






1.问题描述
在使用seleniumwire中的driver.requests爬取网页数据时,需要进行多次request.response.body请求。网址的压缩方式为gzip,因此进行解压缩后就可获取数据,但这次报错以下内容:
raise BadGzipFile(‘Not a gzipped file (%r)’ % magic)
gzip.BadGzipFile: Not a gzipped file (b’<!')
2.原代码
def wo_data():
start_time = year_entry_start.get() + '-' + month_entry_start.get() + '-' + day_entry_start.get()
end_time = year_entry_end.get() + '-' + month_entry_end.get() + '-' + day_entry_end.get()
_num = entry_num.get()
print(start_time, end_time, _num)
def interceptor_3(request):
if request.method == 'POST' and request.url == 'http://bsdts.chinaetc.org/ass/outerOrder/load-all':
# 修改请求体
rep = 'rows={}'.format(_num)
request.body = request.body.replace(b'rows=20', rep.encode()) # 新值需大于等于20
# 配置chrome
option = webdriver.ChromeOptions()
option.add_argument('headless') # 不使用ui
option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载网页图片
option.add_experimental_option("detach", True) # 不关闭浏览器
option.add_experimental_option('excludeSwitches', ['enable-logging']) # 去掉Failed to read DnsConfig.
options = {
'disable_encoding': True # 禁用请求编码
}
option.binary_location = r'./chrome-win64/chrome.exe'
driver_path = r"./chromedriver-win64/chromedriver.exe"
driver = webdriver.Chrome(service=Service(driver_path), options=option)
driver.maximize_window()
driver.implicitly_wait(90)
driver.get("http://bsdts.chinaetc.org/sso/app/oauth/login?client_id=000061&response_type=code&redirect_uri=http://bsdts.chinaetc.org/ass/login/common/oauth&scope=USERINFO&state=state")
# 登录
driver.find_element(by=By.ID, value='mobile').send_keys(argument.username)
driver.find_element(by=By.ID, value='passwd').send_keys(argument.password)
driver.find_element(by=By.ID, value='submitButton').click()
driver.request_interceptor = interceptor_3
# 高权限账号登录
if argument.username == 'sunxin' or argument.username == 'lyjk0108':
driver.find_element(by=By.XPATH, value='/html/body/div[1]/div[3]/div[1]/div/div[1]/ul/li[4]/a/span').click()
driver.find_element(by=By.XPATH, value='/html/body/div[1]/div[3]/div[1]/div/div[1]/ul/li[4]/ul/li[3]/a/span').click()
# 普通账号登录
else:
driver.find_element(by=By.XPATH, value='/html/body/div[1]/div[3]/div[1]/div/div[1]/ul/li[3]/a/span').click()
driver.find_element(by=By.XPATH, value='/html/body/div[1]/div[3]/div[1]/div/div[1]/ul/li[3]/ul/li[3]/a/span').click()
frame1 = driver.find_element(by=By.ID, value='mainFrame')
driver.switch_to.frame(frame1)
# 日期控件处理,将js属性移除后增加
js_1 = "$('input[id=startTime]').removeAttr('readonly')" # 2.jQuery,移除属性
js_2 = "$('input[id=endTime]').removeAttr('readonly')" # 2.jQuery,移除属性
driver.execute_script(js_1)
driver.execute_script(js_2)
# 对时间段按天数切片函数,返回列表
time_ranges = split_time_ranges_by_week(start_time, end_time)
for time_range in time_ranges:
driver.find_element(by=By.ID, value='startTime').clear()
driver.find_element(by=By.ID, value='startTime').send_keys(time_range[0] + ' 00:00:00')
driver.find_element(by=By.ID, value='endTime').clear()
driver.find_element(by=By.ID, value='endTime').send_keys(time_range[1] + ' 23:59:59')
driver.find_element(by=By.ID, value='spanbtnCommit').click()
print('正在读取: 【' + time_range[0] + '-' + time_range[1] + '】')
append_log('\n' + '正在读取: 【' + time_range[0] + '-' + time_range[1] + '】')
time.sleep(10)
for request in driver.requests:
if request.method == 'POST' and request.url == 'http://bsdts.chinaetc.org/ass/outerOrder/load-all':
data = request.response.body
buff = BytesIO(data)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
print('response data: ', htmls)
driver.requests.clear()
time.sleep(3)
print(code, '\n', title, '\n', escapeCode, '\n', status, '\n', vehicleId, '\n', vehicleType,
'\n', createProvinceName, '\n', createOrgName, '\n', createTime, '\n', finishTime, '\n', clientFee,
'\n', issuerFee, '\n', otherFee, '\n', entryFee, '\n', unitProgress, '\n', auditProgress)
3.报错代码:
for request in driver.requests:
if request.method == 'POST' and request.url == 'http://bsdts.chinaetc.org/ass/credit/record/payList':
'''
* `BytesIO(data)`: 使用`BytesIO`创建一个字节流对象,该对象将`data`作为其内容。这允许你将`data`视为一个文件对象,即使它实际上是一个字节字符串。
* `gzip.GzipFile(fileobj=buff)`: 使用`gzip.GzipFile`创建一个gzip文件对象,该对象使用前面创建的`buff`(即`BytesIO`对象)作为其文件对象。这允许你读取和解压gzip压缩的数据。
* `f.read().decode('utf-8')`: 从gzip文件对象中读取数据,并使用`decode('utf-8')`将其从字节转换为字符串。最终,解压后的HTML内容存储在`htmls`变量中。
'''
data = request.response.body
buff = BytesIO(data)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
print('response data: ', htmls)
driver.requests.clear()
raise BadGzipFile(‘Not a gzipped file (%r)’ % magic) gzip.BadGzipFile: Not a gzipped file (b’<!')
翻译为:引发BadGzipFile(‘不是gzip文件(%r)’%magic)gzip。BadGzipFile:不是一个gzip文件(b’<!),所以考虑是网页内容压缩问题。
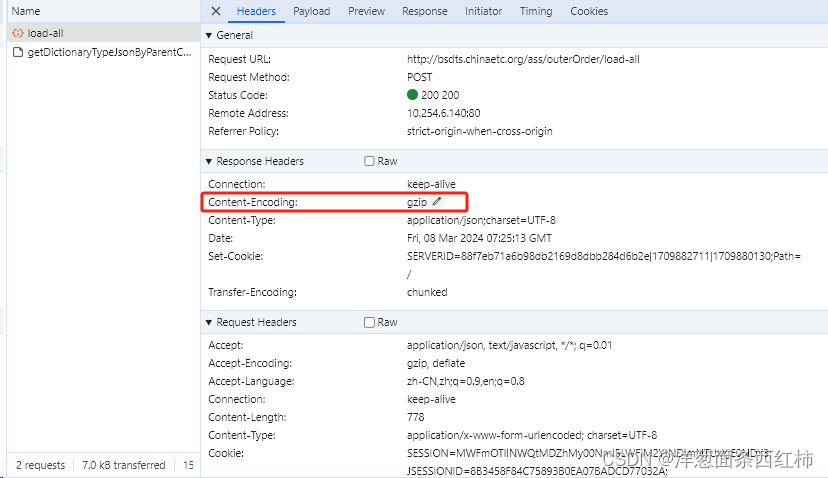
* 即便是对同一网站、同一类别的数据进行爬取,压缩方式也有可能不同。因此,要对每批次数据的类型进行判别,是否进行了压缩。
4.修改后代码
判断request.response.body是否压缩,由于该网址只存在 gzip压缩、未压缩这两种,因此将代码修改为if-else进行判断:
for request in driver.requests:
if request.method == 'POST' and request.url == 'http://bsdts.chinaetc.org/ass/outerOrder/load-all':
if request.response.headers.get('Content-Encoding') == 'gzip':
htmls = gzip.decompress(request.response.body).decode('utf-8')
print('压缩')
print(htmls)
else:
htmls = request.response.body.decode('utf-8')
print(htmls)
print('未压缩')
driver.requests.clear()















 7542
7542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









