






目录
图像识别技术简介
前言
图像识别技术是计算机视觉领域的一个重要研究方向。 Python作为一种功能强大且易于学习的编程语言,被广泛用于数据分析、机器学习和人工智能领域。
基本原理
将视频源中获取的图像数据传入模型 ,通过计算机视觉算法识别分析图像中的对象或特征。
主要步骤
- 获取图像数据:通过调用摄像头或读取视频文件获取实时的图像数据。
- 图像预处理:对获取的图像数据进行预处理,如裁剪、灰度转换等。
- 特征提取:利用计算机视觉算法从图像中提取出关键特征,例如文字、颜色等。
- 模型训练和预测:利用机器学习框架构建和训练模型,将预处理后的图像数据输入模型进行识别和分类。
- 显示结果:将识别的结果以可视化的形式展示出来。
图像处理
OpenCV库
简介
OpenCV(Open Source Computer Vision Library)是一个基于Apache2.0许可开源发行的跨平台计算机视觉库,实现了很多图像处理的通用算法。它由一系列C函数和少量C++构成,同时提供了Python语言接口。 刚才也提到过图像识别的第一步是从视频源获取图像数据,我们就可以用opencv从视频中捕获帧并保存到本地。
基本语法

代码演示
下面演示如何读取并保存视频中的帧
import cv2
class VideoToImage:
@staticmethod
def video_2_image(video_path):
# 初始化视频文件
cap = cv2.VideoCapture(video_path)
# 获取视频总帧数
frames = cap.get(cv2.CAP_PROP_FRAME_COUNT)
print("视频总帧数: " + str(frames))
# 保存图片
i = 1
while cap.isOpened():
# 读取视频
ret, frame = cap.read()
# 保存每一帧图像
cv2.imwrite("/save_url/" + str(i) + ".png", frame)
i += 1
# 释放
cap.release()
videoToImage = VideoToImage()
PIL库
简介
PIL(Python Image Library)是Python中较为基础的图像处理库。 Image模块是Python PIL图像处理中常见的模块,用来对图像进行一些基础操作。
基本语法

代码演示
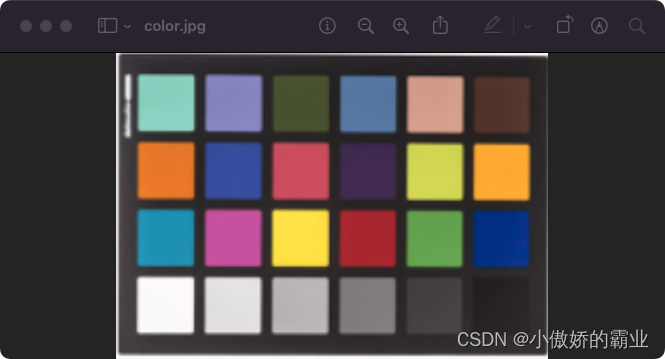
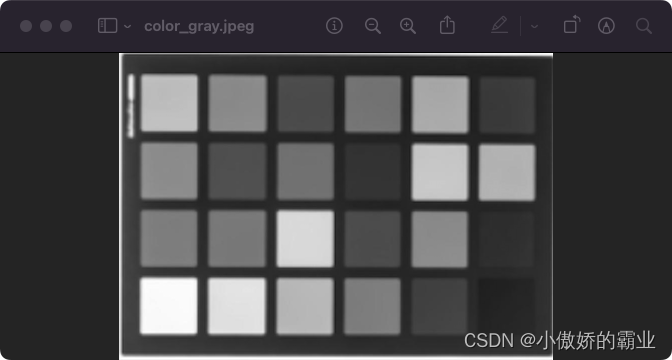
将图像进行灰度处理往往非常有利于排除干扰以便于分析图像,下面演示如何灰度处理图像。
from PIL import Image
class ImageProcess:
# 灰度图
@staticmethod
def gray_image():
# 读取彩色图像
img = Image.open('/Desktop/share/pic/color.jpeg')
# 转化为灰度图
gray_img = img.convert('L')
# 保存灰度图
gray_img.save('/Desktop/share/pic/color_gray.jpeg')
# 显示图片
gray_img.show()
imageProcess = ImageProcess()运行结果
图像识别
识别文字
Tesseract-OCR简介
OCR(Optical Character Recognition,光学字符识别)是指通过扫描纸质为文档或照片,通过计算机对图像记录的文字进行识别的一种技术。Tesseract 是一个OCR 库,目前由Google 赞助。Tesseract 是目前公认最优秀、最精确的开源OCR 系统。
优点:部署快,轻量级,离线可用,免费
缺点:自带的中文库识别率较低,需要自己建数据进行训练
使用方法
string = pytesseract.image_to_string(image, lang='chi_sim+eng', config='--psm 6')
- image(必需):要进行识别的图像。
- lang(可选):指定要使用的语言模型的语言标识符 eng英文 chi_sim中文简体。
- config(可选):指定tesseract的其他配置。如图像处理参数、OEM(引擎模式)参数等。
代码演示
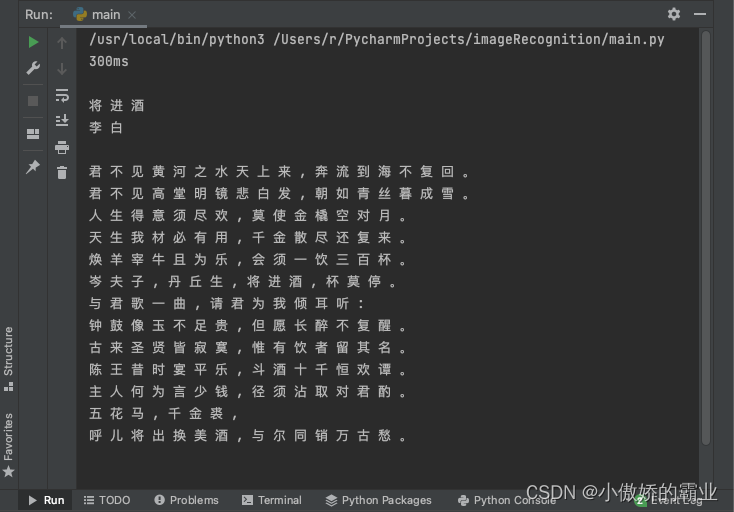
演示识别图片中李白的《将进酒》

import cv2
from pytesseract import pytesseract
class TextRecognition:
@staticmethod
def text_recognition():
# 识别数字和英文
image = cv2.imread('/Users/r/Desktop/share/pic/300ms.jpeg')
text = pytesseract.image_to_string(image, lang='eng', config='--psm 7')
print(text)
# 识别中文
image = cv2.imread('/Users/r/Desktop/share/pic/chinese.png')
text = pytesseract.image_to_string(image, lang='chi_sim', config='--psm 6')
print(text)
textRecognition = TextRecognition()
运行结果
学习网址
Tesseract 源码下载 https://github.com/tesseract-ocr/tesseract/releases
Tesseract 文档 https://tesseract-ocr.github.io/tessdoc/Compiling.html
vietocr官网 https://vietocr.sourceforge.net/training.html
jTessBoxEditor官网 https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
识别颜色
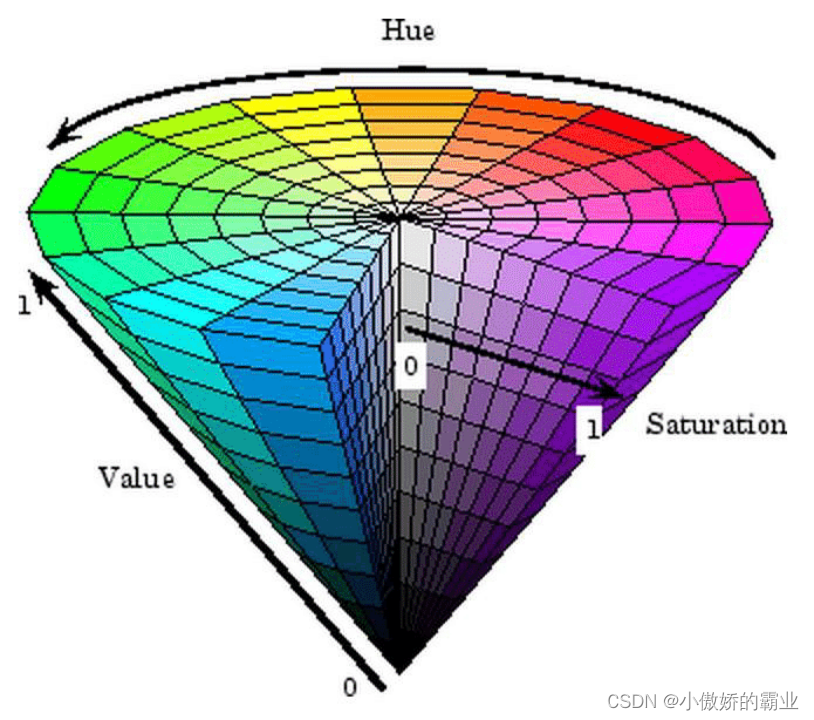
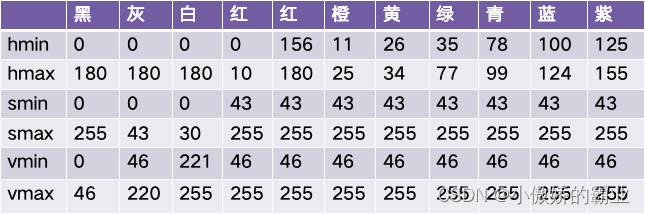
HSV简介
HSV(Hue, Saturation, Value)是根据颜色的直观特性由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model)。HSV颜色模型是指H、S、V三维颜色空间中的一个可见光子集,它包含某个颜色域的所有颜色。
HSV模型参数
这个模型中颜色的参数分别是:色相(H),饱和度(S),亮度(V)。色相H参数表示色彩信息,即所处的光谱颜色的位置。
代码演示
从图片中识别出黄色
import cv2
import numpy as np
import matplotlib.pyplot as plt
class ColorRecognition:
# 颜色识别
@staticmethod
def color_recognition():
print("从图像中识别颜色")
# 获取图像数据
img = cv2.imread("/Users/r/Desktop/share/pic/color.jpg")
img = cv2.medianBlur(img, 7)
cv2.namedWindow("HSV")
# 从RGB转换为HSV
HSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 黄色HSV范围
lower1 = np.array([26, 43, 90])
upper1 = np.array([34, 255, 255])
mask = cv2.inRange(HSV, lower1, upper1)
mask = cv2.medianBlur(mask, 5)
mask_and = cv2.bitwise_and(img, img, mask=mask)
# 显示
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
mask_and = cv2.cvtColor(mask_and, cv2.COLOR_BGR2RGB)
plt.subplot(1, 2, 1), plt.imshow(img_rgb)
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(1, 2, 2), plt.imshow(mask_and)
plt.title('Image Yellow'), plt.xticks([]), plt.yticks([])
plt.show()
cv2.waitKey(0)
cv2.destroyAllWindows()
colorRecognition = ColorRecognition()运行结果

应用实践
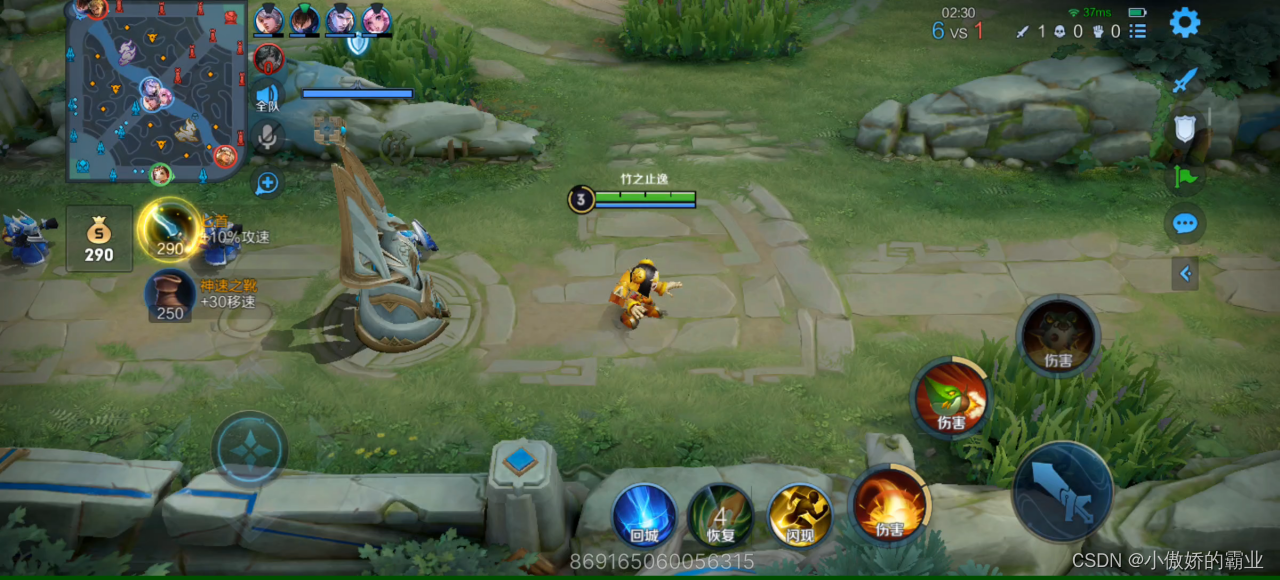
王者荣耀WIFI弱信号测试
连接指定弱信号WI-FI玩王者荣耀游戏,自动计算游戏过程的总时长、时延在200ms以上的总时长以及卡顿总次数。
实现思路
将王者荣耀游戏录屏按帧率转换为图片,对截取图片的时延部分进行二次截取,分析识别图片的文字或颜色,从而计算出200ms以上的总时长和卡顿次数。
![]()
![]()
![]()
代码实现
步骤一:将游戏视频转化为图片并保存在本地文件夹
video2pic.py
# 将四个文件夹中的多个视频文件转换为图片
import cv2
import os
number_in_dir = [] # 可以去掉,用来统计文件个数的
class Video2images:
@staticmethod
def videos2images(file_name, video_path, image_save_dir, every_video_save_dir):
# 1. 在存储路径下创建副文件夹(视频类型文件夹)。将图片的存储路径加上源文件的文件夹名,如'Coffee_room_01'等。
if os.path.exists(video_path): # 判断源路径是否正确
print(video_path + '\t ok')
number_in_dir.append(len(os.listdir(video_path))) # 可以去掉
else:
print(video_path + ' \033[0;37;41merror\033[0m')
return
# 2. 开始转换。打印正在处理文件的序号和他的文件名,并开始转换
cap = cv2.VideoCapture(video_path + file_name)
# 帧率(frames per second)
fps = cap.get(cv2.CAP_PROP_FPS)
# 总帧数(frames)
frames = cap.get(cv2.CAP_PROP_FRAME_COUNT)
# 总时长
video_time = "{0:.2f}".format(frames / fps)
print("=" * 100)
print("视频名称:" + file_name)
print("帧率:" + str(fps))
print("总帧数:" + str(frames))
print("视频总时长:" + "{0:.2f}".format(frames / fps) + "秒")
print("=" * 100)
timeF = int(fps) # 视频帧计数间隔频率
flag = cap.isOpened()
if not flag:
print("open" + video_path + file_name + "error!")
frame_count = 0 # 给每一帧标号
i = 1
while True:
frame_count += 1
flag, frame = cap.read()
if not flag: # 如果已经读取到最后一帧则退出
break
# if os.path.exists(
# image_save_dir + every_video_save_dir + str(frame_count) + '.jpg'): # 在源视频不变的情况下,如果已经创建,则跳过
# break
if frame_count % timeF == 0:
cv2.imwrite(image_save_dir + every_video_save_dir + str(i) + '.jpg', frame)
i += 1
cap.release()
print(file_name + ' save to ' + image_save_dir + every_video_save_dir + ' finished ') # 表示一个视频片段已经转换完成
return video_time
@staticmethod
def mkdir_file(file_in_video_path, image_save_dir):
# 读取源路径文件,并创建子文件夹(一段视频一个文件夹)。依次读取源文件里的文件,如果后缀名是‘avi'或 ’MP3',则创建一个关于文件名的子文件夹
file_count = 0 # 用于统计个数,验证是否全为视频文件,会与len(files_in_video_path_list)进行比较
every_video_save_dir = ""
file_name = os.path.basename(file_in_video_path)
if file_name.split('.')[-1] == 'avi' or file_name.split('.')[-1] == 'mp4':
file_count += 1 # 视频文件数+1
every_video_save_dir = file_name.split('.')[0] + '\\'
if not os.path.exists(image_save_dir + every_video_save_dir): # 创建属于相应文件夹的存储路径
os.makedirs(image_save_dir + every_video_save_dir)
else:
print(' \033[0;37;41merror\033[0m')
return file_name, every_video_save_dir
运行结果
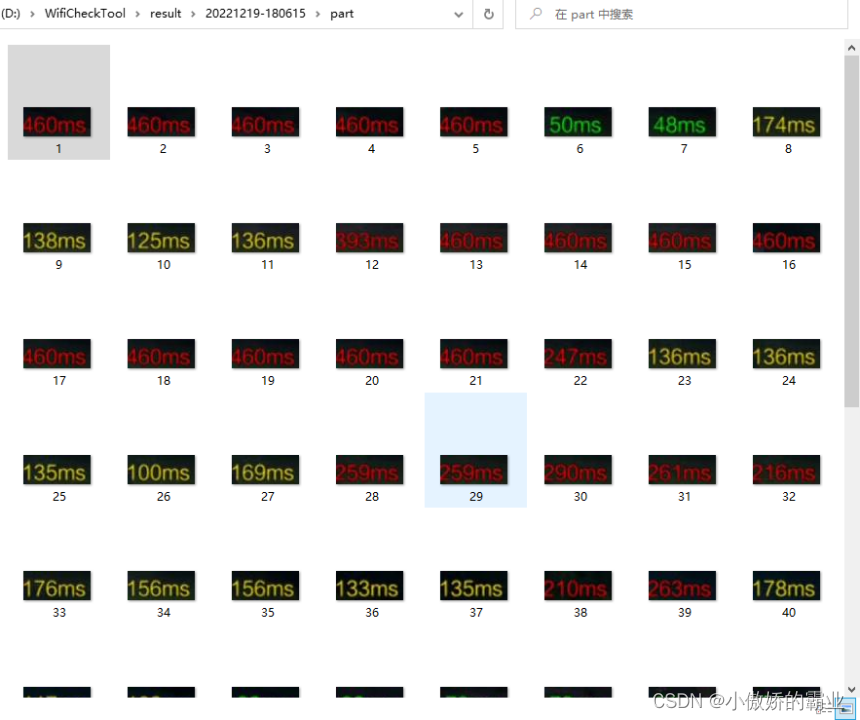
步骤二:实现二次截取并保存到本地文件夹,HSV颜色模型识别红色,即延时超过200ms时的字体颜色。
img_assert.py
#!/usr/bin/env python
# coding=utf-8
import os
import time
import tempfile
import pytesseract
from functools import reduce
import cv2
from PIL import Image
PATH = lambda p: os.path.abspath(p)
TEMP_FILE = PATH(tempfile.gettempdir() + "/temp_screen.png")
TEMP_FILE_NEW = PATH(tempfile.gettempdir())
class ImageAssert(object):
@staticmethod
def get_screenshot_by_custom_size(video_file_dir, i, phone_type):
# 自定义截取范围
start_x = 0
start_y = 0
end_x = 0
end_y = 0
# M1
if phone_type == 1:
start_x = 1900
start_y = 5
end_x = 1969
end_y = 35
# M2
if phone_type == 2:
start_x = 2025
start_y = 5
end_x = 2100
end_y = 35
# M3
if phone_type == 3:
start_x = 2025
start_y = 5
end_x = 2100
end_y = 35
# IQOO11
if phone_type == 4:
start_x = 300
start_y = 1040
end_x = 376
end_y = 1070
file_img = PATH(video_file_dir + "\\" + str(i) + ".jpg")
box = (start_x, start_y, end_x, end_y)
image = Image.open(file_img)
newImage = image.crop(box)
if not os.path.exists(video_file_dir + "\\part\\"):
os.makedirs(video_file_dir + "\\part\\")
newImage.save(video_file_dir + "\\part\\" + str(i) + ".jpg")
# print(video_file_dir + "\\part\\" + str(i) + ".jpg")
@staticmethod
def pic_ocr(video_file_dir, i):
# 识别时延
file_img_path = video_file_dir + "\\part\\" + str(i) + ".jpg"
# 加载图片
rawImage = cv2.imread(file_img_path)
# 灰度
gray = cv2.cvtColor(rawImage, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
# 识别
string = pytesseract.image_to_string(binary, lang='eng', config='--psm 7 ')
print("帧数: " + str(i) + " 时延: " + string)
return string
@staticmethod
def pic_color_ocr(video_file_dir, i):
import cv2
import numpy as np
img = cv2.imread(video_file_dir + "\\part\\" + str(i) + ".jpg")
# 在彩色图像的情况下,解码图像将以b g r顺序存储通道。
grid_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 从RGB色彩空间转换到HSV色彩空间
grid_HSV = cv2.cvtColor(grid_RGB, cv2.COLOR_RGB2HSV)
# 红色H、S、V范围一:
lower1 = np.array([0, 43, 46])
upper1 = np.array([10, 255, 255])
mask1 = cv2.inRange(grid_HSV, lower1, upper1) # mask1 为二值图像
# res1 = cv2.bitwise_and(grid_RGB, grid_RGB, mask=mask1)
# 红色H、S、V范围二:
lower2 = np.array([156, 43, 46])
upper2 = np.array([180, 255, 255])
mask2 = cv2.inRange(grid_HSV, lower2, upper2)
# res2 = cv2.bitwise_and(grid_RGB, grid_RGB, mask=mask2)
# 将两个二值图像结果 相加
mask3 = mask1 + mask2
# # 结果显示
# cv2.imshow("mask3", mask3)
# print(str(cv2.countNonZero(mask3)))
if cv2.countNonZero(mask3) > 500:
print("第 " + str(i) + "张图片" + str(cv2.countNonZero(mask3)))
# print('Red is present!')
# print("第 " + str(i) + "张图片,卡顿次数 +1")
return True
else:
# print('Red is not present!')
return False
步骤三:调用二次截取时延部分图片及识别图片的接口
img_check.py
import os
from src.img_assert import ImageAssert
PATH = lambda p: os.path.abspath(p)
class CheckImage(object):
@staticmethod
def check_img(image_save_dir, video_file):
video_file_dir = image_save_dir + video_file
pic_count = os.listdir(video_file_dir)
# print("sum pic: " + str(len(pic_count)))
pic_count = len(pic_count)
delay_frame_num = 0 # 卡顿帧数
delay_flag = 0
delay_times = 0
# 识别是手机型号
phone_type = -1
if "M1" in video_file:
phone_type = 1
elif "M2" in video_file:
phone_type = 2
elif "M3" in video_file:
phone_type = 3
elif "IQOO" in video_file:
phone_type = 4
for i in range(1, pic_count):
# 裁切图片只保留时延部分
ImageAssert.get_screenshot_by_custom_size(video_file_dir, i, phone_type)
# 识别时延
is_delay = ImageAssert.pic_color_ocr(video_file_dir, i)
if is_delay:
if delay_flag == 0 or delay_flag == 2:
delay_times += 1
# print("第 " + str(i) + "张图片开始一段卡顿,卡顿次数 +1")
delay_frame_num += 1
delay_flag = 1
else:
delay_flag = 2
i += 1
print("#" * 100 + "\n视频名称:" + video_file + "\n视频时延总时长: " + str(delay_frame_num) + "\n视频卡顿次数: " +
str(delay_times))
print("#" * 100)
return pic_count, delay_frame_num, delay_times
运行结果
main.py
主程序调用进行多线程统计并输出测试结果
import os
import threading
import time
from src.img_check import CheckImage
from src.video2pic import Video2images
# 预期存储在的主文件夹,即'result'文件夹
image_save_dir = '/WifiCheckTool/result/'
# 需要转换的视频路径列表,直达视频文件(自定义修改)
video_path_list = ['/WifiCheckTool/source/']
class WifiVideoCheck:
@staticmethod
# 视频按帧转换为图片
def video2images(file_name, video_path, every_video_save_dir):
Video2images.videos2images(file_name, video_path, image_save_dir, every_video_save_dir)
@staticmethod
# 统计总帧数、卡顿帧数、卡顿次数
def check_delay(video_file):
CheckImage.check_img(image_save_dir, video_file)
def run(self):
for video_path in video_path_list:
files_in_video_path_list = os.listdir(video_path)
for file_in_video_path in files_in_video_path_list:
file_name, every_video_save_dir = Video2images.mkdir_file(file_in_video_path, image_save_dir)
threading.Thread(target=self.video2images, args=(file_name, video_path, every_video_save_dir, )).start()
is_start = True
while is_start:
time.sleep(5)
length = len(threading.enumerate())
# print('当前运行的线程数为:%d' % length)
if length <= 1:
time.sleep(5)
files_in_video_path_list = os.listdir(image_save_dir)
for video_file in files_in_video_path_list:
threading.Thread(target=self.check_delay, args=(video_file, )).start()
is_start = False
if __name__ == '__main__':
wifiVideoCheck = WifiVideoCheck()
wifiVideoCheck.run()总结
本次分享为了给测试小伙伴们一些自动化测试的思路,例如:在测试第三方软件时不支持查看源码或测试场景按常规方法不易判断的情况下,可以考虑将python图像识别技术应用到自动化测试中。















 6856
6856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









