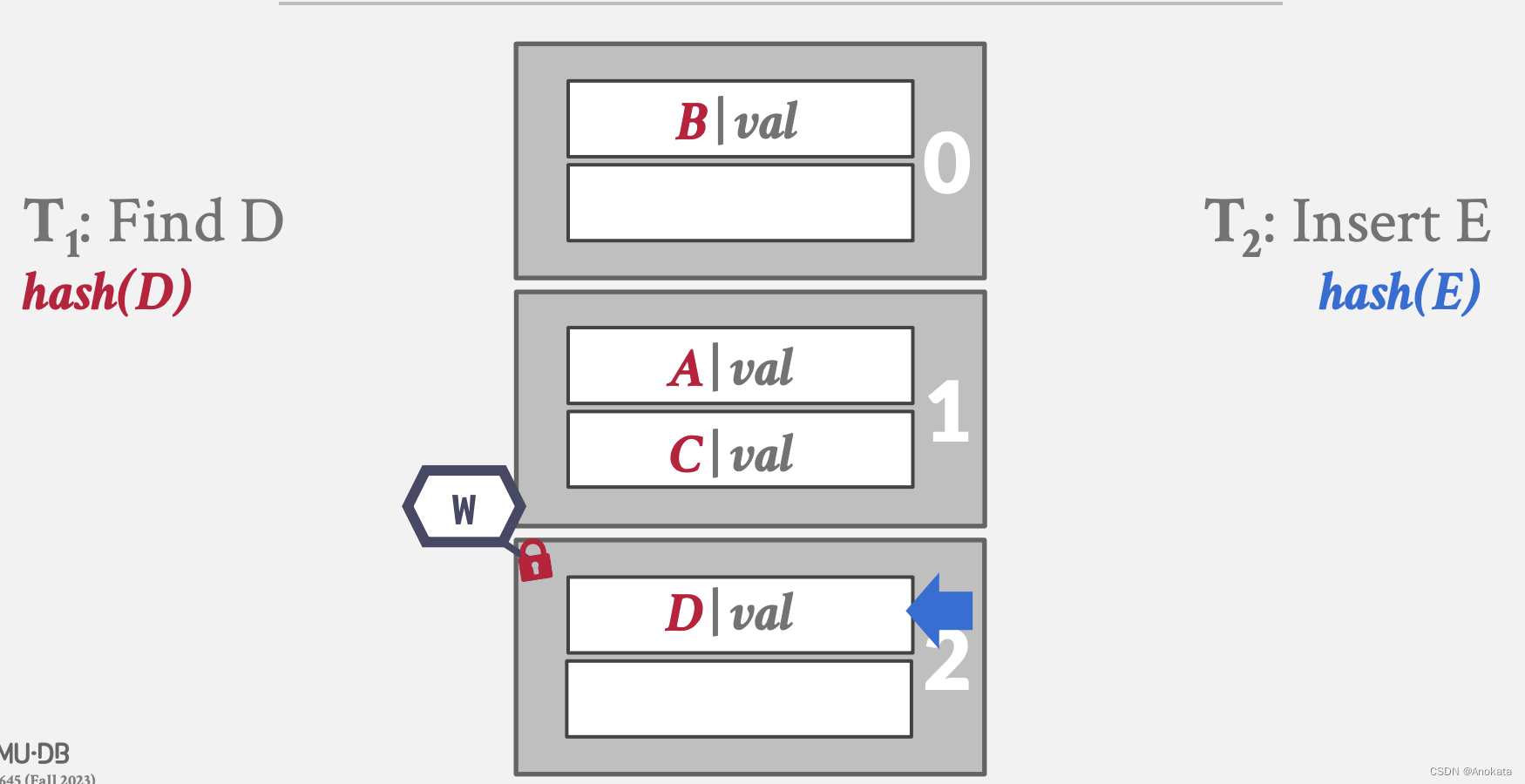
8️⃣ 最终写线程插入元素
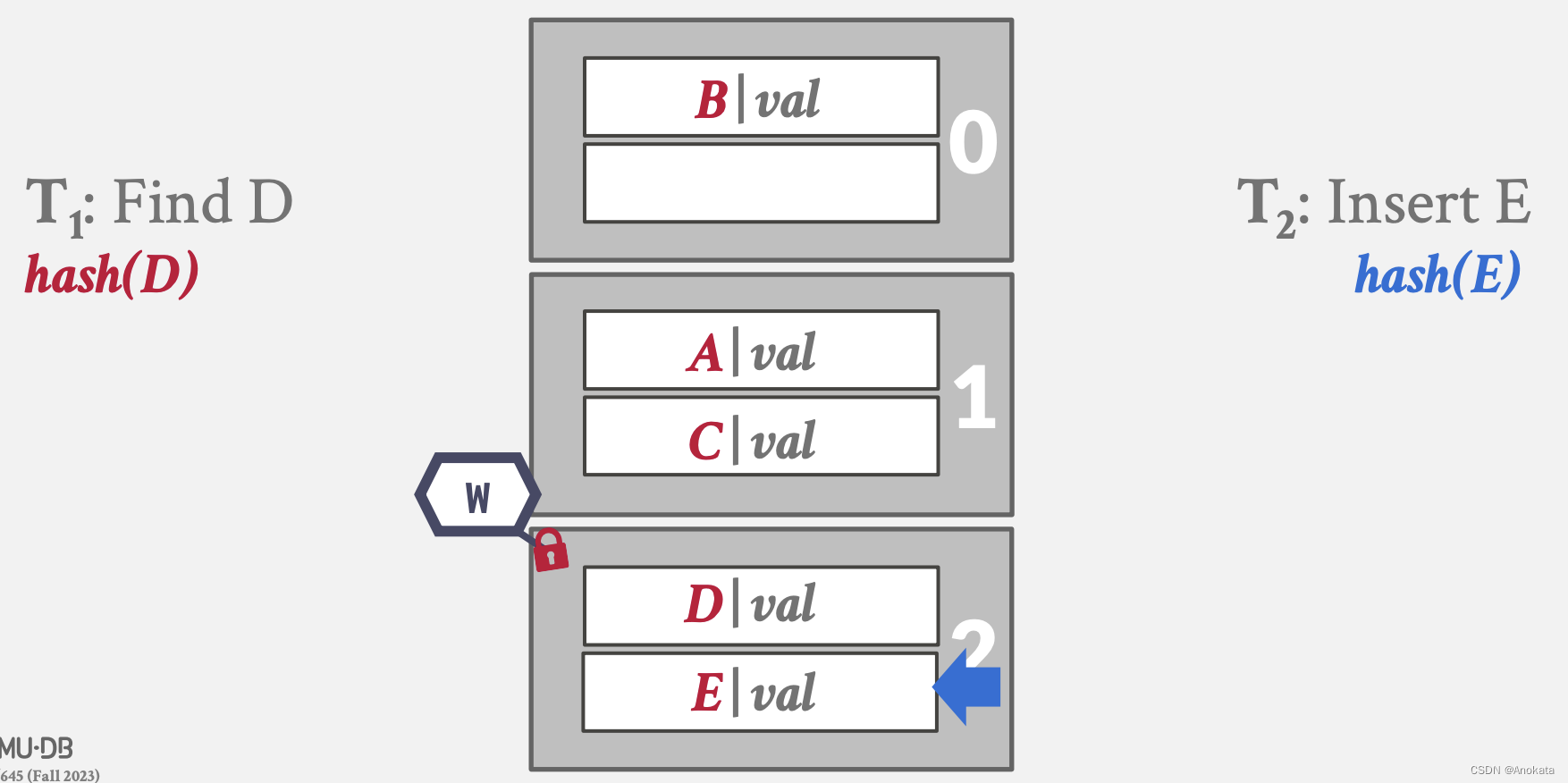
方法2 Slot Latches
- 每个插槽都有自己的锁存器。
- 可以使用单模式锁存器来减少元数据和计算开销
更细粒度的控制,但是也相应的记录更多元数据。
栗子:
1️⃣ 读线程查询元素 D ,而写线程写入元素 E ,假设 D 哈希完,是在元素 A 的位置,
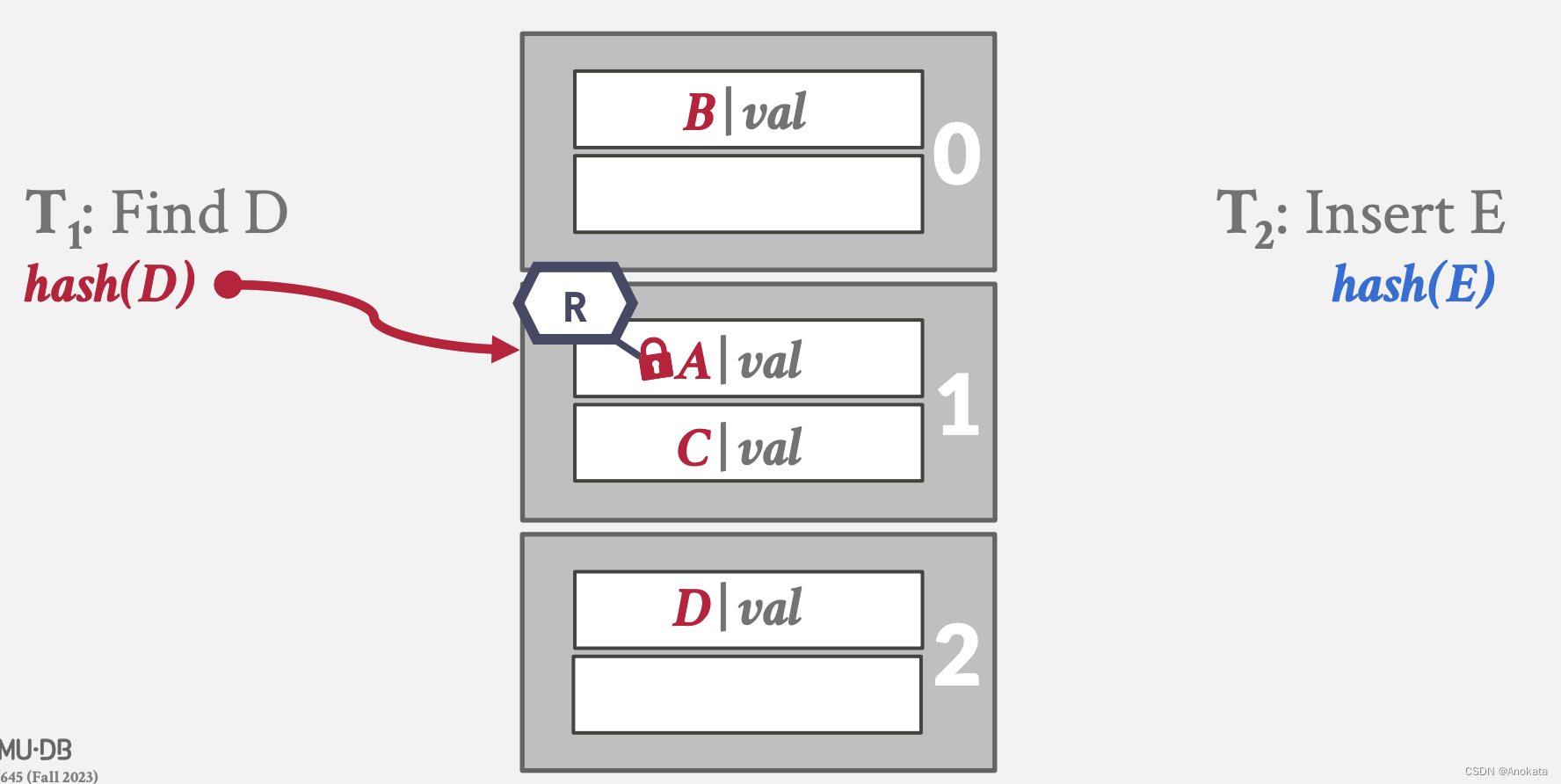
2️⃣ 读线程获取插槽 A 上的读锁,而写线程写入元素 E ,而元素E哈希完是在元素 C 的位置
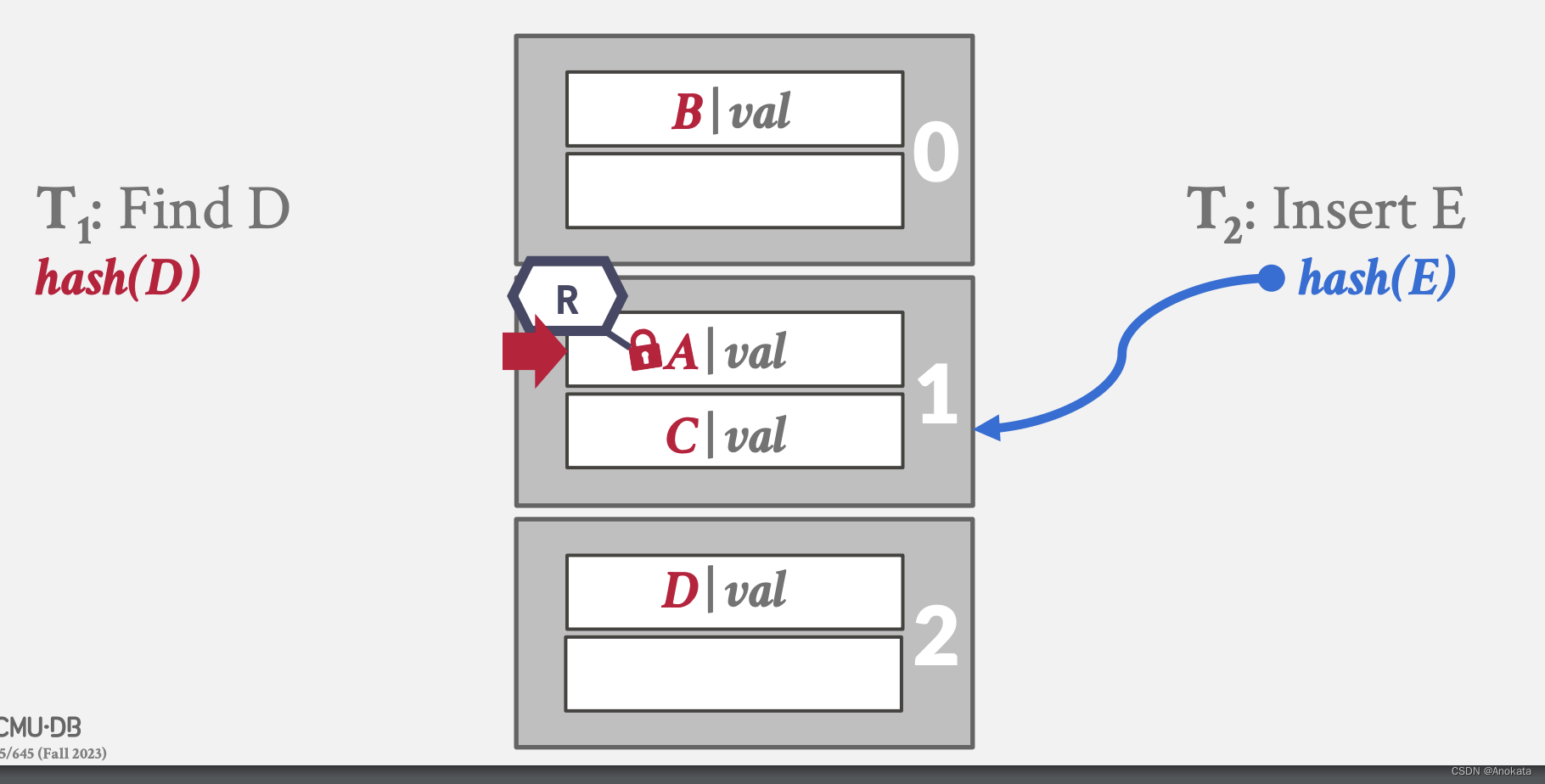
3️⃣ 写线程获取插槽 C 上写锁
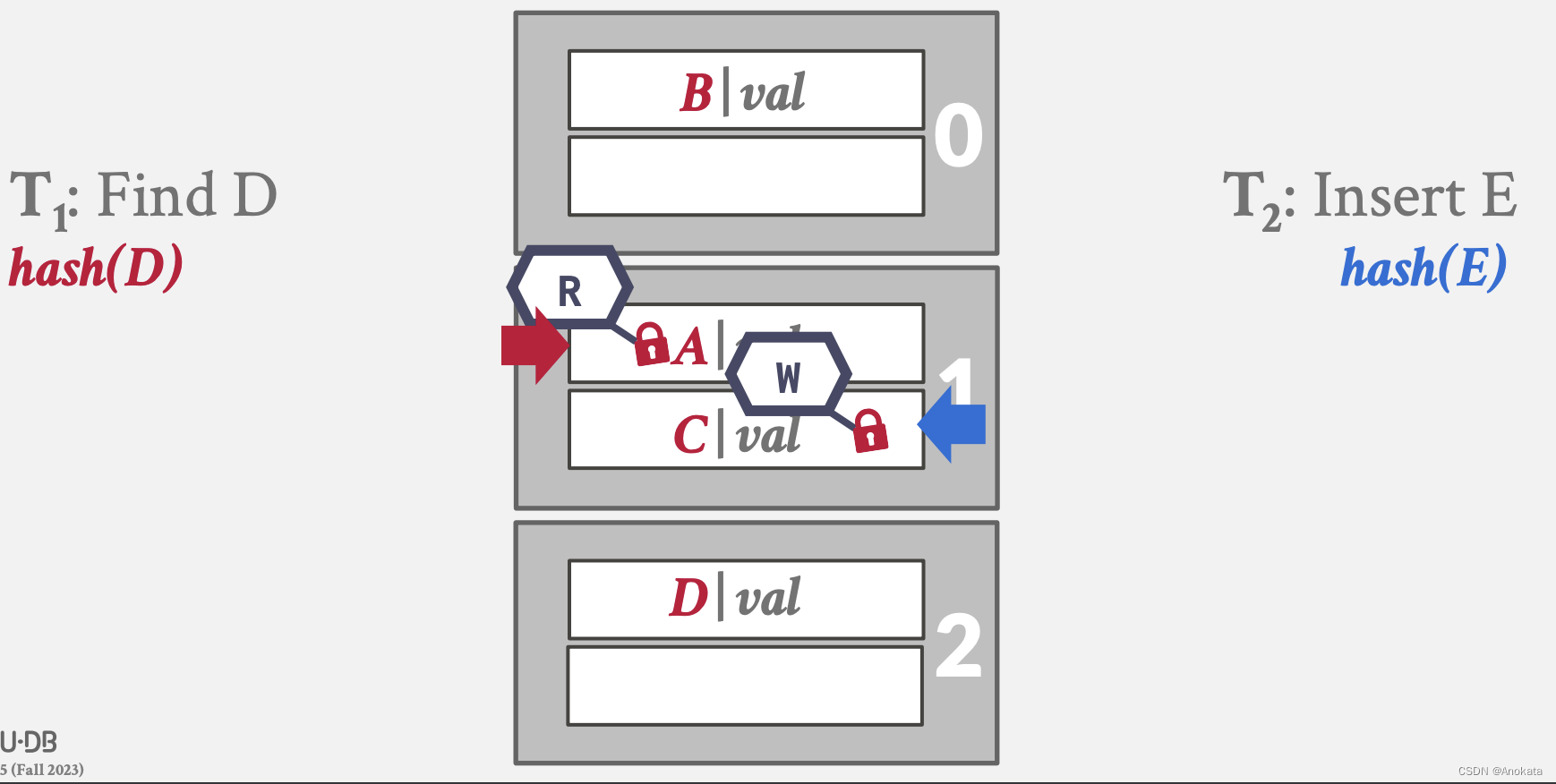
4️⃣ 读锁存器发现插槽 A 处不是自己期望的元素,则释放读插槽锁存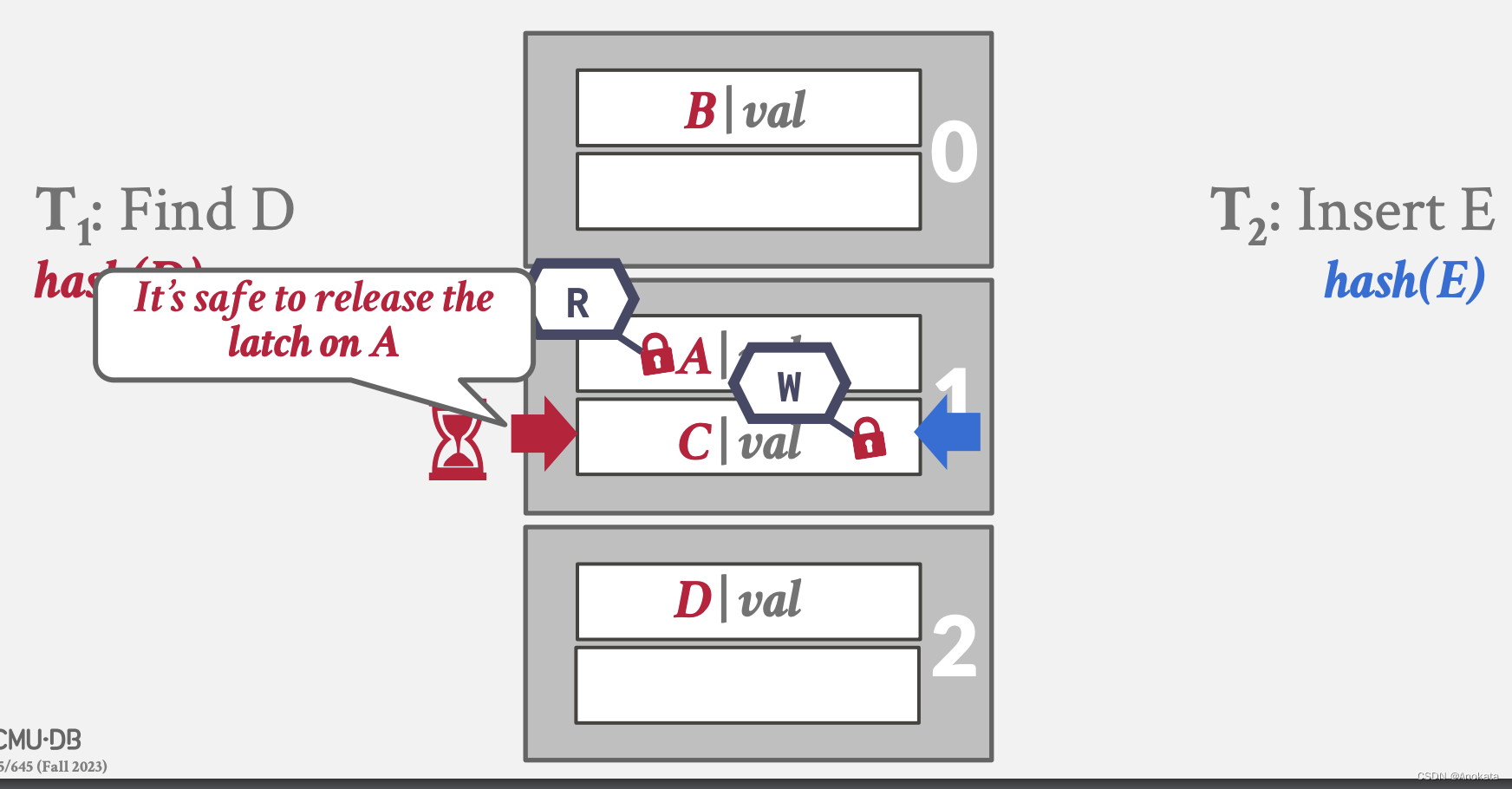
5️⃣ 而插槽 C 上有其他线程正在持有锁存器,因此读线程需要等待
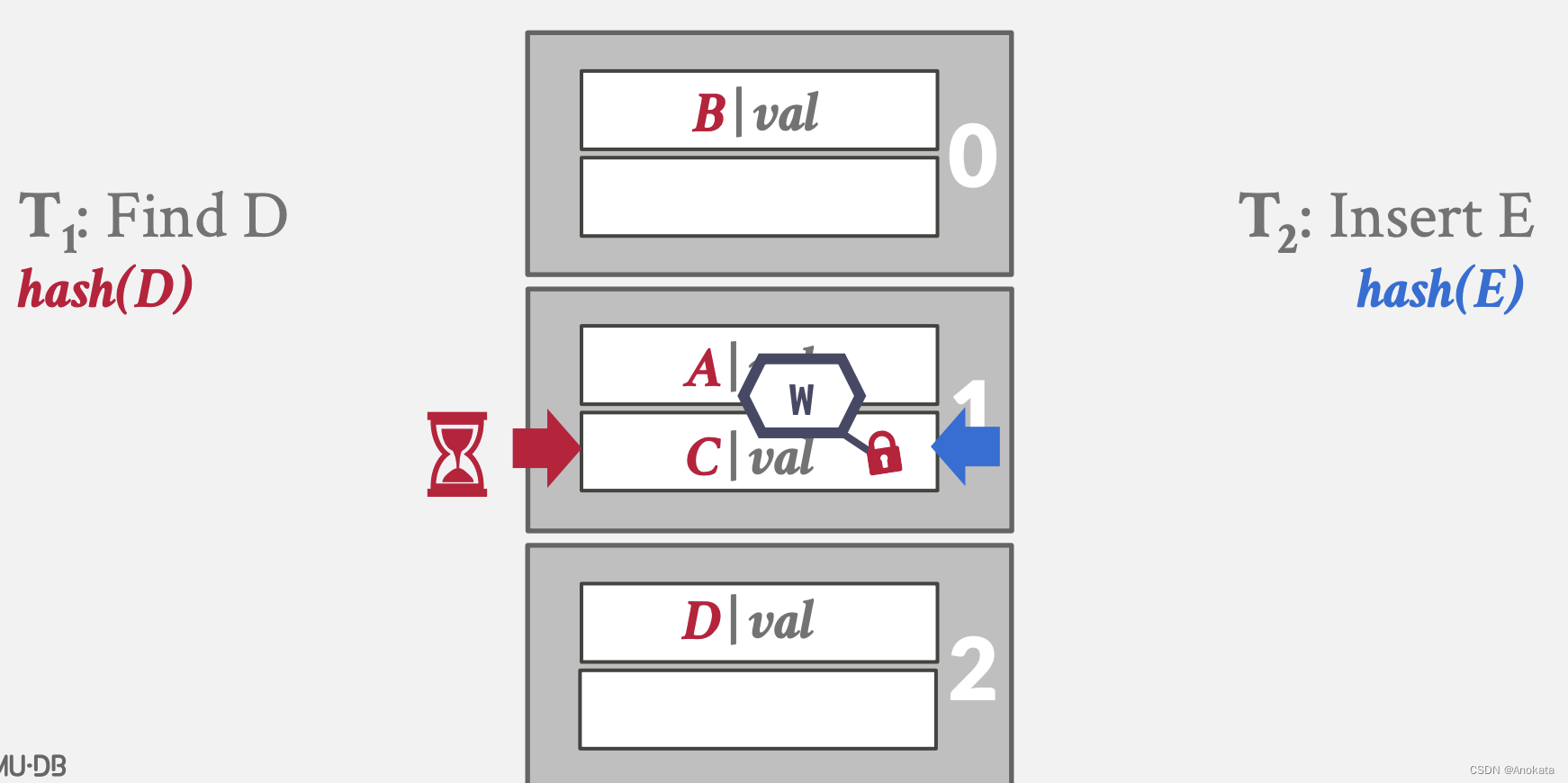
6️⃣ 循环往复后,各自线程实现自己的目的了
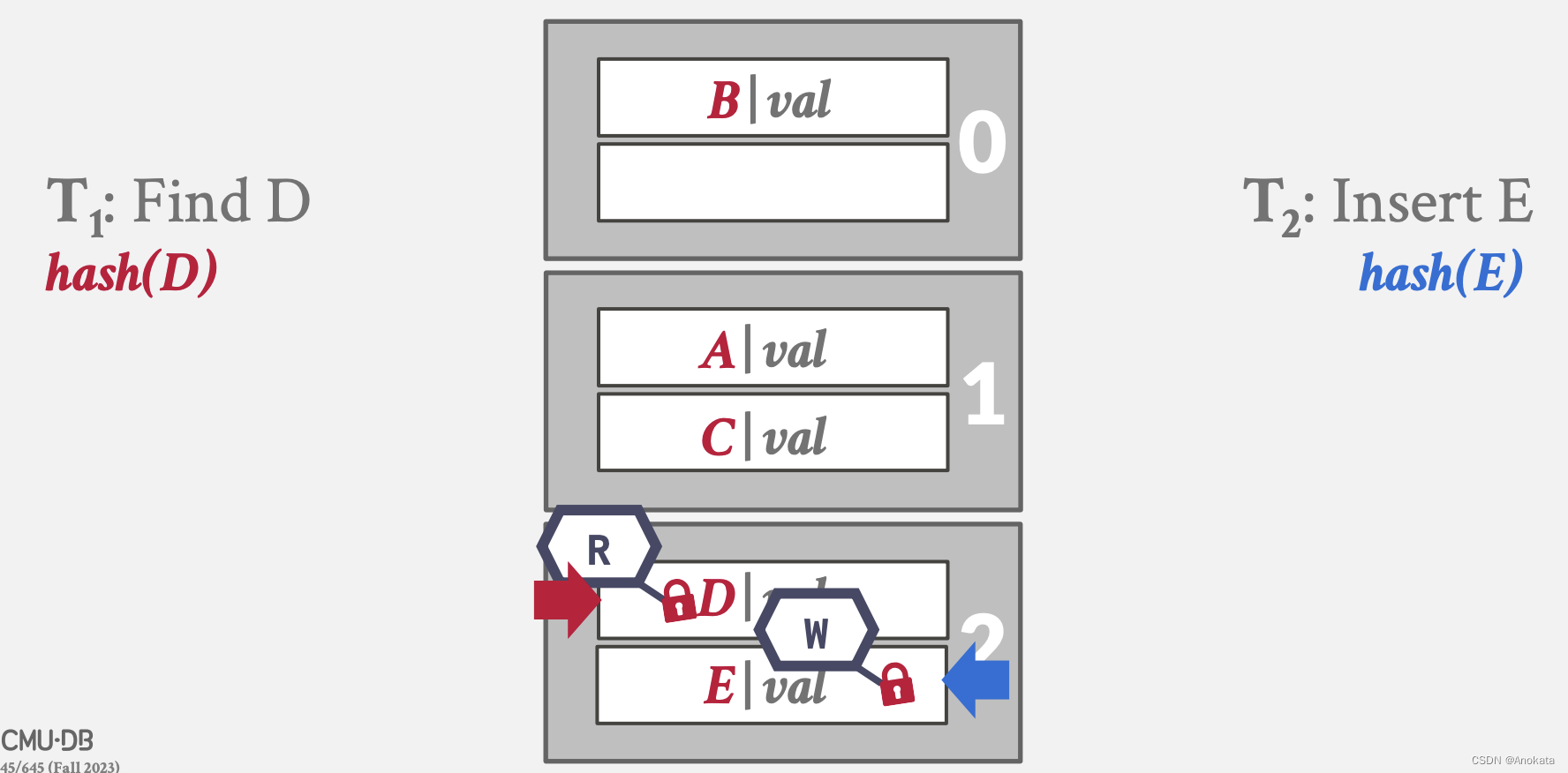
3 B+Tree Latching
3.1 latch coupling schema
我们希望允许多个线程同时读取和更新 B+Tree。
但是,我们需要防范两类问题:
- 多个线程同时尝试修改节点的内容。
- 一个线程遍历树,而另一个线程拆分/合并节点。
在哈希表中,起码在线性探针哈希中,它的页【Pages】是固定的,数据结构的组织是固定的。而 b+ 树是自组织【Slef-Organization】/自平衡【Slef-Balance】,在插入和删除时,他会自己开始重新组织,所以我需要确保当我通过拆分或合并进行重新组织时,我必须确保数据结构是正确的。
栗子:
1️⃣ 我们现在有一个线程,他打算删除元素 44 ,我们遍历节点,ABDI,最终抵达叶节点,并删除元素
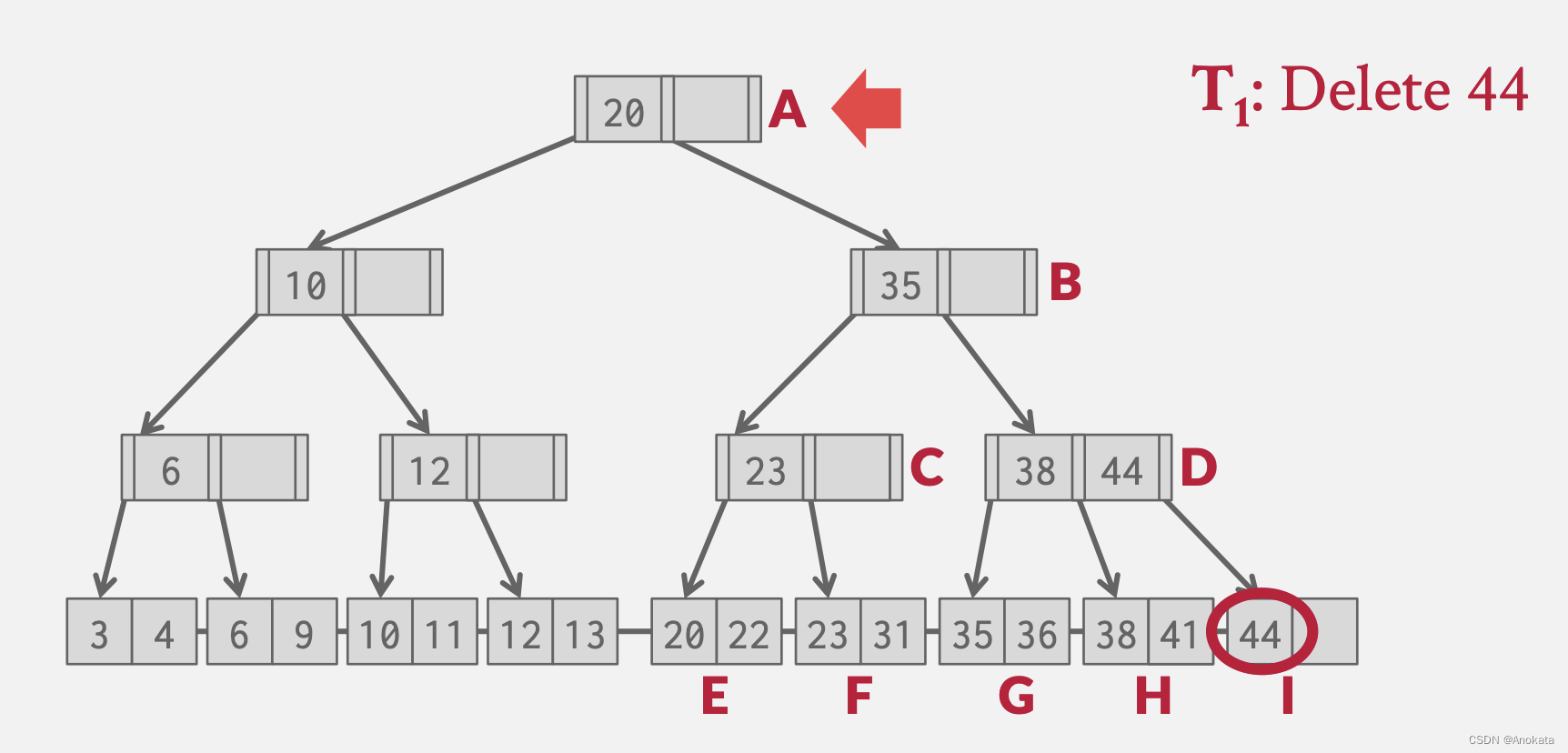
2️⃣ 但是这时候,叶节点不再满足半满,我们需要重新平衡【rebalance】 ,即一个合并操作,我可以从兄弟节点窃取一个元素,比如 H 节点的 元素41,但是在做之前,我的线程因为其他原因无法继续执行,可能是 OS 发生了中断等,因此当前线程被挂起。

3️⃣ 这时候线程 2 进来了,它查询元素41,它开始遍历并找打了 D 叶节点,根据指示,它应该前往 H 节点,还没来得及到 H 节点上,它也被挂起了。
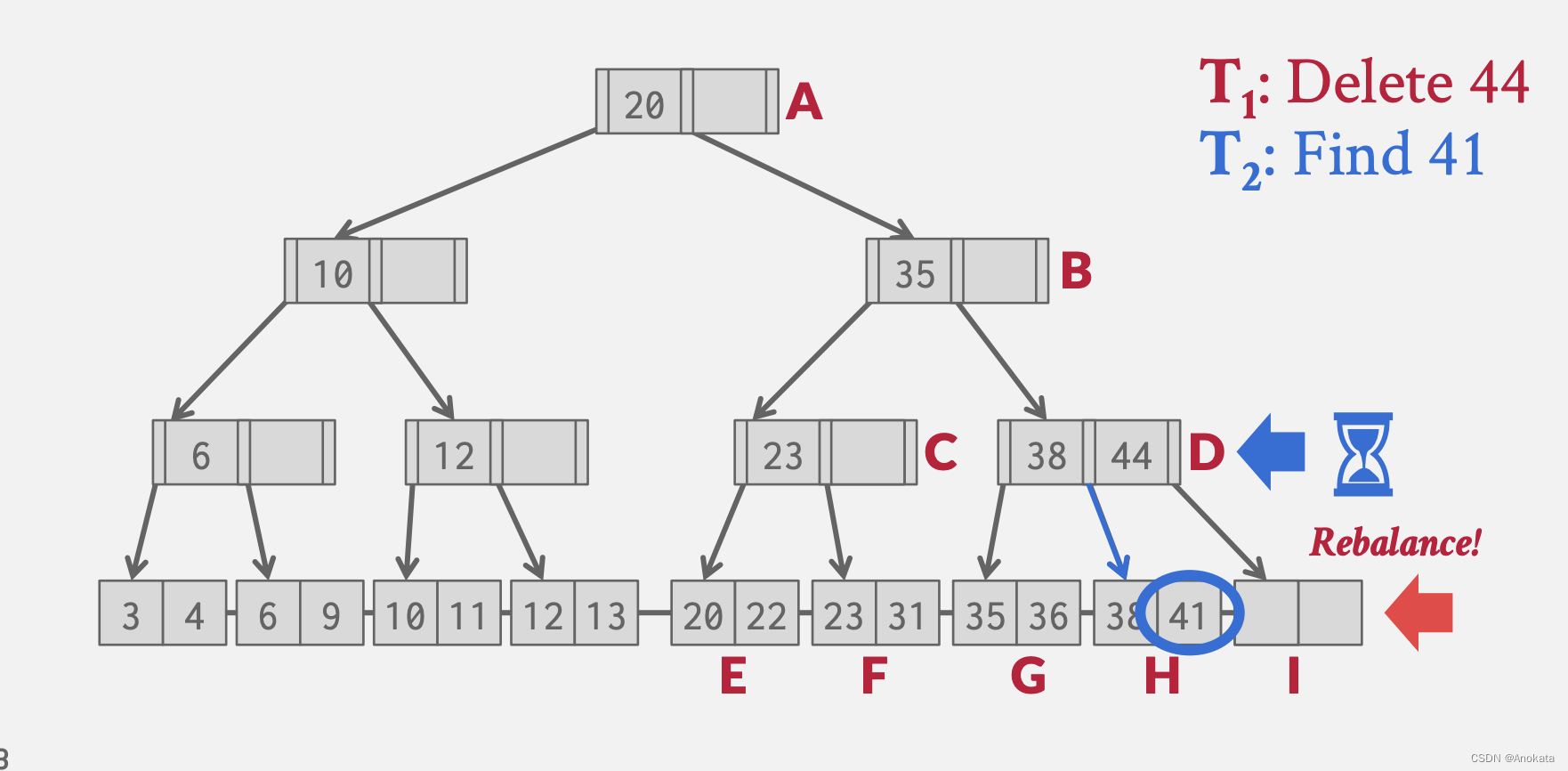
4️⃣ 线程1唤醒,它将元素41窃取到节点I中,做完了重新平衡
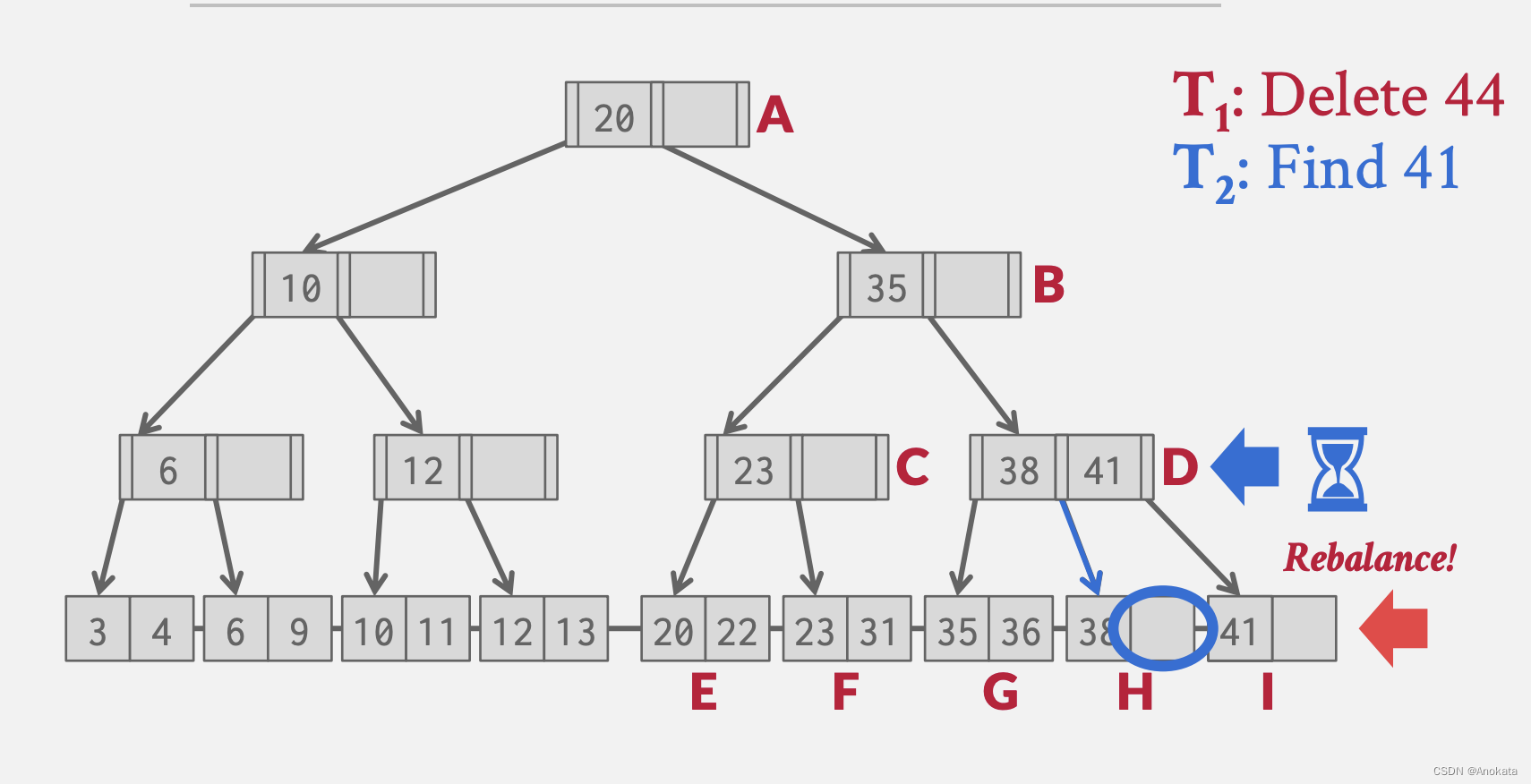
5️⃣ 线程2唤醒,它在H节点上无法找打到元素41
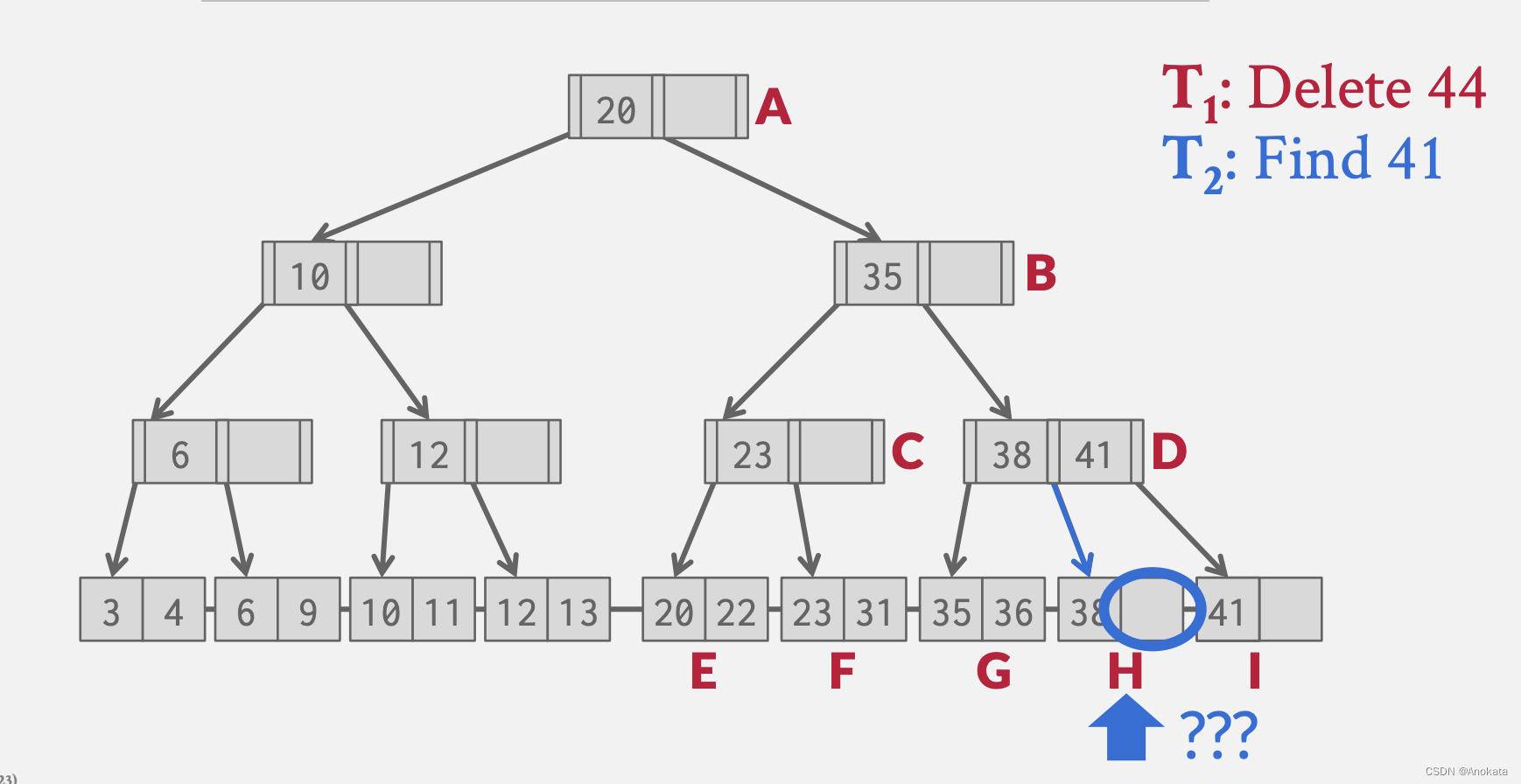
在这里,我们就需要锁存器来保护这些东西。这也被称为锁存耦合【Latch Coupling】 ,它的基本思想是,在我们遍历树时,我们应该获取哪些锁存器,以及什么时候可以释放上面的锁存器。
允许多个线程同时访问/修改 B+Tree 的协议。
- 获取父级的锁存器
- 根据计算,我们分析出取哪个子节点后,我们就需要获取子级的锁存器
- 如果节点“安全”的话,则释放父级的锁存器
"安全"节点是指在更新时不会分裂【Split】或合并【Merge】的节点。
- 当操作是插入时,则判断节点是否满的
- 当操作是删除时,则判断节点是否超过半满
FInd:从根节点开始,向下遍历树:
- 获得子节点的 R 锁
- 然后释放父节点的锁
- 重复,直到到达叶节点
Insert/Delete:从根节点开始向下,根据需要获取 W 锁。 一旦子节点被锁住,检查是否安全:
- 如果子节点安全,则释放祖先节点的所有锁
- 如果子节点可能不安全,则不释放父节点的 W 锁,直到能准确判断出是否安全后为止
栗子:略
3.2 更好的锁存算法-乐观锁存方案
在所有更新栗子中,在 B+Tree 上执行的第一步是什么?
答:每次在根节点上取写锁存器成为高并发的瓶颈!!每次写操作,都会获取根节点的写锁存器,这与读操作形成了冲突。

对 B+Tree 的大多数修改不需要拆分或合并。
我们假设不会出现拆分【Split】/合并【Merge】,在基于锁存耦合方案中,我们向下顺序获取写锁存器,但是现在我们将使用读锁存器【read latches】,直到我们到达叶节点上一级的节点后:
- 如果拆分【Split】/合并【Merge】的假设成立,然后以写模式获取叶节点,然后就可以继续你的操作了
- 但是如果之前的假设不成立,那么就需要用悲观算法【pessimistic algorithm】重复一次遍历
Search:与上一节一致
Insert/Delete:
- 像查询那样设置锁存器,到达叶节点,然后在叶节点上设置 W 锁存器。
- 如果叶节点不安全,则释放所有锁存器,并使用上一节中的 Insert/Delete 协议下的写锁存器再来一遍
这种方法乐观地假设只有叶节点会被修改; 如果不是,那么乐观锁遍历的一切都是浪费的。
栗子:
1️⃣ 删除元素 38 ,我们在根节点上获取读锁存器

2️⃣ 顺序向下获取读锁存器,直到到节点上一级节点
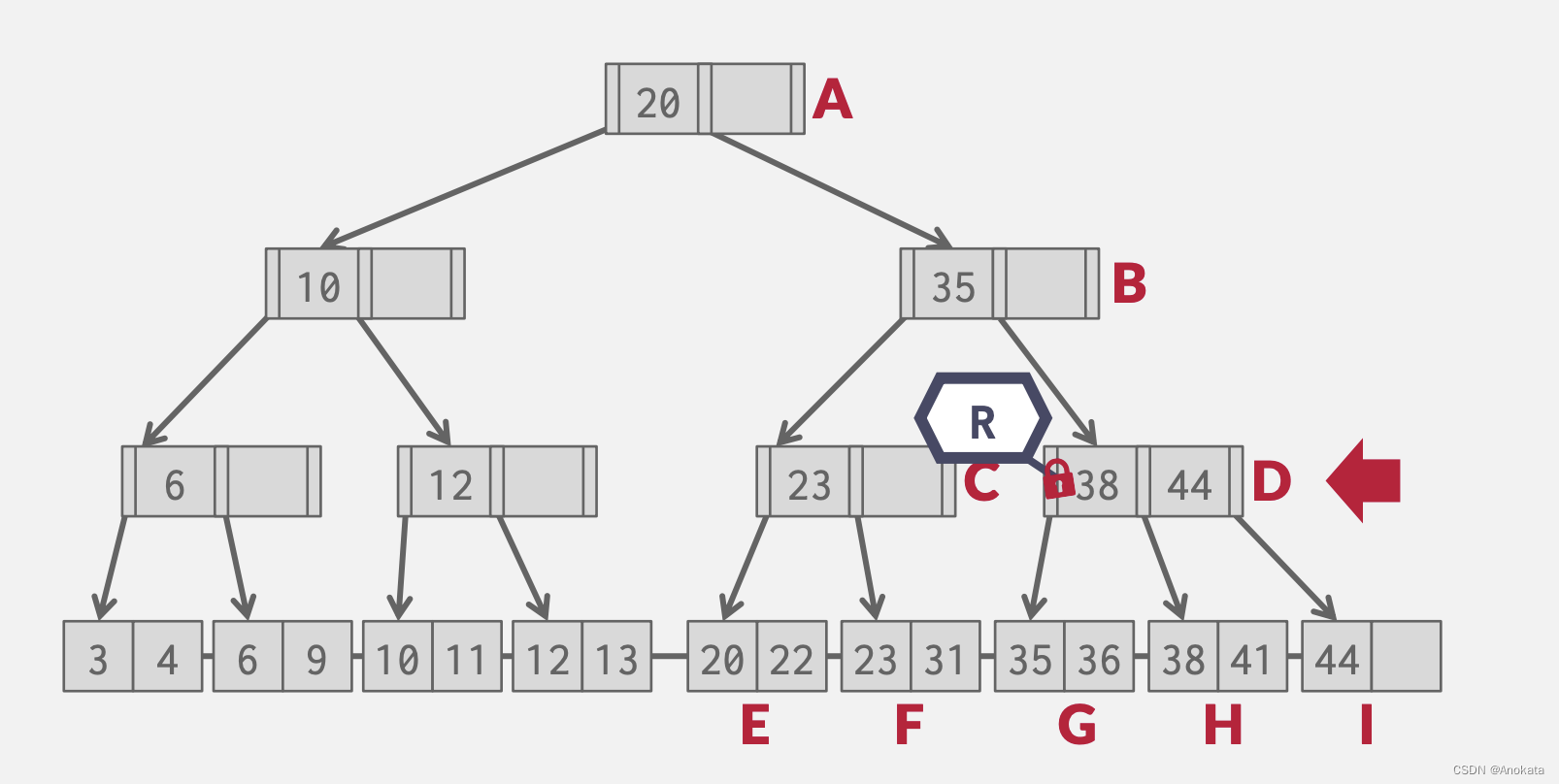
3️⃣ 我们要删除元素 38 ,我们检查到该操作是安全的,不会发生拆分,因此获取H叶姐上上读锁存器
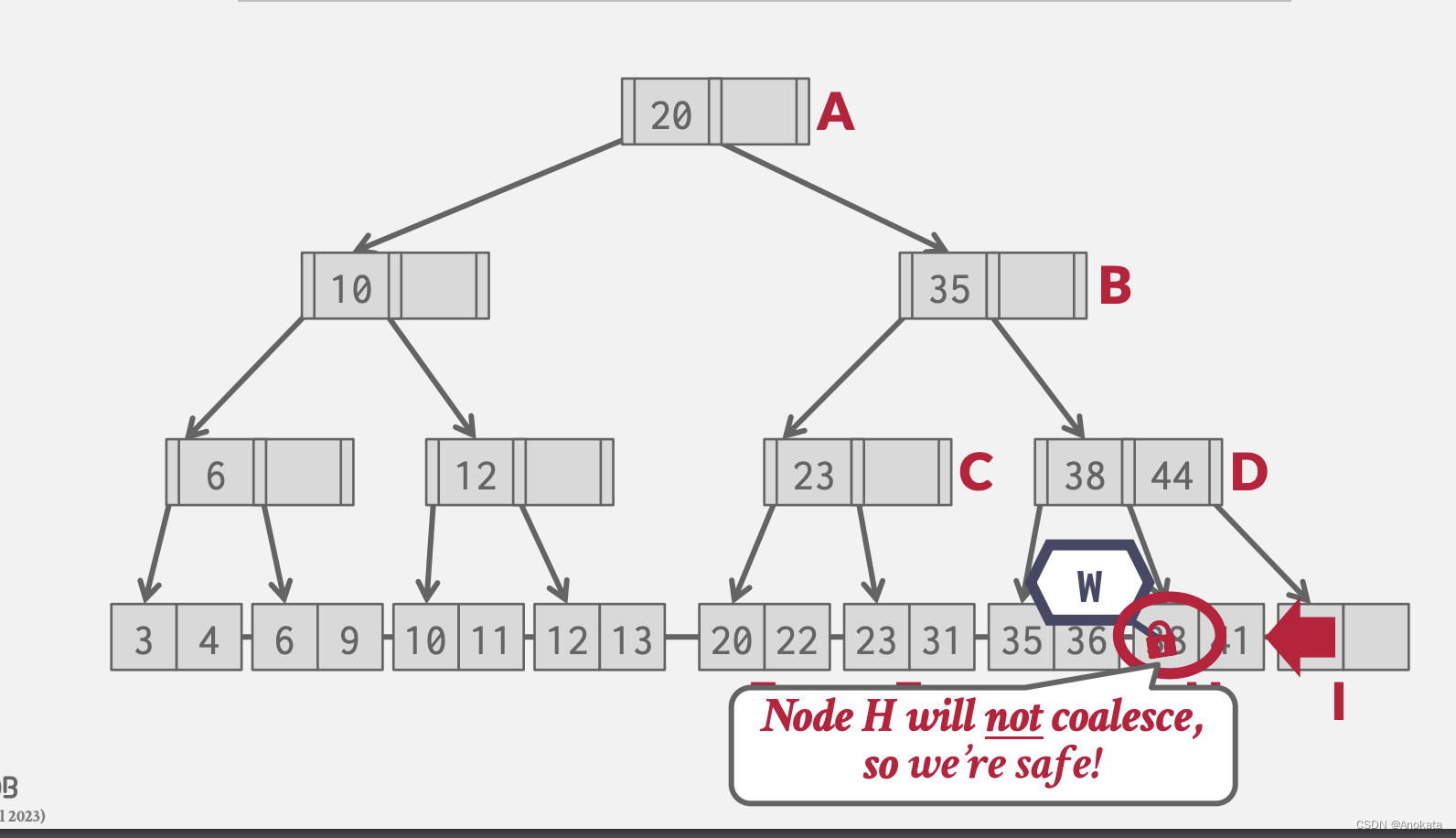
4️⃣ 我们现在要插入元素 25 ,我们继续来到叶节点,但是发现我们需要做拆分
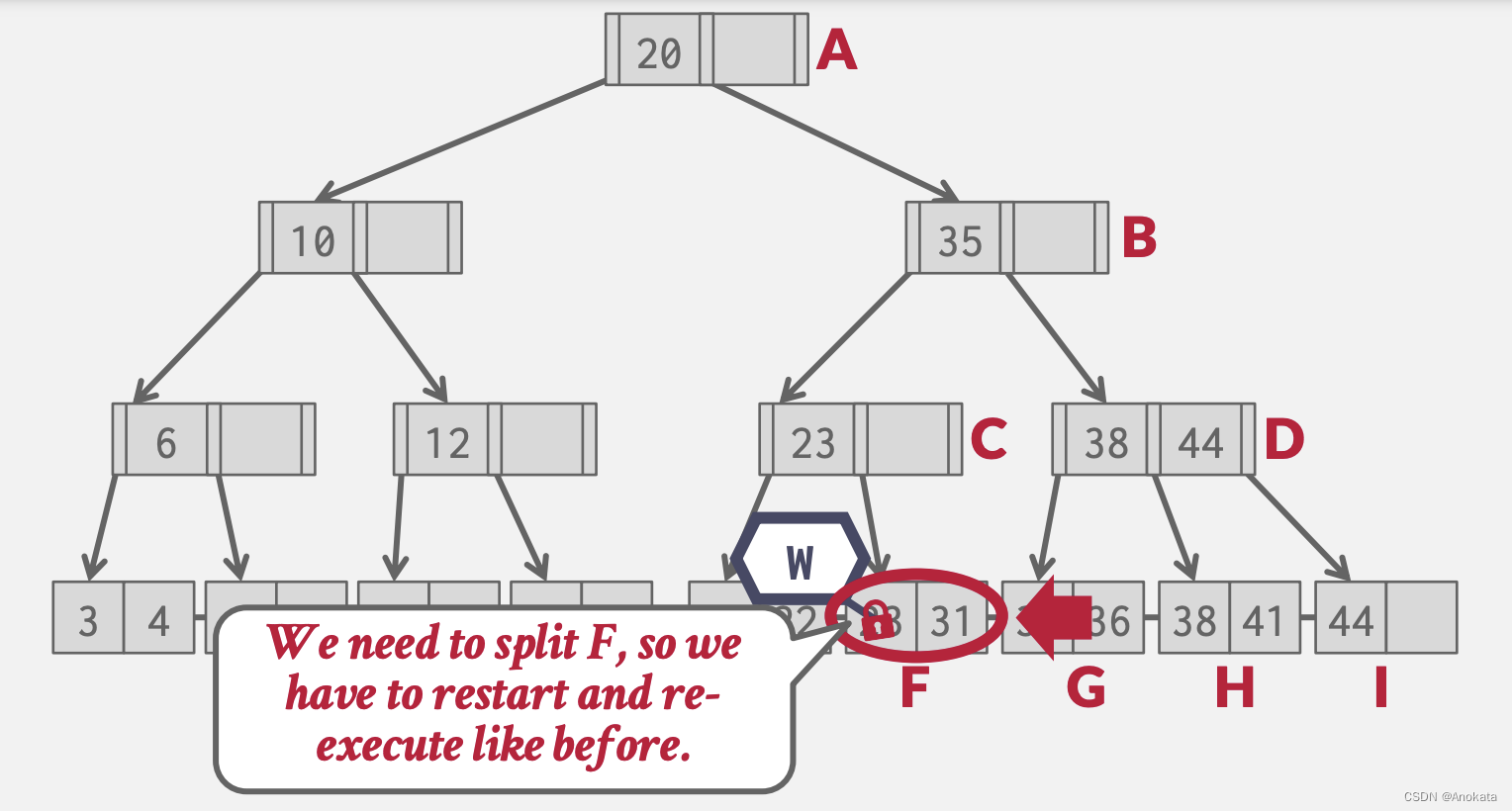
5️⃣ 我们不得不重新以悲观锁方案重复整个遍历操作。
4 Leaf Node Scan
到目前为止,所有示例中的线程都以“自上而下”的方式获取锁存器。
- 线程只能从低于其当前节点的节点获取锁存器。
- 如果所需的锁存器不可用,则线程必须等待直到它变得可用。
但是,如果线程想要从一个叶节点移动到另一个叶节点的话怎么办?
我们之前讲过,子节点是没有到父节点的指针的,这样可以避免冲突。在B+树中我们有兄弟节点,但是这时候就会出现一种场景,即两个线程互相持有对方想要的锁存器,也就是死锁。
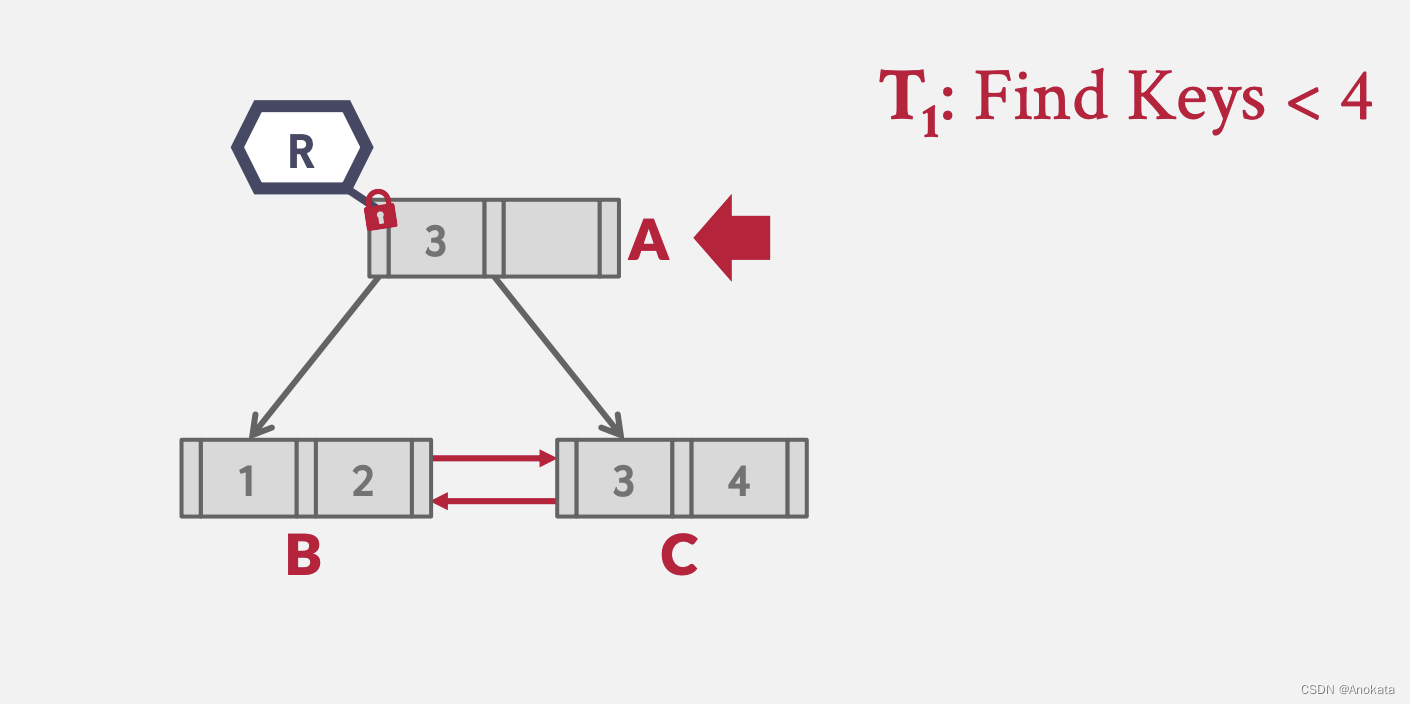
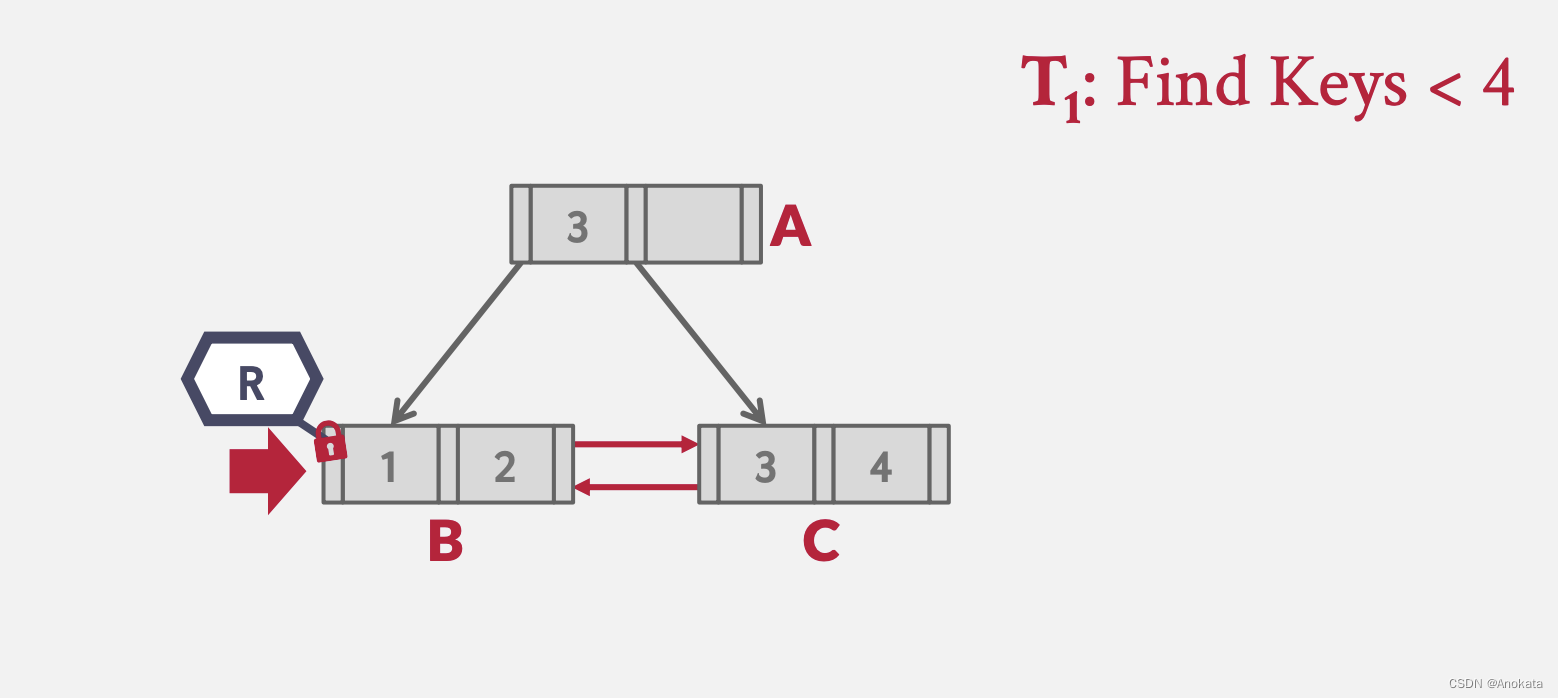
栗子 1 单线程访问:
1️⃣ 我们查询小于 4 的元素,我们从根节点获取读锁存器
2️⃣ 根据计算,我们进入叶节点 C
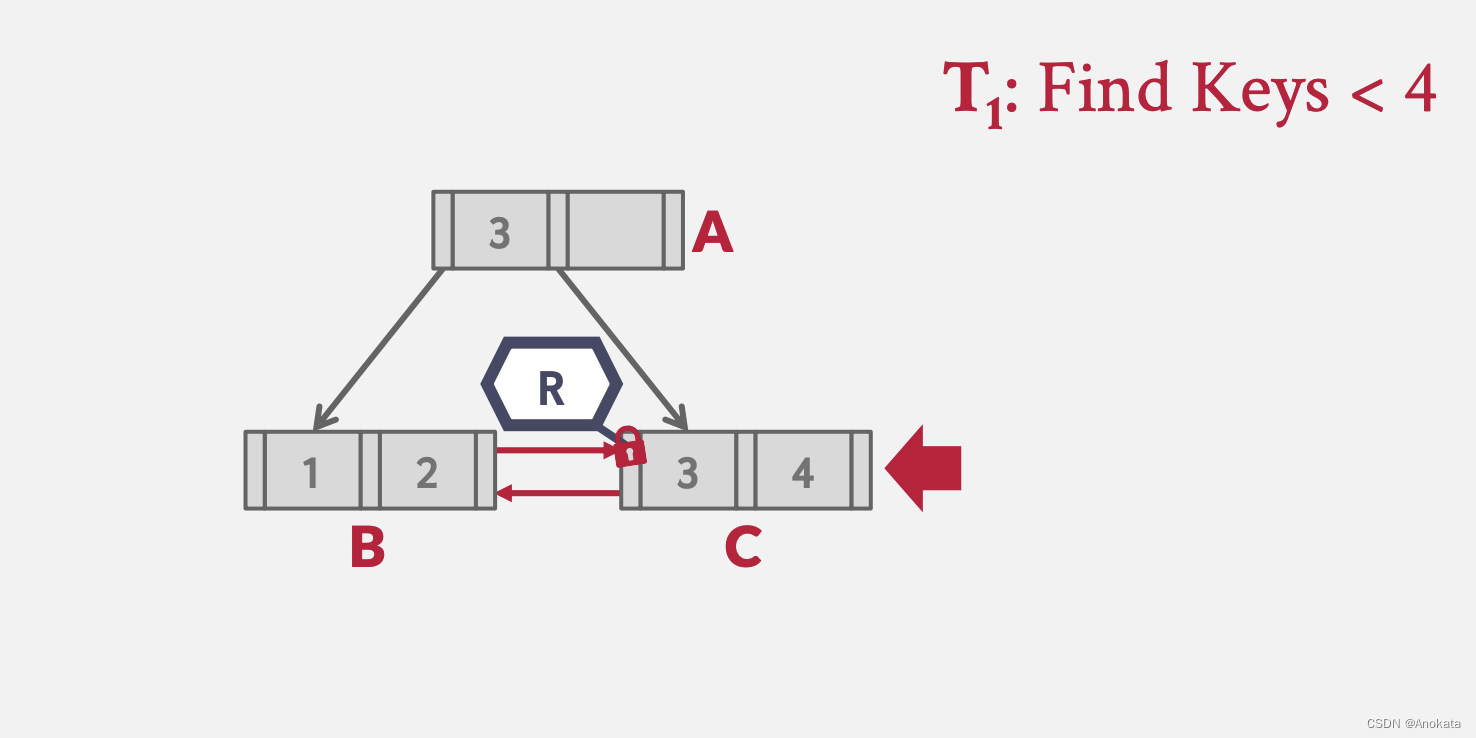
3️⃣ 为了找出小于 4 的元素,我们需要兄弟节点 B,
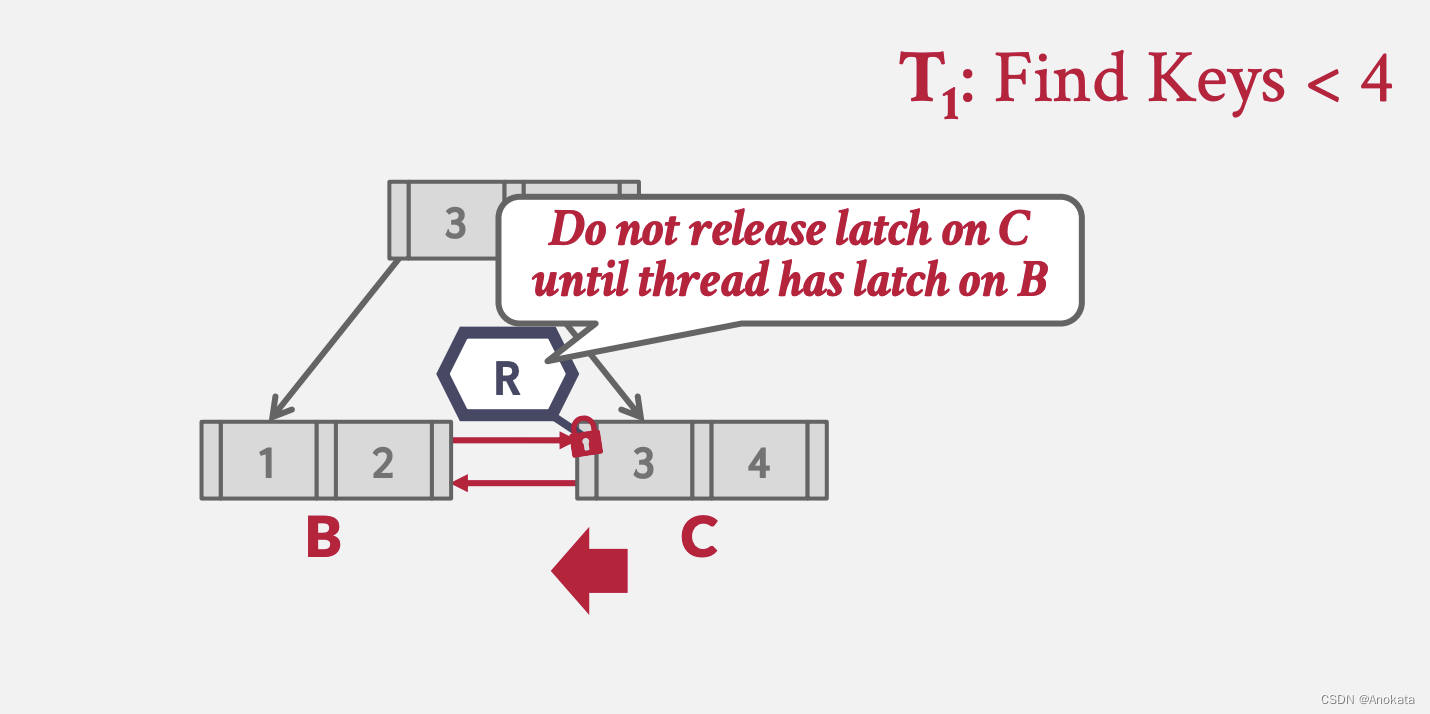
4️⃣ 当我们拿到节点 B 的锁存器后,我们即可释放 C 上的锁存器(解释这个case是让我们自己知道,在兄弟姐节点上,锁的获取与释放与层级之间的获取是一致的)
栗子 2 多线程访问:
1️⃣ 假设两个线程,一个线程查询小于 4 的元素,另一个线程查询大于 1 的元素,
 2️⃣ 为了实现查询目标,它们想要穿过彼此,而它们持有的两个锁存器是可交换的,因此他们都做了他们需要做的事情
2️⃣ 为了实现查询目标,它们想要穿过彼此,而它们持有的两个锁存器是可交换的,因此他们都做了他们需要做的事情
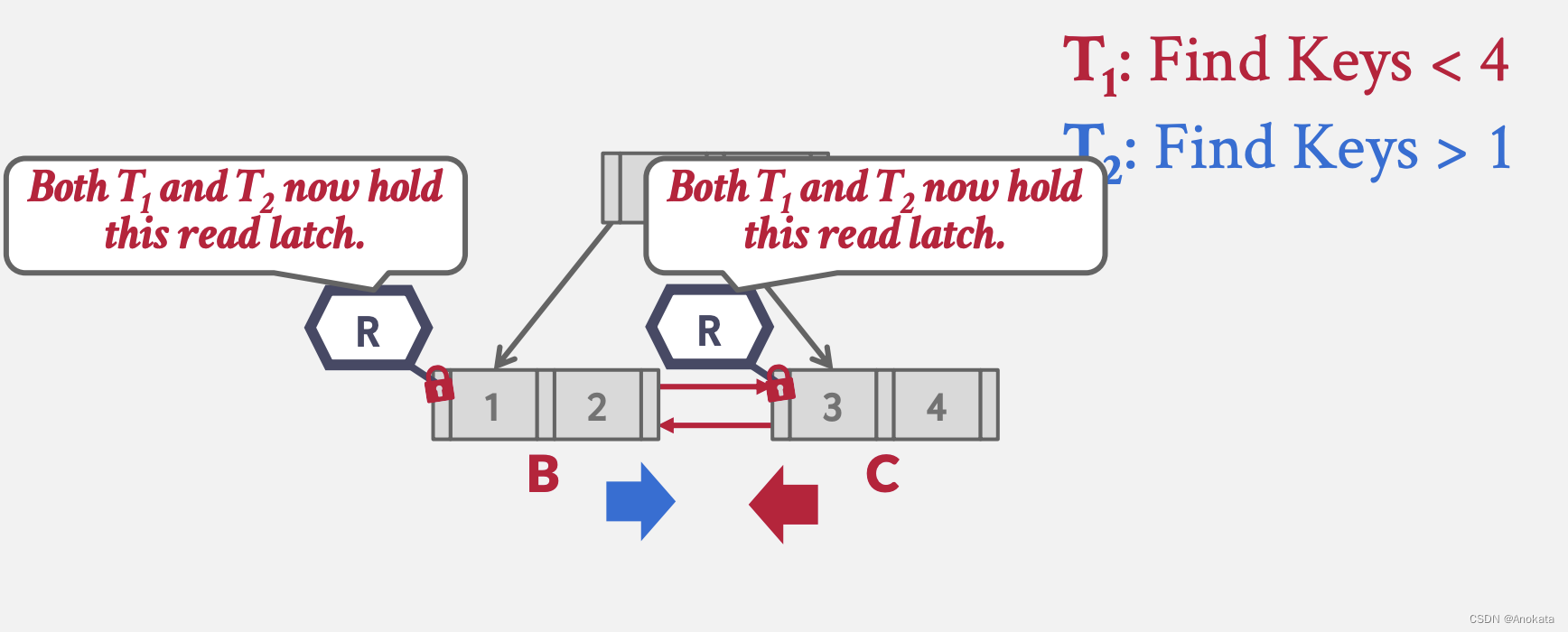
3️⃣ 最后各个线程分别释放自己不需要的锁存器

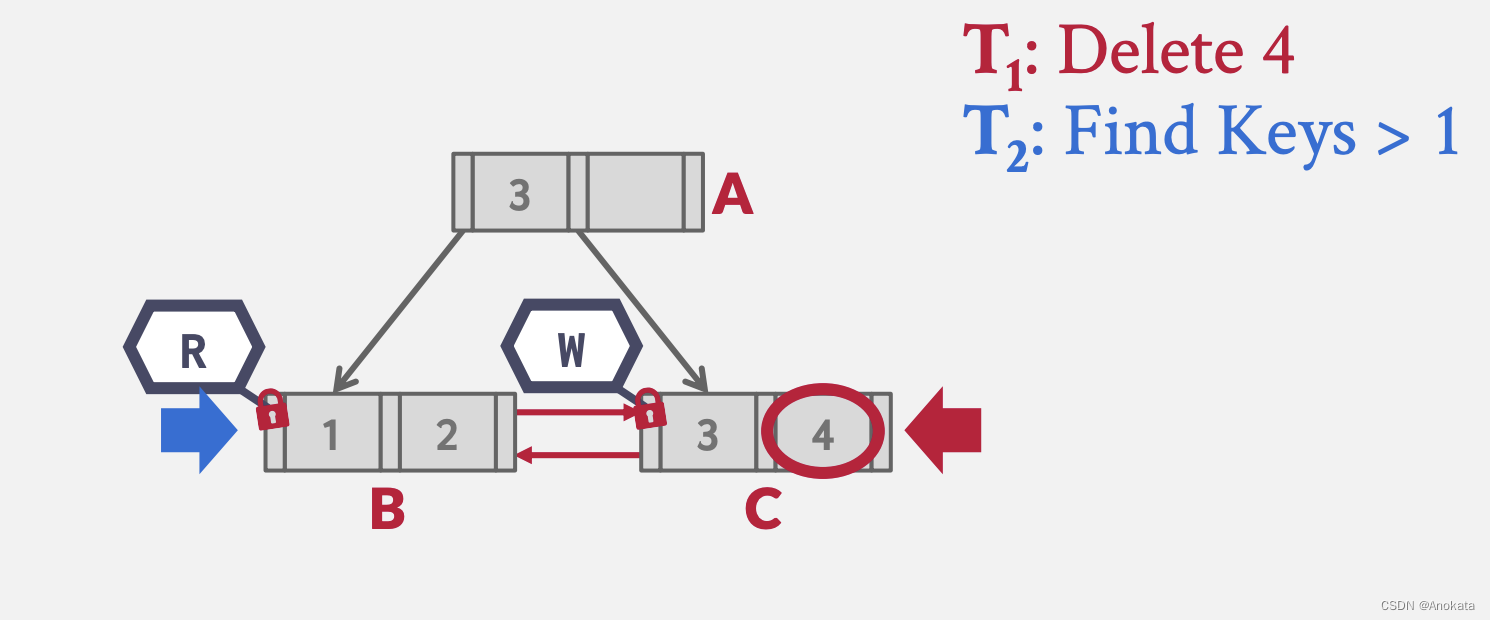
栗子3 多线程读写:
1️⃣ 线程 1 尝试删除元素4,而线程 2 则查询大于 1 的元素,线程 1 按照乐观锁模式,最终拿到 C 节点的写锁存器,而线程 2 则拿到 B 节点的读锁存器
2️⃣ 现在当线程2 想移动到兄弟节点 C 上时,由于该节点被加了写锁存器,线程 2 没办法获取到读锁存器
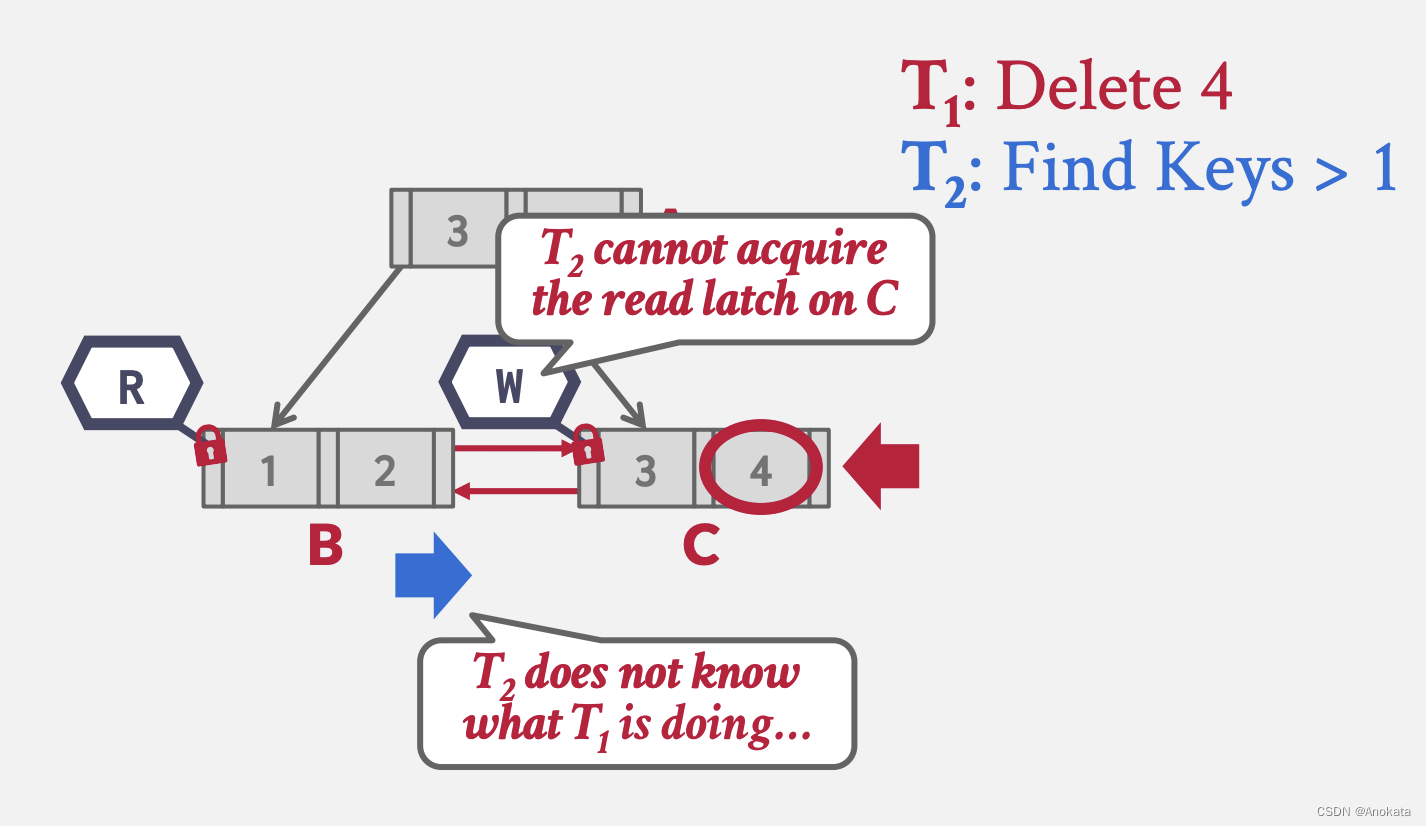
3️⃣ 此时,线程 2 可以做何选择?
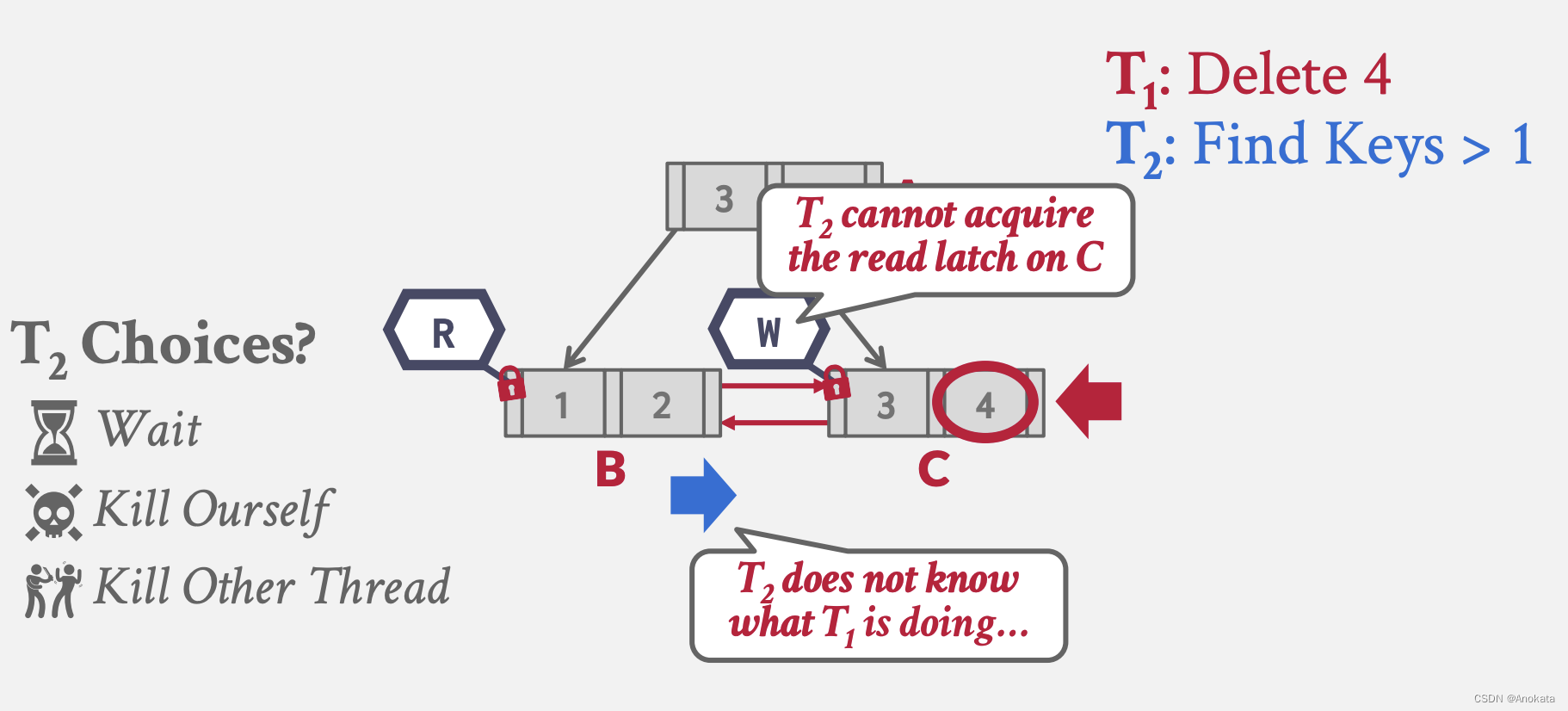
锁存器不支持死锁检测或避免(我们没有办法杜绝死锁的发生)。 我们处理这个问题的唯一方法是通过编码规则【coding discipline】,比如我们可以设置读写锁的优先级,使用先进先出或者循环【Round Robin】的调度策略,调度器会假定征用时很少发生的,并且出现时我们希望快速失败,因此当出现死锁时,最好的办法就是重试,并且需要回滚在事务内做的所有变更,然后 kill 掉自己。需要注意的是,重试对于用户是透明的,完全是数据库自己做的,对于用户的感知时查询时间长了一点。
叶节点同级锁存器获取协议必须支持“无等待【no-wait】”模式。
DBMS 的数据结构必须能够应对失败的锁存获取。














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









