






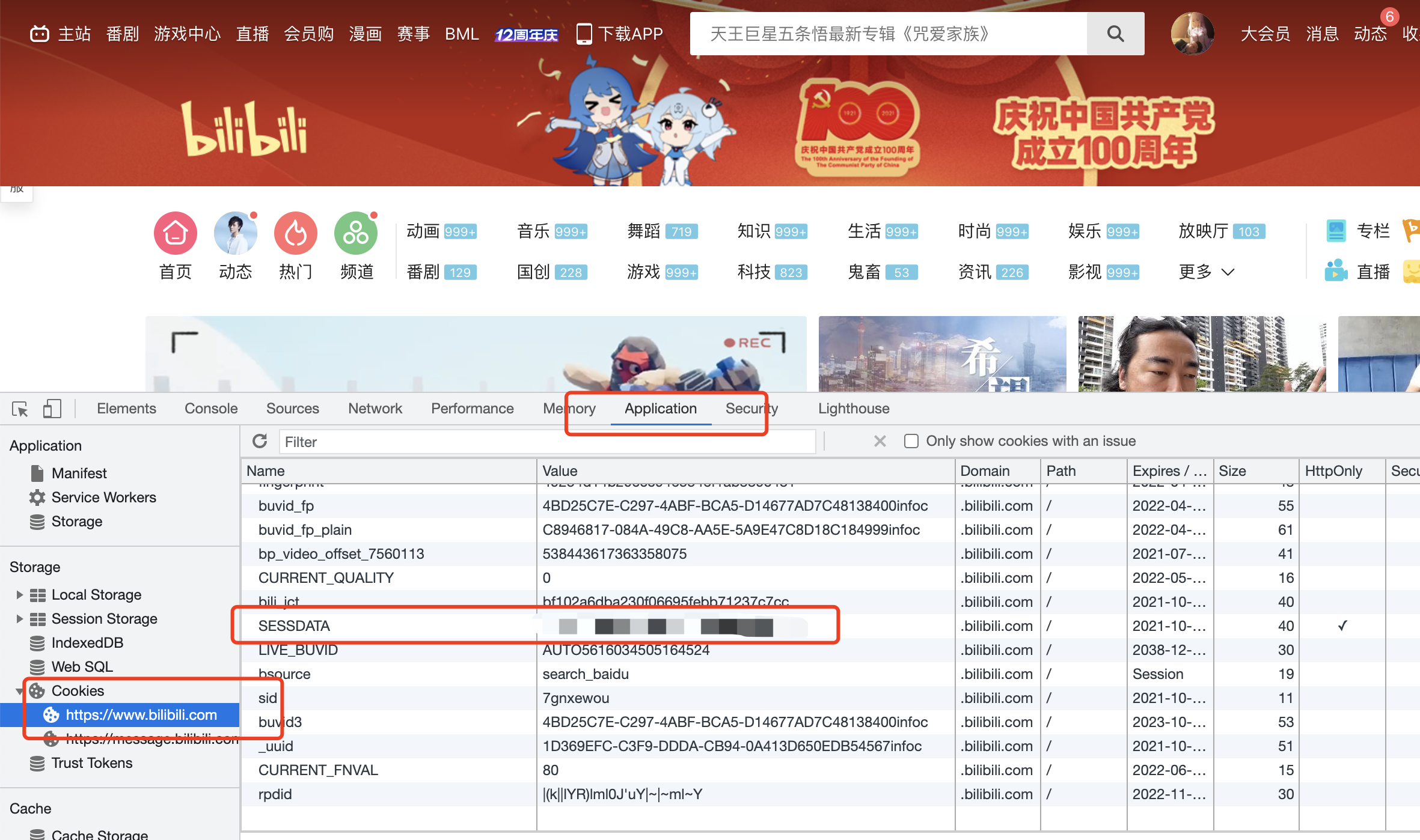
获取B站SESSDATA
- 登录B站
- 按
F12打开控制台 - 找到
SESSDATA复制即可
解决B站防盗链(403)
B站开启了防盗链,利用的是HTTP的Referer属性做判断。如果Referer是他白名单之外的网站,就会返回403
全站图片使用
在html的head标签中设置如下标志,那么全站资源引用都不会携带referrer
<meta name="referrer" content="no-referrer">
新窗口打开
主要设置rel="noreferrer",使用window.open打开的话是会默认携带referrer的,第一次还是会403
<a rel="noreferrer" target="_blank"></a>

















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









