







一、分类任务
1.二分类
二选一的分类任务。比如房价涨还是跌、天气晴还是阴、性别是男还是女。
2.多分类
人脸识别、数字识别、健康状况分级等。
很多复杂的问题也可以转换成多分类任务。
比如贪吃蛇,我们通过大量数据训练贪吃蛇,让贪吃蛇在每次前进时自己判断左移、右移、上移还是下移,这同样也是一个分类任务。
还比如下棋、无人驾驶都可以转换成分类问题。
一些算法只支持完成二分类任务,但是多分类的任务可以转换成二分类的任务,有一些算法天然可以完成多分类任务。
3.多标签分类
每个样本可以属于多个类别或标签。这与传统的二分类、多分类问题不同,在多分类问题中,每个样本只能属于一个类别。多标签分类在现实应用中更为常见,例如,一部电影可能同时属于“科幻”和“动作”类别。
二、回归任务
与分类任务不同的是,回归任务的结果是一个连续数字的值,而非一个类别。比如房价预测:
| 面积(平米) | 房龄(年) | 是否是学区 | 距地铁(千米) | 价格(万) |
| 100 | 5 | 是 | 1 | 300 |
| 110 | 4 | 是 | 2 | 200 |
| 120 | 3 | 否 | 3 | 100 |
在一些情况下,回归任务可以简化成分类任务。其实分类问题和回归问题也是监督学习要解决的两大问题。
3.监督学习
给机器的训练数据拥有“标记”或者“答案”。
生活中大部分的场景都属于“监督学习”的范畴,比如:判断一个人是否健康、股票价格、航班是否晚点等等。
常见的监督学习算法包括:K近邻、线性回归和多项式回归、逻辑回归、SVM、决策树和随机森林。
4.非监督学习
给机器的训练数据没有任何 “标记”或者“答案”。
非监督学习主要对没有“标记”的数据进行分类——聚类分析。
常见的应用还有对数据进行降维处理(方便可视化)、特征提取、特征压缩、异常检测。
5.半监督学习
一部分数据有标记或答案,另一部分没有。
这种学习方式在现实中更为常见:各种原因产生的标记缺失。通常对于半监督学习而言,通常先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测。
6.增强学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。
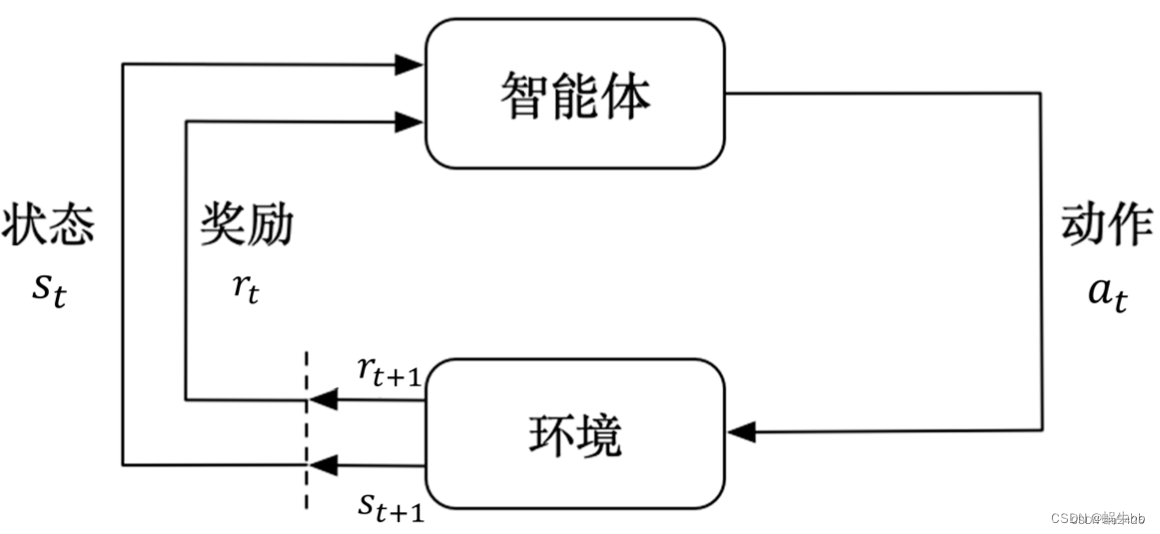
增强学习的应用领域有无人机、机器人、阿尔法狗等。
7.批量学习(离线学习)
必须用所有可用数据进行训练。这通常会占用大量时间和计算资源。首先是进行训练,然后部署在生产环境且停止学习,它只会使用已经学到的策略。如果想让一个批量学习系统明白新数据(例如垃圾邮件的新类型),就需要从头训练一个系统的新版本,使用全部数据集(不仅有新数据也有老数据),然后停掉老系统,换上新系统。这种学习方式不容易适应新的变化。
8.在线学习
在数据不断到来的过程中,动态地更新模型。在线学习具有实时性,可以快速适应新数据的特征变化,而且可以避免离线学习需要重新生成模型的问题。但是,由于在线学习需要实时计算,因此会对系统的性能产生一定的影响。此外,由于在线学习需要实时计算,因此需要进行一定的模型设计和优化,以提高算法的效率和准确性。
9.参数学习
- 选择一种目标函数的形式
- 从训练数据中学习目标函数的系数
假设可以最大程度地简化学习过程,与此同时也限制可以学习什么,这种算法简化成一个已知的函数形式,即通过固定数目的参数来拟合数据的算法。一旦学到了参数,就不再需要原有的数据集。参数学习常见算法:
- Logistic Regression
- LDA(线性判别分析)
- 感知机
- 朴素贝叶斯
- 简单的神经网络
10.非参数学习
不对目标函数的形式作出强烈假设的算法称为非参数机器学习算法,通过不做假设,它们可以从训练数据中自由地学习任何函数形式,即参数数量会随着训练样本数量增长的算法。
不对模型进行过多假设,而且非参数不等于没参数。
非参数学习常见算法:
- KNN
- 决策树,比如CART和C4.5
- SVM















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









