







 哈希表是一种数据结构,利用哈希函数将键转化为数组下标进行快速访问。理想哈希函数应使哈希值分布均匀以减少冲突。除留取余法是常见的哈希函数构造方法。哈希冲突可通过开放寻址法(如线性探测)或链表法解决。开放寻址法在冲突时沿着数组顺序查找空位。
哈希表是一种数据结构,利用哈希函数将键转化为数组下标进行快速访问。理想哈希函数应使哈希值分布均匀以减少冲突。除留取余法是常见的哈希函数构造方法。哈希冲突可通过开放寻址法(如线性探测)或链表法解决。开放寻址法在冲突时沿着数组顺序查找空位。
基本概念
哈希表是一种数据结构。散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。哈希表的索引并不像普通数组的索引那样,从0到length-1,而是由关键字(key)即数据本身通过哈希函数(hash function)得到。

我们把键(key)或者关键字转化为数组下标的映射方法就叫作哈希函数,而哈希函数计算得到的值就叫作哈希值。
哈希函数
哈希函数可以定义为hash(key),其中key表示元素的键值,关键字(key)通过哈希函数得到哈希值也就是索引。理想的哈希函数应该满足以下三个条件:
①散列函数计算得到的哈希值是一个非负整数;
②如果 key1 = key2,那 hash(key1) == hash(key2);
③如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2);
第一点很好理解,因为哈希值是数组的索引,所以必须为非负正数。第二点也很好理解,当key值相同时,哈希值应该相同。第三点的意思是说,对于不同的key值对应的哈希值都不一样。但是在现实情况中,这几乎是不可能的,哈希冲突无法完全避免。
哈希函数的设计很重要,应该尽量减少哈希冲突。也就是说“键”通过哈希函数得到的“索引”分布越均匀越好。
除留取余法
这种方法是最常用的散列函数构造方法,对于表长为m的散列公式为:
hash(key) = key mod p (p<=m)
一般情况下p取素数。
哈希冲突
通过哈希函数计算出的索引,即使关键字不同,索引也会有可能相同。这就是哈希冲突。当索引相同时,我们该怎么存储数据呢?如何解决哈希冲突,是我们建哈希表的一个关键问题。
我们常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。那如何重新探测新的位置呢?常用的方法有线性探测(Linear Probing),二次探测(Quadratic probing)和双重散列(Double hashing)。
先看线性探测:当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。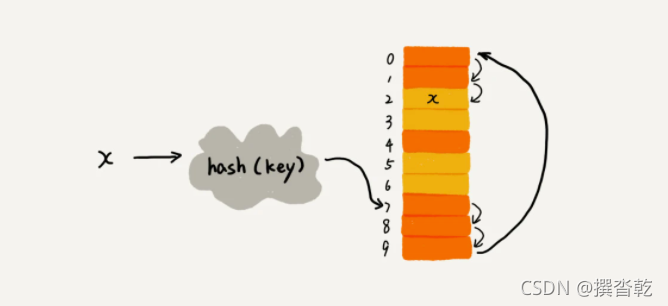
上图中黄色的色块表示空闲位置,橙色的色块表示已经存储了数据。可以看出key值x经过哈希函数计算后得到的哈希值为7,但是这个位置已经有数据了,所以就产生了冲突。于是我们就顺序地往后一个一个找,看有没有空闲的位置,遍历到尾部都没有找到空闲的位置,于是我们再从表头开始找,直到找到空闲位置 2,于是将x插入到这个位置。
在散列表中查找元素的过程有点儿类似上面的插入过程。我们通过哈希函数求出要查找元素的键值对应的哈希值,然后比较数组中下标为哈希值的元素和要查找的元素。如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在散列表中。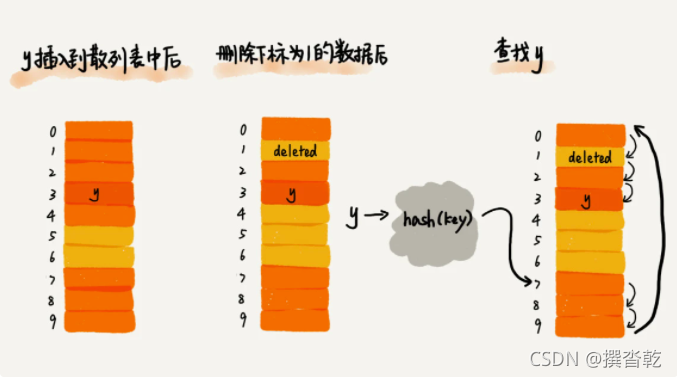
对于使用线性探测法解决冲突的散列表,删除操作稍微有些特别。我们不能单纯地把要删除的元素设置为空。因为在查找的时候,一旦我们通过线性探测方法,找到一个空闲位置,我们就可以认定散列表中不存在这个数据。但是,如果这个空闲位置是我们后来删除的,就可能导致本来存在的数据,会被认定为不存在。我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









