







 本文介绍了如何在无需登录的情况下,利用新浪高级搜索功能爬取特定关键词、时间范围内的微博。通过构造URL,设置参数,如关键字编码、时间范围、请求间隔等,实现了爬虫程序。文中还提到了爬虫可能遇到的机器人检测问题,并列举了所使用的Python库,如urllib、xlwt等。
本文介绍了如何在无需登录的情况下,利用新浪高级搜索功能爬取特定关键词、时间范围内的微博。通过构造URL,设置参数,如关键字编码、时间范围、请求间隔等,实现了爬虫程序。文中还提到了爬虫可能遇到的机器人检测问题,并列举了所使用的Python库,如urllib、xlwt等。
一.爬虫学习
1切入点
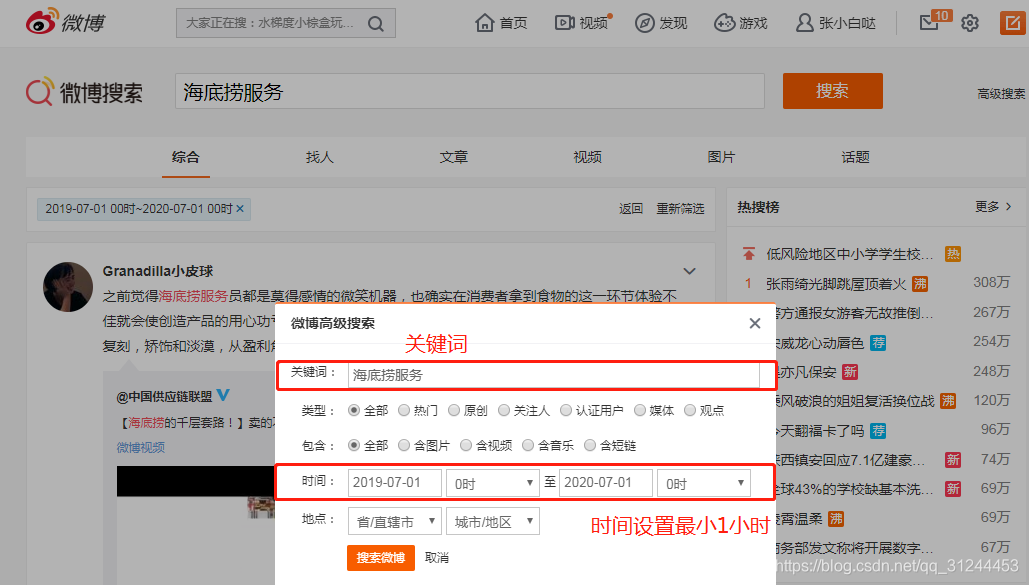
新浪提供高级搜索功能,这个功能需要用户登录才能使用.如何在无需登录的情况下,获取"关键词+时间+区域"的新浪微博.
设置参数实现:
固定地址:https://s.weibo.com/weibo?q=
关键字二次UTF-8编码:%E6%B5%B7%E5%BA%95%E6%8D%9E%E6%9C%8D%E5%8A%A1
类型:typeall=1
suball=1
搜索时间范围:timescope=custom:2019-07-01-0:2020-07-01-0
可忽略项:Refer=g
某次请求的页数:page=1(第一页可不加)
完成.
 、
、
2采集思路
大体思路:构造URL,爬取网页,解析网页中的微博信息,如图1所示.微博官方提供了根据微博ID查询微博信息的API.
根据微博时间间隔限制,设置时间间隔为(timescope)1小时.如2019-07-01-2:2020-07-01-2。
目前没有模拟登陆。所以需要设置两个邻近URL请求之间的随机休眠时间,过于频繁会被认为是机器人.
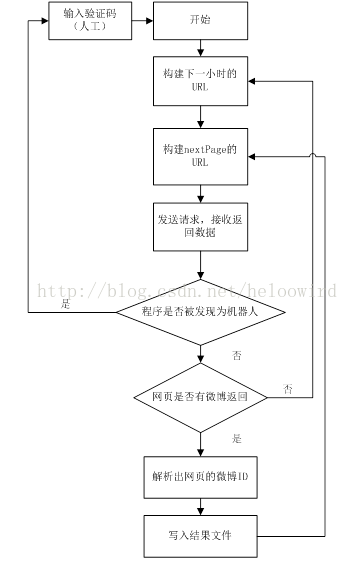
看代码了解实现的逻辑图:
接受键盘输入:
(运行下程序(x))
数据收集类(直接引用类,输入数据进行):
利用微博高级搜索功能,按关键词搜索一定时间范围内的微博.
初始化函数:
设置固定地址部分
设置关键字
设置搜索的开始时间
设置邻近网页请求之间的基础时间间隔(注意:过于频繁会被认为是机器人)
关键词函数:
设置关键词,关键词需编码两次,第一次getKeyWord后,第二次setKeyword解码decode('GBK','ignore')后编码encode("utf-8") 为utf-8.
设置起始时间范围函数setStartTimescope
设置邻近网页请求之间的基础时间间隔 setInterval
设置是否被认为机器人的标志。若为False,需要进入页面,手动输入验证码
构建URL getURL
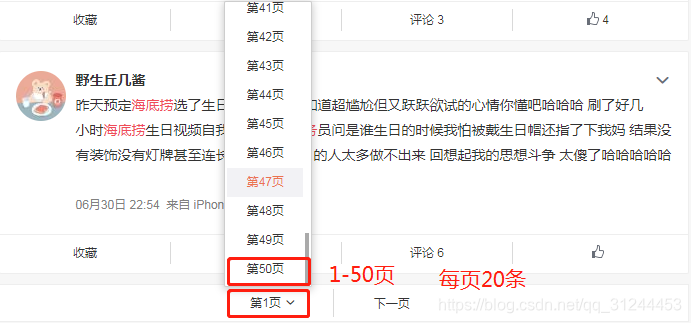
爬取一次请求中的所有网页,最多返回50页 download
| 类 | 数据收集类(直接引用类,输入数据进行):利用微博高级搜索功能,按关键词搜索一定时间范围内的微博. |
| 函数 | 初始化函数: 设置固定地址部分 设置关键字 设置搜索的开始时间 设置邻近网页请求之间的基础时间间隔(注意:过于频繁会被认为是机器人) |
| 函数 | 关键词函数:设置关键词,关键词需编码两次,第一次getKeyWord后,第二次setKeyword解码decode('GBK','ignore')后编码encode("utf-8") 为utf-8. |
| 函数 | 设置起始时间范围函数setStartTimescope |
| 函数 | 设置邻近网页请求之间的基础时间间隔 setInterval |
| 函数 | 设置是否被认为机器人的标志。若为False,需要进入页面,手动输入验证码 |
| 函数 | 构建URL getURL |
| 函数 | 爬取一次请求中的所有网页,最多返回50页 download: 1.没有被机器人发现. 2.被机器人发现. |
| 函数 | 改变搜索的时间范围,有利于获取最多的数据. |
程序:
# coding: utf-8
'''''
以关键词收集新浪微博
'''
import wx
import sys
import urllib
import urllib2
import re
import json
import hashlib
import os
import time
from datetime import datetime
from datetime import timedelta
import random
from lxml import etree
import logging
import xlwt
import xlrd
from xlutils.copy import copy
class CollectData():
"""数据收集类
利用微博高级搜索功能,按关键字搜集一定时间范围内的微博。
"""
def __init__(self, keyword, startTime, interval='50', flag=True, begin_url_per = "http://s.weibo.com/weibo/"):
self.begin_url_per = begin_url_per #设置固定地址部分
self.setKeyword(keyword) #设置关键字
self.setStartTimescope(startTime) #设置搜索的开始时间
#self.setRegion(region) #设置搜索区域
self.setInterval(interval) #设置邻近网页请求之间的基础时间间隔(注意:过于频繁会被认为是机器人)
self.setFlag(flag)
self.logger = logging.getLogger('main.CollectData') #初始化日志
##设置关键字
##关键字需解码后编码为utf-8
def setKeyword(self, keyword):
self.keyword = keyword.decode('GBK','ignore').encode("utf-8")
print 'twice encode:',self.getKeyWord()
##关键字需要进行两次urlencode
def getKeyWord(self):
once = urllib.urlencode({"kw":self.keyword})[3:]
return urllib.urlencode({"kw":once})[3:]
##设置起始范围,间隔为1天
##格式为:yyyy-mm-dd
def setStartTimescope(self, startTime):
if not (startTime == '-'):
self.timescope = startTime + ":" + startTime
else:
self.timescope = '-'
##设置搜索地区
#def setRegion(self, region):
# self.region = region
##设置邻近网页请求之间的基础时间间隔
def setInterval(self, interval):
self.interval = int(interval)
##设置是否被认为机器人的标志。若为False,需要进入页面,手动输入验证码
def setFlag(self, flag):
self.flag = flag
##构建URL
def getURL(self):
return self.begin_url_per+self.getKeyWord()+"&typeall=1&suball=1×cope=custom:"+self.timescope+"&page="
##爬取一次请求中的所有网页,最多返回50页
def download(self, url, maxTryNum=4):
hasMore = True #某次请求可能少于50页,设置标记,判断是否还有下一页
isCaught = False #某次请求被认为是机器人,设置标记,判断是否被抓住。抓住后,需要,进入页面,输入验证码
name_filter = set([]) #过滤重复的微博ID
i = 1 #记录本次请求所返回的页数
while hasMore and i < 51 and (not isCaught): #最多返回50页,对每页进行解析,并写入结果文件
source_url = url + str(i) #构建某页的URL
data = '' #存储该页的网页数据
goon = True #网络中断标记
##网络不好的情况,试着尝试请求三次
for tryNum in range(maxTryNum):
try:
html = urllib2.urlopen(source_url, timeout=12)
data = html.read()
break
except:
if tryNum < (maxTryNum-1):
time.sleep(10)
else:
print 'Internet Connect Error!'
self.logger.error('Internet Connect Error!')
self.logger.info('url: ' + source_url)
self.logger.info('fileNum: ' + str(fileNum))
self.logger.info('page: ' + str(i))
self.flag = False
goon = False
break
if goon:
lines = data.splitlines()
isCaught = True
for line in lines:
## 判断是否有微博内容,出现这一行,则说明没有被认为是机器人
if line.startswith('<script>STK && STK.pageletM && STK.pageletM.view({"pid":"pl_weibo_direct"'):
isCaught = False
n = line.find('html":"')
if n > 0:
j = line[n + 7: -12].encode("utf-8").decode('unicode_escape').encode("utf-8").replace("\\", "") #去掉所有的\
## 没有更多结果页面
if (j.find('<div class="search_noresult">') > 0):
hasMore = False
## 有结果的页面
else:
#此处j要decode,因为上面j被encode成utf-8了
page = etree.HTML(j.decode('utf-8'))
ps = page.xpath("//p[@node-type='feed_list_content']") #使用xpath解析得到微博内容
addrs = page.xpath("//a[@class='W_texta W_fb']") #使用xpath解析得到博主地址
addri = 0
#获取昵称和微博内容
for p in ps:
name = p.attrib.get('nick-name') #获取昵称
txt = p.xpath('string(.)') #获取微博内容
addr = addrs[addri].attrib.get('href') #获取微博地址
addri += 1
if(name != 'None' and str(txt) != 'None' and name not in name_filter): #导出数据到excel中
name_filter.add(name)
oldWb = xlrd.open_workbook('weiboData.xls', formatting_info=True)
oldWs = oldWb.sheet_by_index(0)
rows = int(oldWs.cell(0,0).value)
newWb = copy(oldWb)
newWs = newWb.get_sheet(0)
newWs.write(rows, 0, str(rows))
newWs.write(rows, 1, name)
newWs.write(rows, 2, self.timescope)
newWs.write(rows, 3, addr)
newWs.write(rows, 4, txt)
newWs.write(0, 0, str(rows+1))
newWb.save('weiboData.xls')
print "save with same name ok"
break
lines = None
## 处理被认为是机器人的情况
if isCaught:
print 'Be Caught!'
self.logger.error('Be Caught Error!')
self.logger.info('filePath: ' + savedir)
self.logger.info('url: ' + source_url)
self.logger.info('fileNum: ' + str(fileNum))
self.logger.info('page:' + str(i))
data = None
self.flag = False
break
## 没有更多结果,结束该次请求,跳到下一个请求
if not hasMore:
print 'No More Results!'
if i == 1:
time.sleep(random.randint(3,8))
else:
time.sleep(10)
data = None
break
i += 1
## 设置两个邻近URL请求之间的随机休眠时间,防止Be Caught
sleeptime_one = random.randint(self.interval-25,self.interval-15)
sleeptime_two = random.randint(self.interval-15,self.interval)
if i%2 == 0:
sleeptime = sleeptime_two
else:
sleeptime = sleeptime_one
print 'sleeping ' + str(sleeptime) + ' seconds...'
time.sleep(sleeptime)
else:
break
##改变搜索的时间范围,有利于获取最多的数据
def getTimescope(self, perTimescope):
if not (perTimescope=='-'):
times_list = perTimescope.split(':')
start_date = datetime(int(times_list[-1][0:4]), int(times_list[-1][5:7]), int(times_list[-1][8:10]) )
start_new_date = start_date + timedelta(days = 1)
start_str = start_new_date.strftime("%Y-%m-%d")
return start_str + ":" + start_str
else:
return '-'
def main():
logger = logging.getLogger('main')
logFile = './collect.log'
logger.setLevel(logging.DEBUG)
filehandler = logging.FileHandler(logFile)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s: %(message)s')
filehandler.setFormatter(formatter)
logger.addHandler(filehandler)
while True:
## 接受键盘输入
keyword = raw_input('Enter the keyword(type \'quit\' to exit ):')
if keyword == 'quit':
sys.exit()
startTime = raw_input('Enter the start time(Format:YYYY-mm-dd):')
#region = raw_input('Enter the region([BJ]11:1000,[SH]31:1000,[GZ]44:1,[CD]51:1):')
interval = raw_input('Enter the time interval( >30 and deafult:50):')
##实例化收集类,收集指定关键字和起始时间的微博
cd = CollectData(keyword, startTime, interval)
while cd.flag:
print cd.timescope
logger.info(cd.timescope)
url = cd.getURL()
cd.download(url)
cd.timescope = cd.getTimescope(cd.timescope) #改变搜索的时间,到下一天
else:
cd = None
print '-----------------------------------------------------'
print '-----------------------------------------------------'
else:
logger.removeHandler(filehandler)
logger = None
##if __name__ == '__main__':
## main() 3程序与用到的库:
库:urllib,urllib2,xlwt,xlrd,os,json.
[2]https://www.cnblogs.com/AmilyWilly/p/5938998.html

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









