







1、餐饮企业现状与需求
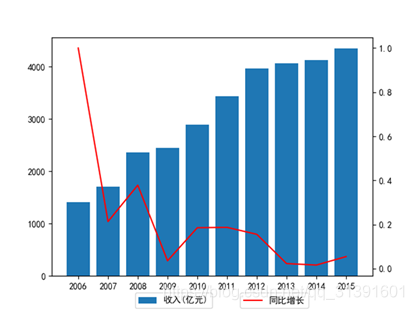
餐饮行业作为我国第三产业中的一个传统服务性行业,始终保持着旺盛的增长势头,取得了突飞猛进的发展,展现出繁荣兴旺的新局面。与此同时,我国餐饮业发展的质量和内涵也发生了重大变化。根据国家统计局数据显示,餐饮行业餐费收入从2006到2015年都处于增长的趋势,但是同比增长率却有很大的波动,如右图所示。
某餐饮企业正面临着房租价格高、人工费用高、服务工作效率低等问题。企业经营最大的目的就是盈利,而餐饮企业盈利的核心是其菜品和客户,也就是其提供的产品和服务对象。如何在保证产品质量的同时提高企业利润,成为某餐饮企业急需解决的问题。
2、餐饮企业数据分析的步骤与流程
通过对某餐饮企业的数据进行分析,最终为餐饮企业提出改善的建议。主要步骤如下图所示。
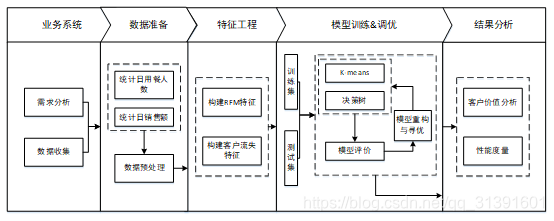
(1)从系统数据库中迁移与分析相关的数据到分析数据库中,包括客户信息、菜品详情、订单表和订单详情等。
(2)对数据进行预处理,统计菜品数据中的每日用餐人数、每日销售额并进行数据清洗等。
(3)进行特征工程,构建RFM特征和客户流失特征。
(4)使用K-means算法,对客户进行聚类分析,并基于聚类结果进行客户价值分析。
3、数据准备
订单表(meal_order_info.csv)和客户信息表(users.csv)中包含2016年8月份的订单和对应客户的数据,将使用该部分数据进行客户价值聚类分析。历史订单表(info_new)和历史客户信息表(user_loss)包含2016年1~7月份的订单和对应客户的数据,将使用该部分数据构建客户流失预测模型,统计每日用餐人数与销售额。
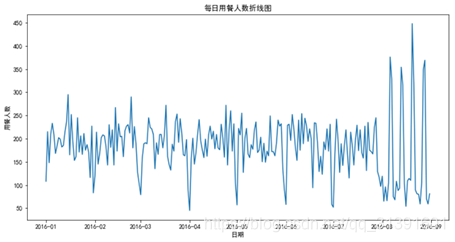
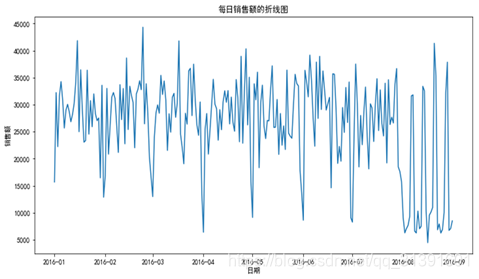
4、数据预处理
原始数据中的客户信息表(users.csv)没有直接给出客户最后一次消费的时间,订单表(meal_order_info.csv)中存在未完成的订单,如订单状态为0或2,且存在其不相关、弱相关或冗余的特征,所以需要先对原始数据进行预处理,如下代码所示。
info_august = pd.read_csv('../data/meal_order_info.csv', encoding='utf-8')
users_august = pd.read_csv('../data/users.csv', encoding='gbk')
# 提取订单状态为1的数据
info_august_new = info_august[info_august['order_status'].isin(['1'])]
info_august_new = info_august_new.reset_index(drop=True)
print('提取的订单数据维数:', info_august_new.shape)
info_august_new.to_csv('../tmp/info_august_new.csv', index=False, encoding='utf-8')
# 匹配用户的最后一次用餐时间
for i in range(1, len(info_august_new)):
num = users_august[users_august['USER_ID'] ==
info_august_new.iloc[i-1, 1]].index.tolist()
users_august.iloc[num[0], 14] = info_august_new.iloc[i-1, 9]
users_august.iloc[num[0], 14] = info_august_new.iloc[i-1, 9]
user = users_august
user['LAST_VISITS'] = user['LAST_VISITS'].fillna(999)
user = user.drop(user[user['LAST_VISITS'] == 999].index.tolist())
user = user.iloc[:, [0, 2, 12, 14]]
print(user.head())
user.to_csv('../tmp/users_august.csv', index=False, encoding='utf-8')5、使用K-means算法进行客户价值分析
聚类可以从消费者中区分出不同的消费群体,并且概括出每一类消费者的消费模式或消费习惯,其中,K-Means算法是最为经典的基于划分的聚类方法。识别客户价值应用最广泛的模型是RFM模型,根据RFM模型,本案例中客户价值分析的关键特征,如下表所示。
| 特征名称 | 含义 |
| R | 客户最近一次消费距观测窗口结束的天数。 |
| F | 客户在观测窗口内总消费次数。 |
| M | 客户在观测窗口内总消费金额。 |
使用K-means算法进行客户价值分析,如下代码所示。
# 绘图
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, polar=True)
sam = ['r','g','b']
lstype = ['-','--','-.']
lab = []
for i in range(len(kmeans_model.cluster_centers_)):
values = kmeans_model.cluster_centers_[i]
feature = ['R','F','M']
values = np.concatenate((values, [values[0]]))
# 绘制折线图
ax.plot(angles, values, sam[i], linestyle=lstype[i], linewidth=2, markersize=10)
ax.fill(angles, values, alpha=0.5) # 填充颜色
ax.set_thetagrids(angles * 180 / np.pi, feature, fontsize=15) # 添加每个特征的标签
plt.title('客户群特征分布图') # 添加标题
ax.grid(True)
lab.append('客户群' + str(i+1))
plt.legend(lab)
plt.show()
plt.close
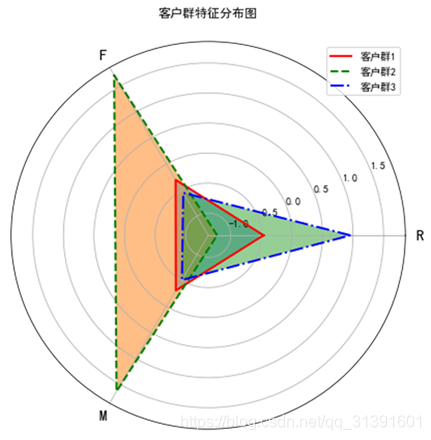
由上图可知,客户群2的F、M特征值最大,R特征值最小;客户群1的F、M、R特征值较小;客户群3的R特征值最大,F、M特征值最小。每个客户群的都有显著不同的表现特征,基于该特征描述,本案例定义3个等级的客户类别:重要保持客户、一般价值客户、低价值客户。客户群分类排序结果如下表所示。
| 客户群 | 排名 | 排名含义 |
| 客户群1 | 2 | 一般价值客户 |
| 客户群2 | 1 | 重要保持客户 |
| 客户群3 | 3 | 低价值客户 |

















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









