







1. slurm集群调度系统简介
作业调度系统其实就是指按一定策略把并行程序的各子任务或者是面向多用户的一组作业按一定的选择策略使之与各计算节点的空闲资源相对应,让其在对应的资源上运行,所以作业调度系统是联系上层应用和下层资源的中枢。一个集群资源的利用是否合理,各计算节点的负载是否均衡,以及各用户的用户体验是否良好都与作业调度系统息息相关,集群的资源管理及作业调度系统可谓是集群发展的重中之重。
Slurm是一个开源,高度可扩展的集群管理工具和作业调度系统,可以简单理解为一个多机的资源和任务管理系统。主要以下提供三种关键功能:
**资源分配:**在特定时间段内为用户分配计算资源,进行独占或非独占访问权限,以便他们可以执行作业。简单的说就是为用户作业提供对计算资源的授权和分配。
**作业管理:**它提供了对节点上的作业节进行启动、执行和监控作业的框架。
**作业调度:**通过管理待处理作业的队列来仲裁资源的争用。例如根据优先级或不同调度策略调整资源的分配顺序。
Slurm调度系统中针对作业的调度主要有三种,主调度,回填调度,GANG调度。在之前的《slurm 集群调度策略详解(1)- 主调度》文章中,介绍了主调度的一些相关知识,本篇文章主要针对slurm中的回填调度进行解析。
2. 回填调度
2.1 回填调度算法简介
常见的先来先服务作业调度方法,实现简单、实用性很强。然而,为了保证公平性原则,当需要调度一个资源需求较大而现有空闲资源不能满足的大作业时,往往需要为其预留资源,这就容易产生大量闲置的资源碎片。
回填算法,其允许为大作业预留资源的同时,也会将预约过程中产生的资源碎片进行分配;就是说可以让作业等待队列中排在后面的小作业跳过预约资源的大作业先于该大作业被调度执行,这样既避免了大作业长时间得不到调度而产生饥饿现象又可以让资源碎片得到充分利用,其能够很大程度上提高作业的平均响应时间,增加系统集群的吞吐量以及资源利用率。
目前,回填策略有很多种实现模式,比较典型的有Easy Backfilling和Conservative Backfilling两种策略算法,其它基于回填的调度策略的研究基本上都是在这两种策略基础上的微调。
2.1.1 Easy Backfilling
EasyBackfilling算法是一种比较“激进”的回填算法,它仅仅要求回填后的作业不会搁置等待队列第一个作业(触发资源预留的作业)的执行就行,而不去考虑在其他任何在等待队列中排在其前面的作业。
假设每个作业都可以由一个二元组(cpu核数需求,预计执行时间)来描述,则Easy Backfilling算法的整个执行过程如下步骤所述:
1.在资源时空图(横坐标为时间,纵坐标为CPU核数)中寻找作业的插入点以及对应的剩余CPU核数。
① 对于每个运行中的作业,都可以算出预计完成时间,根据这个截止时间对所有正在运行的作业进行排序。
② 在资源时空图中寻找剩余CPU核数可以满足等待队列中第一个作业的CPU核数需求的最早的一个时间点, 这个时间点就是与该队列首作业job1对应的插入点。
③ 插入点对应的时刻,集群剩余CPU核数将更新(原值减去作业job1的需求核数)。
2.遍历等待队列中的作业,寻找一个可以被回填的作业。
① 对每一个作业进行检查,看其是否满足下列条件中的一个。
1)该作业需求的CPU核数小于当前时刻集群剩余的CPU核数,并且预计能够在插入点之前运行完毕(不延
迟作业job1的调度执行)。
2)该作业需求的CPU核数小于或等于min(当前集群空闲的CPU核数,当前系统剩余的CPU核数)。
*注:集群的空闲CPU核数与系统剩余CPU核数是不一样的,空闲CPU核数是对应时刻集群真实的闲置的
_ CPU核数,而剩余CPU核数是回填决策后资源时空图的剩余CPU核数。_
② 选择第一个满足以上条件的作业作为回填作业。
3.随着时间实时更新资源时空图,重复以上两个步骤,不停进行回填决策。
这种算法前瞻性不足,回填决策时只考虑回填作业是否延误等待队列中第一个作业的执行,这就很容易导致作业执行的不可预测性,导致等待队列前面的一些作业响应时间非常长。
2.1.2 Conservative Backfilling
Conservative Backfilling算法是相对于Easy backfilling来说非常“保守”的一种回填调度策略。这种策略当选取等待队列中某个作业进行回填时,该被选中的作业必须保证不能延迟所有在队列中排在其前面的作业的执行,这种回填策略的优点在于:如果作业预计的执行时间比较准确,那么队列中作业的开始执行时间都是可预见的,从而可以给每个作业所属用户一个公平性保证。同样,Conservative Backfilling算法的执行过程可以描述成如下几个步骤:
1.顺序地确定等待队列中各作业的插入点。
① 对当前的资源时空图进行遍历,找到满足该作业CPU核数需求的第一个时问点,该时间点即为该作业对应 的插入点。
② 从该作业对应的插入点开始,遍历资源时空分布图,检查集群剩余CPU核在该作业执行完毕前的这段时内 是否一直可以满足该作业的执行资源需求。
③ 如果在作业执行完之前有段时间剩余CPU核数不满足该作业资源需求,则继续在资源时空分布图中往后遍 历,直到为该作业找到一个满足条件的作业插入点。
2.每当为一个作业确定插入点后,得实时更新资源时空分布图以反映该作业调度后的资源分配情况。
3.每个作业在其对应的插入点时刻开始被调度执行。
通常Conservative Backfilling回填是更被广泛认可的,因为计算资源的有偿使用,计算平台在保证服务水平协议的情况下尽可能保证所有用户之间的公平性也是非常重要的。
总而言之,在高性能计算环境中,回填调度是一种高效、易于实现且很重要的一类调度算法。在将新作业加入队列时,考虑以下两个因素:
- 当前队列中正在运行的作业;
- 队列中等待运行的作业。
回填调度算法的主要目的是通过利用系统的空闲资源来减少作业的等待时间,提高系统的资源利用率。它适用于需要提供快速响应时间的环境,例如,高性能计算和分布式系统等。
2.2 回填调度在slurm中的应用
回填调度在slurm中采用基于Conservative Backfilling的算法,通过插件的形式来提供服务。slurmctld服务在启动时,默认或根据配置项SchedulerType=sched/backfill进行回填调度插件的加载。在没有回填调度的情况下,每个分区都严格按照作业优先级顺序进行调度,一旦一个分区中的任何作业或作业数组任务因为资源不足处于排队状态时,该分区中的任何其他低优先级作业都不会被调度,这通常会导致资源利用率低和作业调度效率低等问题。
回填调度充分利用大作业排队的时间间隙,在不会延迟任何较高优先级大作业预期开始时间的前提下,将优先调度低优先级的小作业启动运行。回填调度的使用,将提高小作业的响应时间,而且提高系统资源的利用率。
slurm中主调度和回填调度对于相同作业的调度结果,如图1所示:
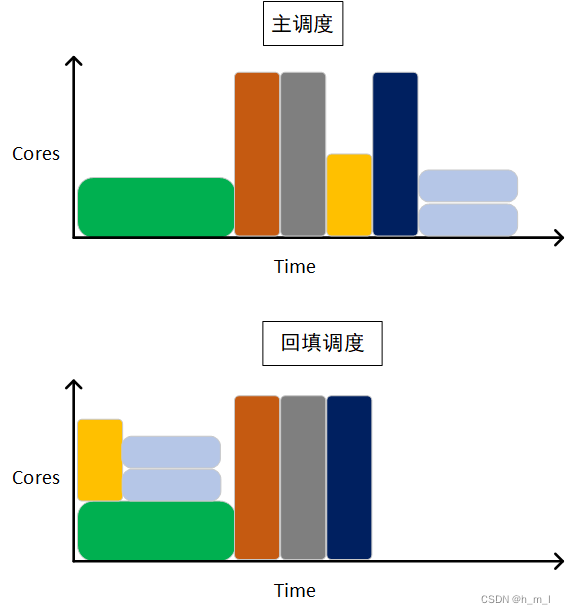
图1 主调度和回填调度对于相同作业的调度结果
3. 回填调度参数
在slurm中,使用SchedulerType配置参数指定要使用的调度器插件:选项有sched/backfill(执行回填调度)和sched/builtin(试图在每个分区/队列中严格按照优先级顺序调度作业);使用SchedulerParameters配置参数,可以指定更多与调度规则相关的选项。
按照参数功能,可以将回填调度相关的参数分为以下几类:
- 回填调度行为相关配置项
- 回填预留条件相关配置项
- 回填深度相关配置项
- 回填广度相关配置项
- 回填调度锁机制相关配置项
下面对于每类配置项进行详细的介绍。
3.1回填调度行为相关配置项
在slurm中,回填调度是一个周期行为,每两次回填之间的间隔、每次回填考虑的时间窗口长度、回填考虑的时间分辨率、异构作业的处理等都是由回填调度行为相关配置项来决定的,具体配置项如下表所示。
| 参数 | 解释 |
|---|---|
| assoc_limit_stop | 如果设置,作业由于关联限制而无法启动,那么将作业所在分区加入分区黑名单,不要尝试在该分区中启动任何低优先级的作业。设置该值会降低系统吞吐量和利用率,但可以防止低优先级作业运行导致高优先级作业饿死。 |
| bf_busy_nodes | 当为排队的作业选择资源以预留给将来执行时(例如,作业不能立即启动),优先选择当前不空闲的节点,以便留出更多的空闲节点用于回填运行时间较长的作业。 |
| bf_hetjob_immediate | 回填调度程序在确定异构作业所有组件都能够启动后,立即尝试启动该作业。否则,将延迟异构作业的启动尝试,直到处理完队列的其余部分。 |
| 默认情况下,该选项是禁用的。如果启用并没有设置bf_hetjob_prio=min,那么将自动设置。 | |
| bf_hetjob_prio | 在每个回填调度周期的开始,将根据PriorityType中配置的优先级顺序,对待调度的排队作业列表进行排序。此选项将保证来自同一异构作业的所有组件将被视为具有相同的优先级(最小、平均或最大取决于该选项的参数),从而被连续调度(不会在结果列表中片段化)。 |
| 在相同的异构作业中,将保留原来的顺序。 | |
| bf_interval | 相邻两次回填调度之间的间隔秒数,更高的值会导致更少的开销和更好的响应。 |
| 默认值为30,Min:1,Max:10800(3小时)。 | |
| bf_resolution | 当回填调度为作业计算预期的开始和结束时间时的时间分辨率(单位:秒)。较大的时间分辨率会导致更好的响应性和更快的回填周期。但是,较高的值会导致系统规划的效率降低,并且可能会错过提高系统利用率的机会。 |
| 默认值:60,最小值:1,最大值:3600(1小时)。 | |
| bf_running_job_reserve | 为回填逻辑添加一个额外的步骤,这将为在整个节点上运行的作业创建回填预留。默认情况下,该选项是禁用的。 |
| bf_window | 回调调度在确定作业何时何地可以开始时,要往后看多长时间。值越大,开销越大,响应性越差。通常建议设置一个不小于作业最高时间限制的值,以防止作业饥荒。为了限制回填调度程序管理的数据量,如果bf_window的值增加了,那么通常建议也增加bf_resolution。 |
| 默认值:1440min(1天),Min:1,Max: 43200(30天)。 | |
| bf_window_linear | 由于性能的原因,回填调度程序会降低作业预期终止时间的计算精度。bf_window_linear以秒为单位,在每次迭代中使时间间隔增加一个常量。如果没有这个选项,时间窗口将在每次迭代中加倍。对于同时执行的作业超过几百个,不推荐使用bf_window_linear。 |
| max_rpc_cnt | 如果slurmctld守护进程中的活动线程数等于或大于这个值,则推迟作业调度。这可以提高Slurm处理请求的能力,但需要降低启动新作业的频率。 默认值:0(不启用),Min: 0, Max: 1000。 |
| bf_max_job_array_resv | 回填调度为作业数组保留资源的的最大任务数。 |
| 默认值:20,Min: 0, Max: 1000。 |
3.2 回填预留条件相关配置项
回填调度主要是在没有空闲资源时,为高优先级的作业进行资源的回填预留,以保证高优先级作业能够在尽可能少的等待时间里得到资源去运行。作业能否被创建回填预留,与以下回填预留条件配置项相关:
| 参数 | 解释 |
|---|---|
| bf_job_part_count_reserve | 回填调度将为每个分区中指定数目的最高优先级的作业保留资源。 |
| 默认值为0,这将导致为高优先级的作业预留资源和低优先级的延迟启动工作。默认值:0,Min: 0,Max: 100000。 | |
| bf_min_age_reserve | 回填调度预留时间参数,当高优先级作业因空闲资源不足未成功运行,且低优先级作业排队的时间小于bf_min_age_reserve,则不会为高优先级的作业创建回填预留,而是尝试调度低优先级的作业。默认值为零,这将为任何排队的作业保留资源,并延迟低优先级作业的启动。 |
| 默认值:0,Min: 0, Max: 2592000(30天)。 | |
| bf_min_prio_reserve | 回填调度预留优先级参数,当高优先级作业因空闲资源不足未成功运行,且低优先级排队作业的优先级不小于bf_min_age_reserve时,则不会为高优先级的作业创建回填预留,而是尝试调度低优先级的作业。默认值为零,这将为任何排队的作业保留资源,并延迟低优先级作业的启动。 |
| 默认值:0,Min: 0, Max: 2^63。 | |
| bf_one_resv_per_job | 不允许为每个作业添加多个回填预留。提交到多个分区的作业在列表中具有与请求的分区相同的条目。让一个作业为多个分区保留资源可能会妨碍其他作业(或hetjob组件)。这个选项使得提交给多个分区的作业,在第一个分区进行回填预留后将停止其他分区预留资源。 |
| 默认情况下,该选项是禁用的。 | |
| bf_running_job_reserve | 为回填逻辑添加一个额外的步骤,这将为在整个节点上运行的作业创建回填预留。默认情况下,该选项是禁用的。 |
3.3 回填深度相关配置项
每轮回填持续多久、回填多少作业之后退出等,是由回填深度相关配置项决定的,具体配置参数如下表所示:
| 参数 | 解释 |
|---|---|
| bf_max_job_test | 每轮回填调度尝试的最大作业数。值越大,开销越大,响应性越差。作业在被尝试回填调度之前,它的预期起始时间值不会被设置。在大型集群中,推荐配置一个相对较小的值。 |
| 默认值:500,Min:1,Max:1,000,000。 | |
| bf_max_time | 每轮回填调度可以持续的最大时间(以秒为单位,包括释放锁时所花费的睡眠时间),即使尝试回填的作业数没有达到bf_max_job_test,该轮回填调度也将停止。 |
| 默认值:bf_interval(30 秒),Min: 1, Max: 3600 (1h)。 | |
| bf_max_job_start | 在回填调度的一次调度周期中,可以启动的最大作业数。 |
| 默认值:0(无限制),Min: 0, Max: 10000。 |
3.4 回填广度相关配置项
每轮回填每个分区能够尝试多少作业、每个用户能够尝试多少个作业等,是由回填广度相关配置项决定的,具体配置参数如下表所示:
| 参数 | 解释 |
|---|---|
| bf_max_job_user_part | 对于任何单个分区,回填调度可以尝试的每个用户的最大作业数。 |
| 默认值:0(无限制),Min: 0, Max: bf_max_job_test。 | |
| bf_max_job_user | 对于所有分区,回填调度可以尝试的每个用户的最大作业数。 |
| 默认值:0(无限制),Min: 0, Max: bf_max_job_test。 | |
| bf_max_job_part | 对于任何单个分区,每轮回填调度尝试的最大作业数。这对于具有大量分区和作业的系统尤其有帮助。 |
| 默认值:0(无限制),Min: 0, Max: bf_max_job_test。 | |
| bf_max_job_assoc | 回填调度可以尝试的每个用户关联的最大作业数。 |
| 默认值:0(无限制),Min: 0, Max: bf_max_job_test。 |
3.5 回填锁机制相关配置项
回填调度是一个很耗时的操作,在回填调度时会持有作业和节点的写锁;调度流程之外与作业和节点相关的操作都会被阻塞,调度系统的待处理事件会快速累积。因此,slurm在进行回填调度时,会定期进行锁的释放,以便系统能处理其他请求。多久释放一次锁、每次释放多长时间、释放锁之后是否要继续之前的回填调度等,都是由以下表格中与锁机制相关配置项决定的。
| 参数 | 解释 |
|---|---|
| bf_continue | 回填调度程序定期释放锁,以便允许其他操作继续进行。该参数将导致回填调度程序在释放锁后,继续回填调度。 |
| bf_yield_interval | 回填调度程序将定期释放锁,以便其他排队的操作发生。该参数指定回填调度开始后多久释放锁(以微秒为单位的长度)。 |
| 默认:2,000,000(2秒),Min: 1, Max: 10,000,000(10秒)。 | |
| bf_yield_sleep | 回填调度程序将定期释放锁,以便其他排队的操作发生。该参数指定锁释放后的持续时间(以微秒为单位的长度)。 |
| 默认值:500,000(0.5秒),Min: 1, Max: 10,000,000(10秒)。 |
对于每个配置项,slurm都会根据经验给出默认值;实际使用时,需要根据集群大小、用户作业特征等情况,进行配置项的调整,以便得到最适合自己集群的回填调度效果。例如:集群节点较多、用户作业运行时间一般较长时,需要尽可能调大回填调度考虑的时间窗口bf_window,才能使回填调度真正起作用。
4. 回填调度流程
Slurm默认选择sched/backfill作为调度插件;为了提高调度效率,集群一般也都会配置sched/backfill。
回填调度的流程,主要涉及到插件的初始化、待调度作业列表的构建、作业的调度尝试、资源的时间表格构建、锁的释放等工作。
4.1 回填调度插件初始化流程
在slurmctld服务启动时,根据SchedulerType配置项,来进行调度插件的加载和初始化。
如图2所示,为回填调度插件的加载流程:
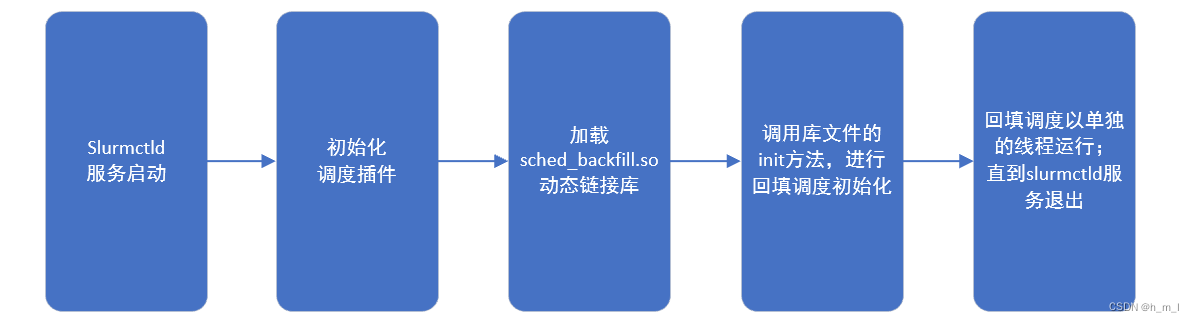
图2 回填调度插件的加载流程
在回填调度插件的init函数中,进行回填调度线程的创建;大致的函数调用关系如下:
main // slurmctld - controller.c
slurm_sched_init // 调度插件初始化
plugin_context_create // 插件上下文的创建
plugin_load_and_link // 插件加载和链接
plugin_load_from_file // 从文件中加载插件
init = dlsym(plug, "init") // 调用插件的初始化函数
slurm_thread_create(&backfill_thread, backfill_agent, NULL); // 创建回填调度的线程
在回填调度线程函数backfill_agent中,以while (!stop_backfill)的形式一直运行,直到slurmctld服务退出;在循环的内部,通过判断当前时间与上次回填调度结束时间的间隔是否大于backfill_interval,来决定是否开启新的一轮回填调度。
回填调度线程函数backfill_agent的大致执行流程如图3所示:
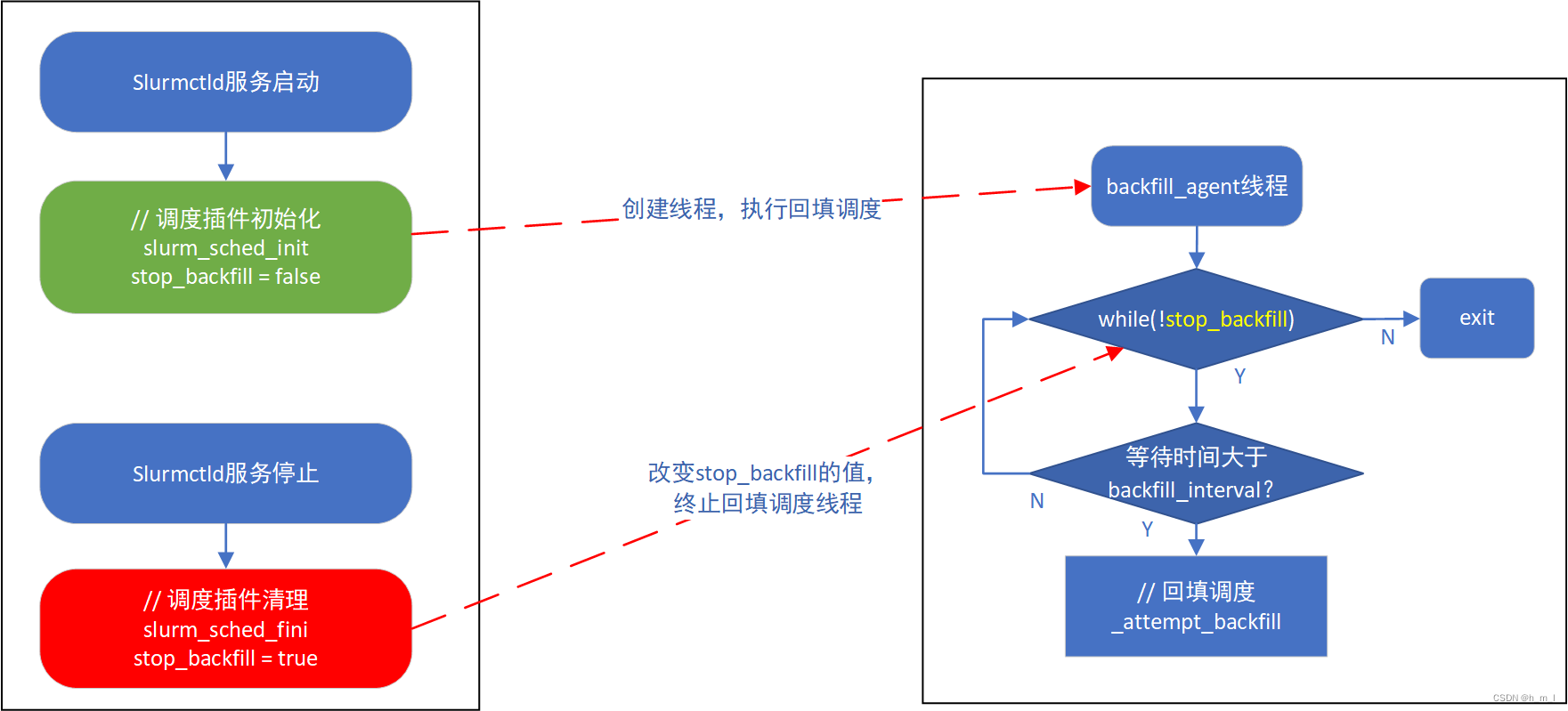
图3 回填调度线程的创建和退出流程图
4.2 待调度作业列表的构建
在每轮回填调度_attempt_backfill中,首先会进行待调度作业列表job_queue的构建。构建方法为:
① 遍历全局的job_list列表(当前调度系统中所有状态的作业集合),将所有排队状态的作业的预期启动时间start_time进行清除;
② 对于提交到多个分区的作业,会创建与指定分区数相同多的待调度作业;
③ 添加待调度作业到job_queue中;
④ 按照优先级从高到低的顺序,将job_queue中的作业进行排序;
至此,完成待调度作业列表的构建。
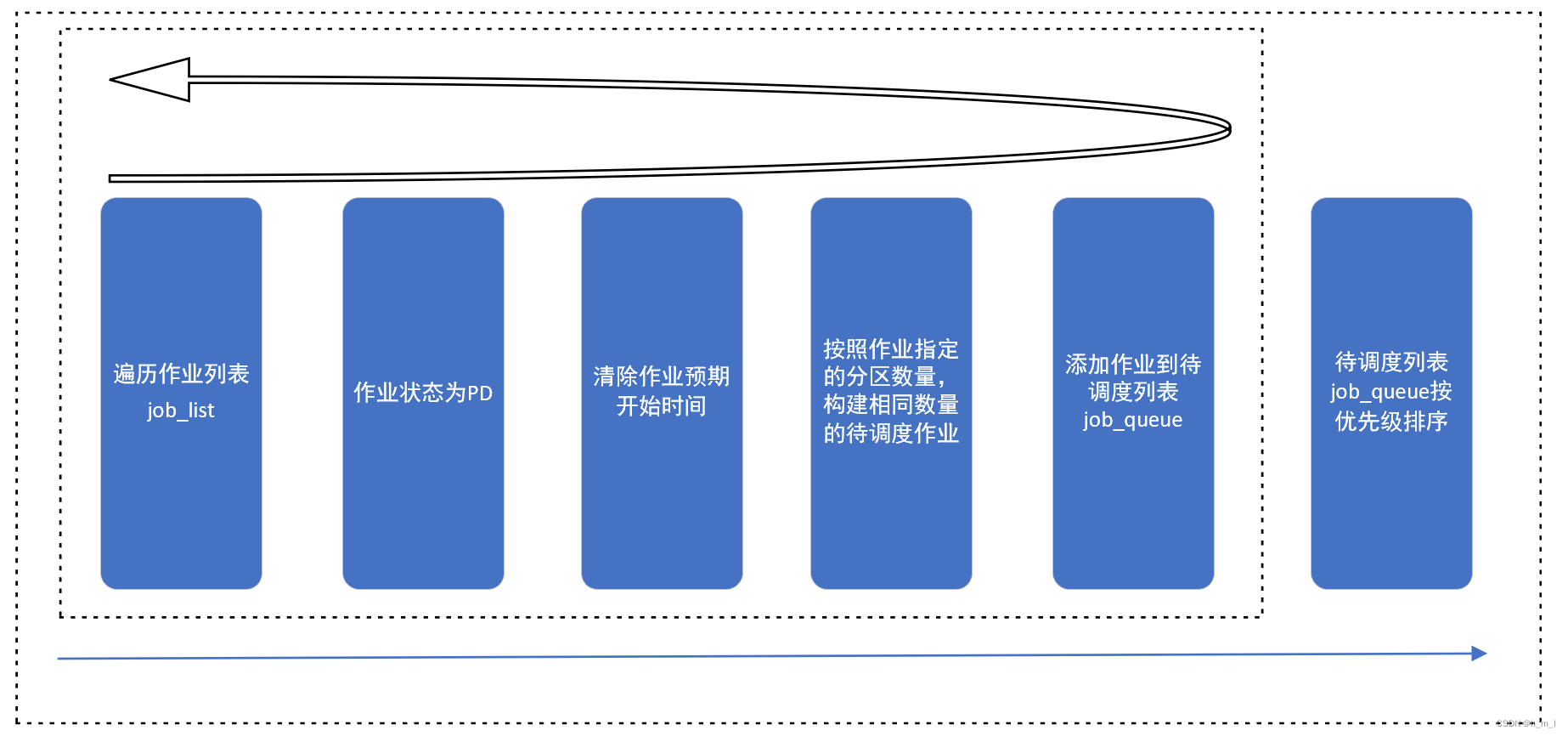
图4 待调度作业列表的构建流程
4.3 作业尝试回填调度
在作业回填调度之前,调度系统会对所有回填调度相关的参数进行解析;随后待调度作业会按照优先级从高到低的顺序从job_queue中出栈;出栈后的作业会经过调度参数和作业自身限制的筛选,最终进入节点选择和启动环节。回填调度的主流程如图5所示:
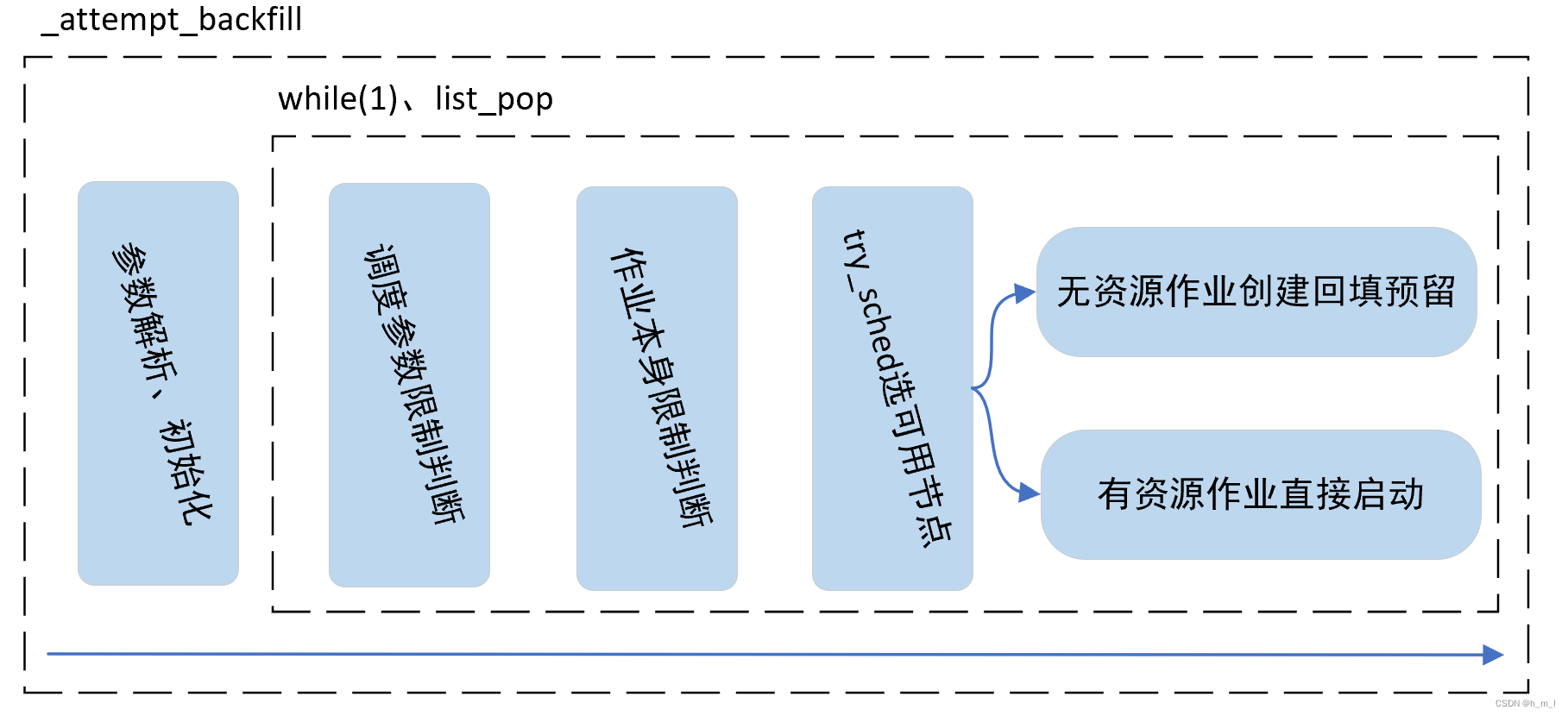
图5 回填调度的主流程
Slurm 的回填调度程序会考虑每个正在运行的作业;然后按优先顺序考虑排队的作业,确定每个作业何时何地开始,同时考虑作业抢占的可能性、gang调度、通用资源 (GRES) 要求、内存要求等。
作业在提交时,会根据作业指定的time limit参数或者分区配置的time limit参数,来为作业设置时间限制time limit。由于排队作业的预期开始时间取决于正在运行作业的预期完成时间,因此作业在提交时制定一个合理准确的时间限制(time limit)对于回填调度的正常运行非常重要。
如果正在回填调度的作业立即启动而不会影响任何更高优先级作业的预期开始时间,则该作业会启动运行;否则,回填插件将为排队的作业设置预期开始时间,该作业所需的资源将在作业的预期执行时间内被预约。
4.4 节点资源的时间表格构建
在slurm的回填调度中,会为排队作业计算预期启动时间和结束时间;在合适的计算节点上对应预期时间段内,为作业进行资源预留。出于性能原因,即使作业不需要整个节点,回填调度也会为作业保留整个节点。相当于将计算节点资源按照时间顺序,进行表格的构建:在不同的时间段内,将节点预留给不同的作业。
在回填调度最开始时候,所有可用的计算节点处在同一时间表格中,时间段的长度由配置项bf_window决定。
// 时间表格开始时间:当前轮次回填调度开始时间
node_space[0].begin_time = sched_start;
// 由backfill_window配置项决定结束时间
window_end = sched_start + backfill_window;
node_space[0].end_time = window_end;
// 所有可用的节点,都将被考虑
node_space[0].avail_bitmap = bit_copy(avail_node_bitmap);
当前有包含8个可用节点(node[1-8])的集群,下面举例说明提交申请不同节点作业时候,对于节点资源时间表格的构建过程(基于slurm20.11.8版本)。
(1)按顺序提交申请不同节点数量的作业
a. sbatch -N 6 --exclusive -t 24:00:00 test.job // 申请6个节点并独占, 时间限制为24小时
b. sbatch -N 3 --exclusive -t 12:00:00 test.job // 申请3个节点并独占, 时间限制为12小时
c. sbatch -N 4 --exclusive -t 12:00:00 test.job // 申请4个节点并独占, 时间限制为12小时
d. sbatch -N 2 --exclusive -t 10:00:00 test.job // 申请2个节点并独占, 时间限制为10小时
(2)主调度为job1分配资源
Allocate JobId=188287 NodeList=node[1-6]
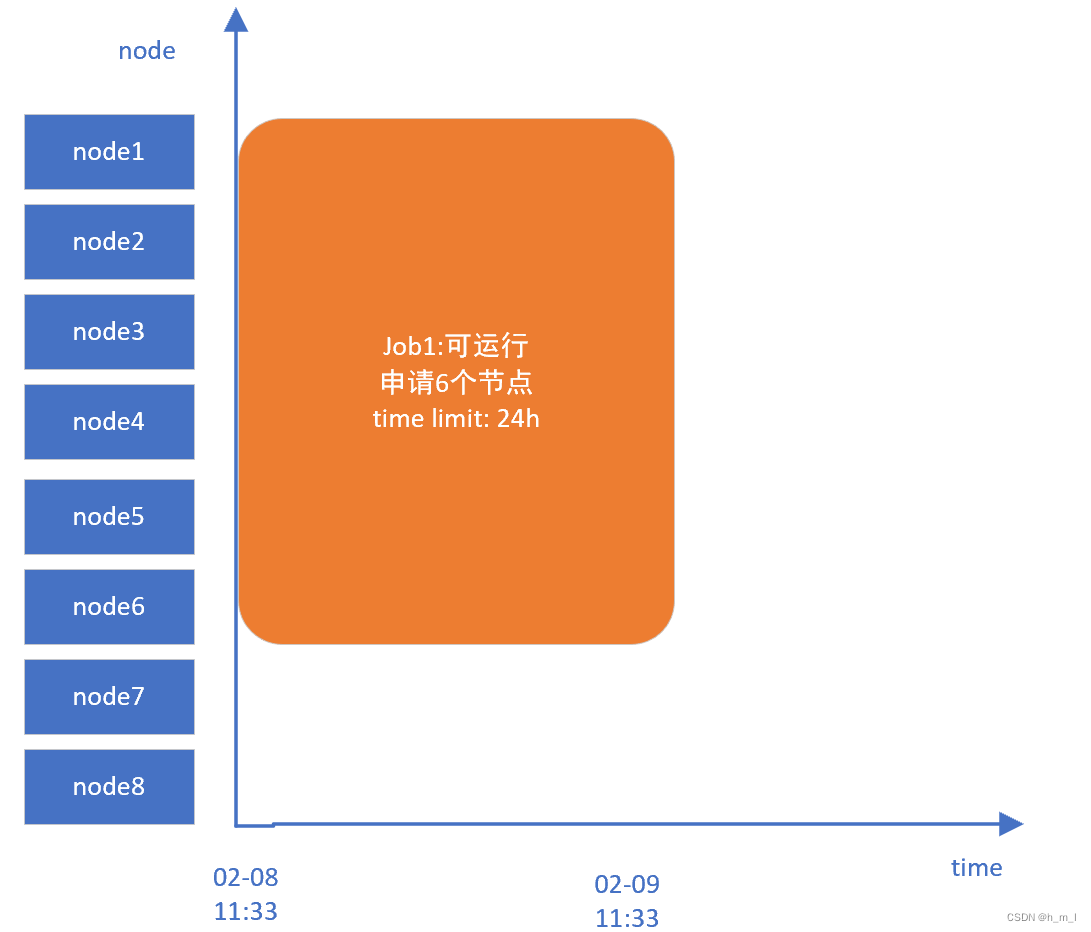
图6 job1资源分配示意图
(3)当前空闲资源不足,主调度无法为job2选出合适资源,job2排队;
空闲资源不满足job2运行,回填调度为job2预约资源;
// 构建节点资源时间表格 bf_window=43200 (30天)
_dump_node_space_table: Begin:2023-02-08T11:33:35 End:2023-03-10T11:33:35 Nodes:node[1-8]
// 在当前时间段可用节点上,进行探测
_dump_job_test: Test JobId=188288 at 2023-02-08T11:33:35 on node[1-8]
// 根据当前在运行作业的time limit,计算job2的开始时间;根据job2的time limit,计算结束时间
_dump_job_sched: JobId=188288 to start at 2023-02-09T11:33:24, end at 2023-02-09T23:33:00
on nodes node[1-3] in partition debug
// 为所有可用节点重新划分时间表格,表示在以下时间段内,对应的节点未被回填调度预约:
_dump_node_space_table: Begin:2023-02-08T11:33:35 End:2023-02-09T11:33:00 Nodes:node[1-8]
_dump_node_space_table: Begin:2023-02-09T11:33:00 End:2023-02-09T23:33:00 Nodes:node[4-8]
_dump_node_space_table: Begin:2023-02-09T23:33:00 End:2023-03-10T11:33:35 Nodes:node[1-8]
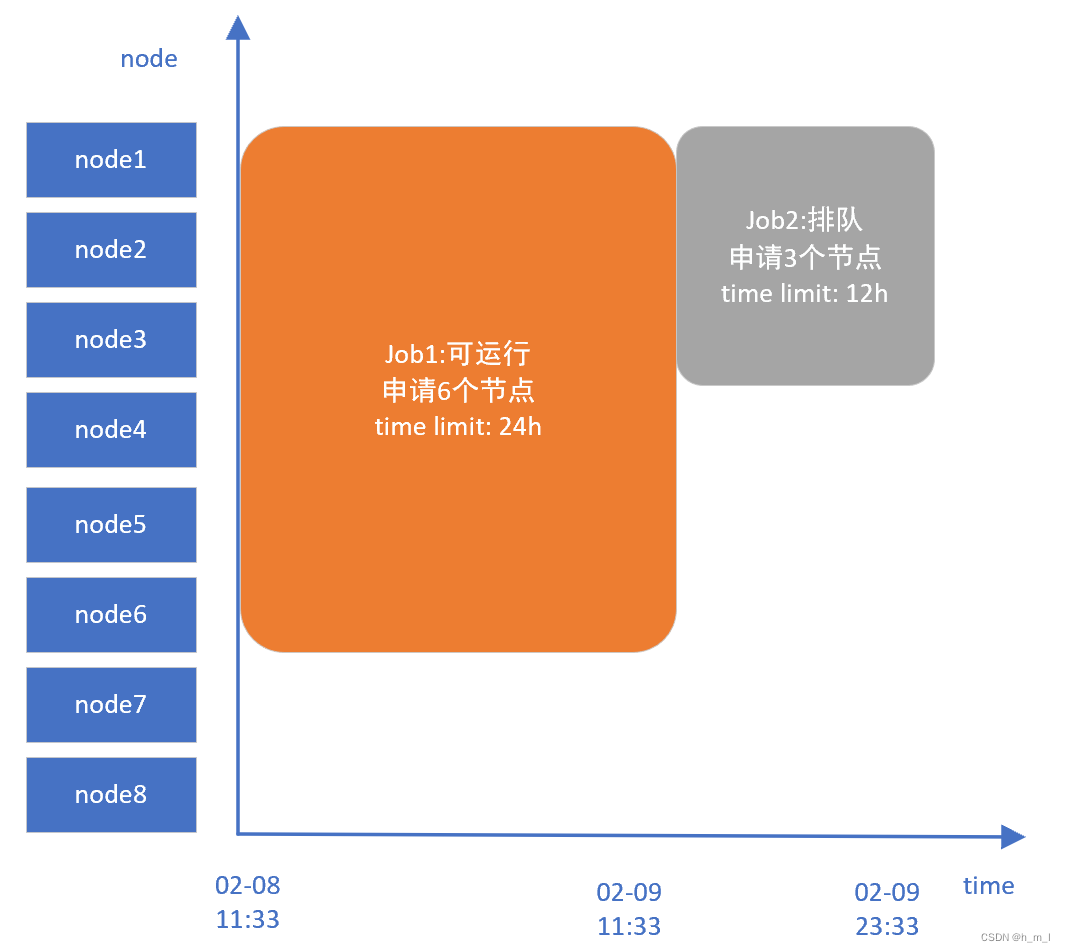
图7 job2回填预留示意图
(4)当前空闲资源不足,主调度无法为job3选出合适资源,job3排队;
空闲资源不满足job3运行,回填调度为job3预约资源;
// 构建节点资源时间表格 bf_window=43200 (30天)
_dump_node_space_table: Begin:2023-02-08T11:33:43 End:2023-03-10T11:33:43 Nodes:node[1-8]
// 在当前时间段可用节点上,进行探测
_dump_job_test: Test JobId=188289 at 2023-02-09T11:33:24 on node[4-8]
// 根据当前在运行作业的time limit,计算job3的开始时间;根据job3的time limit,计算结束时间
_dump_job_sched: JobId=188289 to start at 2023-02-09T11:33:24, end at 2023-02-09T23:33:00
on nodes node[4-7] in partition debug
// 为所有可用节点重新划分时间表格,表示在以下时间段内,对应的节点未被回填调度预约:
_dump_node_space_table: Begin:2023-02-08T11:33:43 End:2023-02-09T11:33:00 Nodes:node[1-8]
_dump_node_space_table: Begin:2023-02-09T11:33:00 End:2023-02-09T23:33:00 Nodes:node8
_dump_node_space_table: Begin:2023-02-09T23:33:00 End:2023-03-10T11:33:43 Nodes:node[1-8]
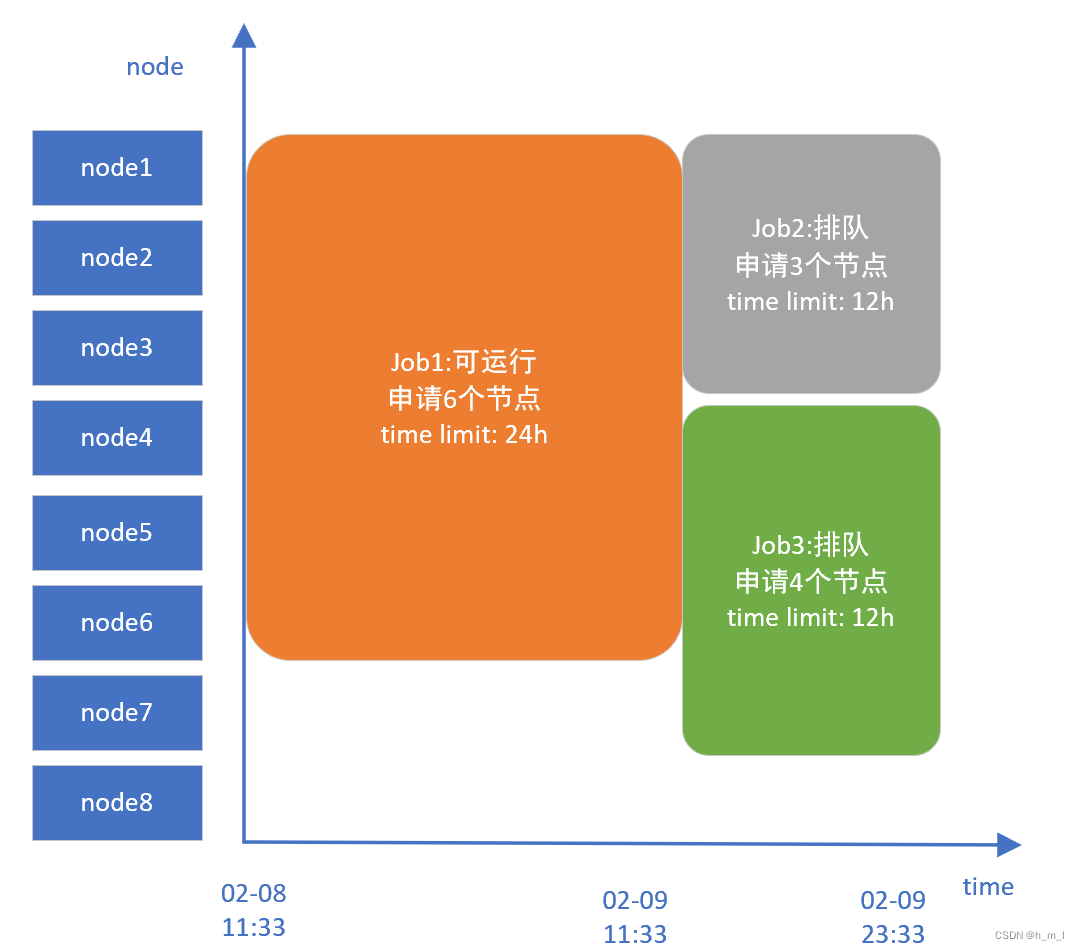
图8 job3回填预留示意图
(5)存在高优先级作业因为资源不足而排队,主调度无法为job4分配资源,job4排队;
当前空闲资源满足job4运行,且不影响job2、job3的启动时间,回填调度为job4分配资源并启动运行;
// 构建节点资源时间表格 bf_window=43200 (30天)
_dump_node_space_table: Begin:2023-02-08T11:33:49 End:2023-03-10T11:33:49 Nodes:node[1-8]
// 在当前时间段可用节点上,进行探测
_dump_job_test: Test JobId=188290 at 2023-02-08T11:33:49 on node[1-8]
// 发现可用的资源
_start_job: Started JobId=188290 in debug on node[7-8]
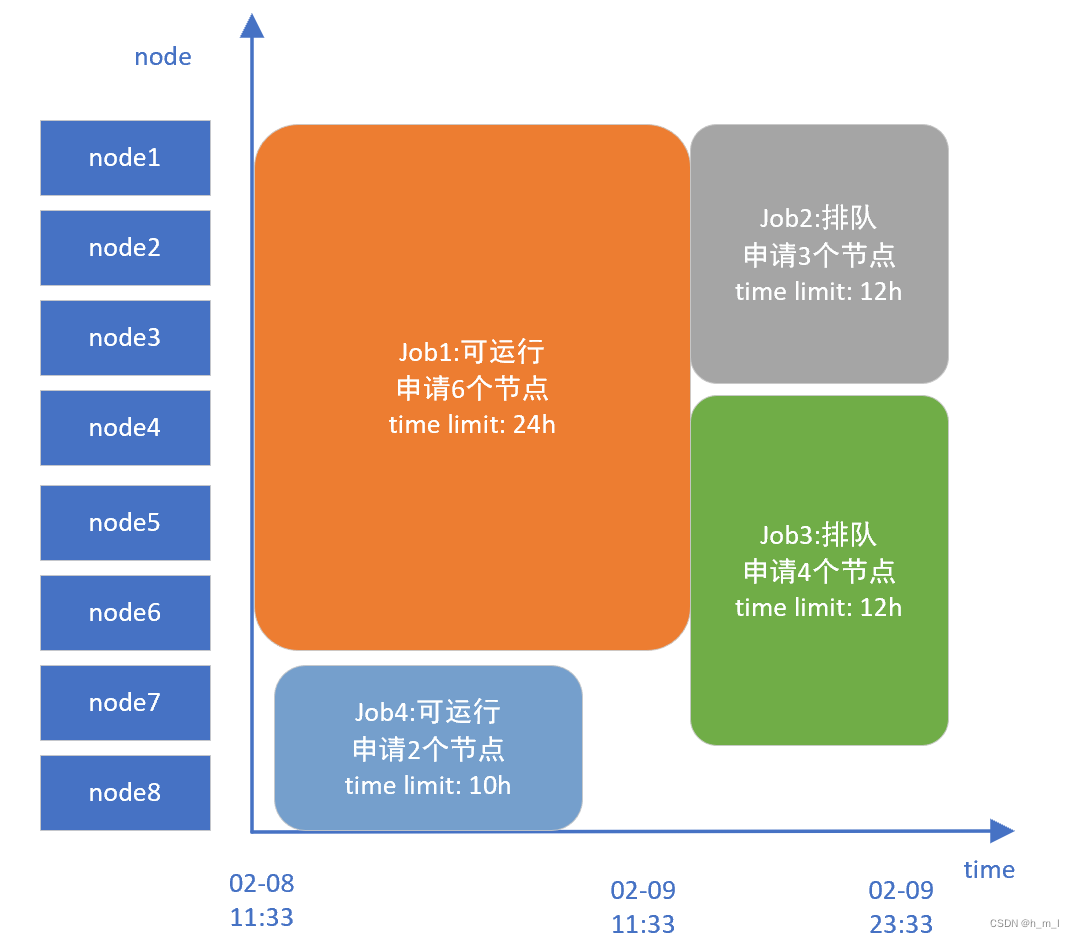
图9 job4回填选择资源示意图
资源的时间表格构建,依赖于作业的预期启动时间和结束时间。回填调度构建待调度作业列表时,会将排队作业的预期启动时间清除,以便于在接下来的回填调度中,为其赋上重新计算得到的预期启动时间。
4.5 回填调度的节点选择
在对一个作业进行回填调度时,会先进行尝试调度;根据尝试调度的结果,分为三种情况来处理:
- 当前有足够的空闲资源运行该作业;申请对应的资源,启动作业立即运行;
- 当前没有足够空闲资源运行该作业,但在回填考虑的时间窗口内,有合适的资源可以创建回填预留;为该作业创建回填预留;
- 当前没有足够空闲资源运行该作业,在回填考虑的时间窗口内,没有合适的资源可以创建回填预留;不考虑为该作业创建回填预留;
回填调度的大致流程如图10所示:
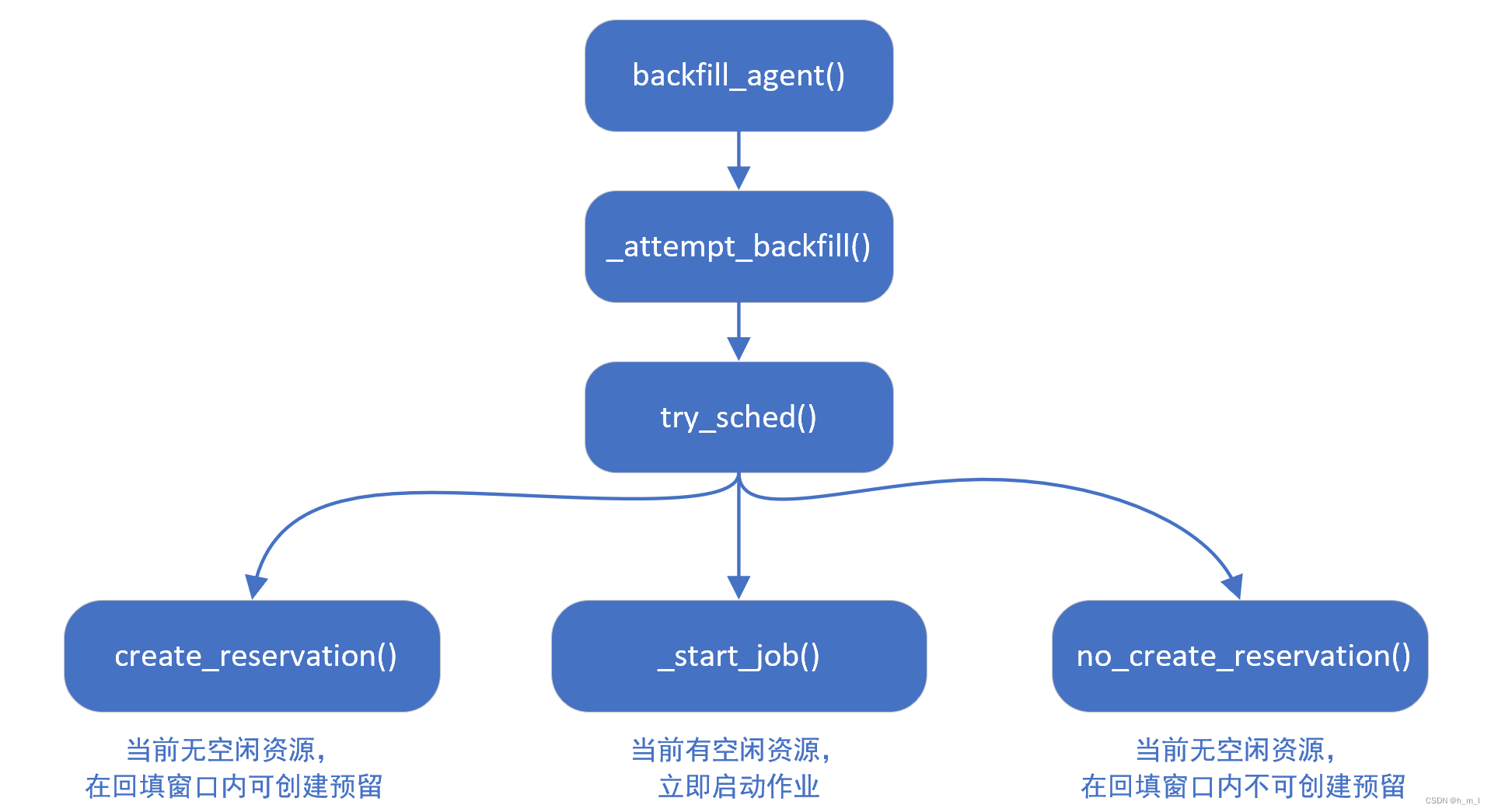
图10 回填调度的大致流程
在回填调度流程中,如果没有空闲资源能够立即启动作业,则在合适的节点上,根据时间表格,计算作业的预期启动时间和结束时间,并在相应的节点上进行回填预留的创建。
若有空闲资源能够满足作业要求,通过select_nodes函数,在当前空闲资源中选择符合作业申请资源的最佳节点,并启动作业去运行。具体流程如图11所示。
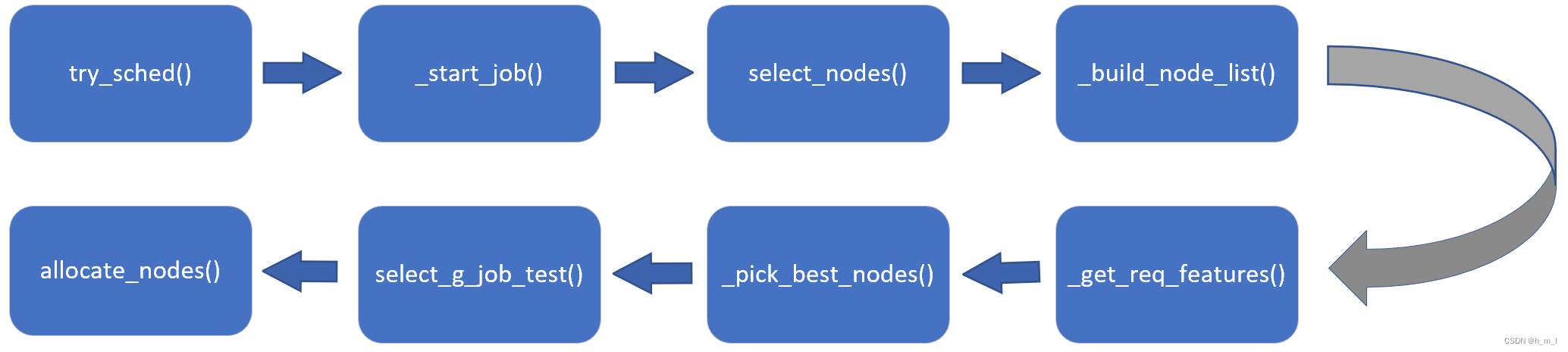
图11 回填调度节点选择流程示意图
流程解析:
- 构建具有必要配置的节点表(node_set_ptr:包含slurm_node.conf中所有节点);每个表格条目包括它们的权重、节点列表、特征等;
- 调用_pick_best_nodes,从满足作业规格的所有节点的权重顺序列表中,选择“最佳”以供使用;
- 如果指定了必需的节点列表,则确定隐式必需的处理器和节点数;
- 确定表示了多少不相交的必需“feature”(例如“FS1 | FS2 | FS3”);
- 对于每个feature:查找匹配的节点表条目,识别可用的节点(空闲或共享),并将它们添加到全局的节点bitmap中;
- select_g_job_test(),根据拓扑和/或工作负载选择其中的“最佳”; 最佳”定义为连续节点的最小数量,或者如果共享资源,则使用类似大小的作业共享资源。
- 如果现在无法满足请求,请对存在于任何状态(DOWN DRAINED ALLOCATED)的节点列表执行select_g_job_test(),以确定是否能够满足请求;
- 调用allocate_nodes,执行实际分配节点;
4.6 回填调度的锁机制
回填调度是一项耗时的操作。在回填调度过程中,持有配置文件和分区的读锁、作业和节点的写锁。此时,调度流程之外与作业和节点相关的操作都会阻塞住。
/* Read config and partitions; Write jobs and nodes */
slurmctld_lock_t all_locks = {
READ_LOCK, WRITE_LOCK, WRITE_LOCK, READ_LOCK, READ_LOCK };
lock_slurmctld(all_locks);
(void) _attempt_backfill();
last_backfill_time = time(NULL);
unlock_slurmctld(all_locks);
默认情况下,锁每两秒短暂释放一次,以便可以处理其他选项,例如处理新的作业提交请求。回填调度可以选择在锁释放后继续执行并忽略新提交的作业 ( SchedulerParameters=bf_continue )。这样做将考虑原有待调度作业列表中更多作业被调度,但可能会导致新提交的作业被延迟调度。
回填调度以while (1) 循环运行,每次调度1个作业,直至满足退出的条件,while(1)循环被打破,回填调度结束;在调度作业之前,会进行判断是否要进行锁的释放。
触发锁释放有两个条件:
- 系统当前累积的未处理RPC线程数大于max_rpc_cnt(一般为255);
- 回填调度持续的时间大于yield_interval;
当以上任意一个条件满足时,进入_yield_locks(yield_sleep)函数;在该函数内首先进行锁的释放,随后等待当前系统累积未处理的RPC线程数小于yield_rpc_cnt时,再次持有锁,并退出该函数;回填调度流程此时根据是否配置 SchedulerParameters=bf_continue,来决定继续进行回填调度流程或者退出回填调度的while(1)循环,结束本次回填调度。
回填调度释放锁的机制流程,如图12所示:
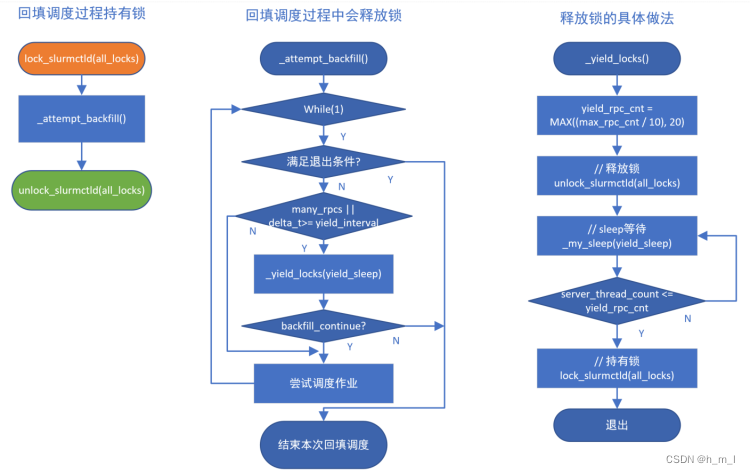
图12 回填调度释放锁的机制流程
流程图中提到的回填调度退出条件,主要与3.3节中提到的回填深度配置有关。回填调度退出条件如下所示:
(1)待调度作业列表中的作业已全部被调度;
(2)slurmctld服务退出;
(3)回填调度的时间超过了最大允许的调度时间bf_max_time;
(4)锁释放之后,没有配置backfill_continue;
(5)回填调度启动的作业数已超过bf_max_job_start;
(6)回填调度尝试的作业数已经大于bf_max_job_test;
(7)所有分区回填调度尝试的作业数大于bf_max_job_part;
(8)待调度作业列表中,回填调度为每个用户尝试的作业数大于bf_max_job_user;
(9)待调度作业列表中,回填调度为每个assoc尝试的作业数大于bf_max_job_assoc;
(10)待调度作业列表中,回填调度为每个分区每个用户尝试的作业数大于bf_max_job_user_part;
5. 回填调度优化
5.1 实际场景中遇到的问题
slurm使用回填调度算法,目的是提高碎片化资源的利用率,进而提高集群资源的利用率。但实际的使用场景中,从集群管理员、集群用户、调度系统开发者不同角色的角度来看,仍存在很多问题。
5.1.1 集群管理员角度
从集群管理员的角度,主要是希望能将回填调度的效果发挥出来,充分利用好集群的资源。但是面对回填调度的一堆配置参数,经常不知道怎么得到适合自己集群的配置项,例如:
(1)回填的时间窗口bt_window设置为多久比较合适?
(2)分区配置里的作业时间限制DefaultTime、MaxTime、OverTimeLimit应该怎么设置?
(3)回填调度深度相关的配置项应当怎么设置,才能保证对不同队列不同用户都比较公平?
(4)如何利用锁机制配置来均衡回填的吞吐量和系统的响应速度?
5.1.2 集群用户角度
当用户提交作业到集群上时,希望能够利用回填调度将自己的作业快速调度运行;那么在提交作业时,就需要为作业指定合适的时间限制time limit参数(-t, --time=
5.1.3 调度系统开发者角度
回填调度过程中,会持有作业和节点的写锁,阻塞调度线程之外所有与作业和节点相关的操作,如作业提交、节点状态查询等;此时,调度系统将不能快速响应。
从调度系统的开发者角度来看,希望回填调度的吞吐量和调度系统的响应速度之间达到一个均衡的状态。避免因为频繁的回填调度,导致调度系统卡死;或者为了调度系统的快速响应,将回填调度时间间隔设置的较大,导致仅有极少的作业能通过回填来分配到合适的资源。
从开发人员的角度,存在着这样一些疑问:
(1)回填调度的效率是否可以进行优化?
(2)怎样提高回填调度的资源利用率?
5.2 优化方案
针对当前回填调度中遇到的问题,提出以下优化方案。
5.2.1 回填调度相关配置参数的设置
回填调度充分利用大作业排队的时间间隙,在不会延迟任何较高优先级大作业预期开始时间的前提下,将优先调度低优先级的小作业启动运行。因此,启用回填调度,会导致实际运行作业的顺序,与排队作业优先级顺序不完全符合,低优先级的小作业可能会先于高优先级大作业运行。
若集群要严格按照优先级顺序来调度作业,则不适合开启回填调度。
回填调度各个配置参数生效位置如图13所示:
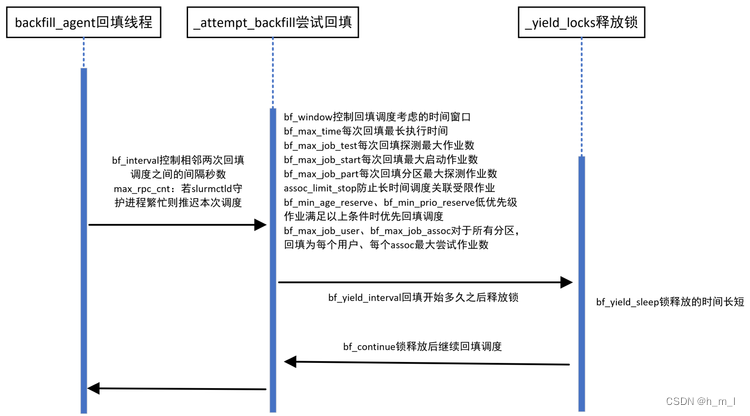
图13 回填调度各个配置参数生效位置图
回填调度各个参数在调度中不同的位置发挥不同的作业,但是相互之间有着间接的联系,在不场景下可以通
过不同的参数对调度进行限制,参数优化方案如下:
- 回填的时间窗口bt_window与回填分辨率bf_resolution
bt_window通常建议使用最高时间限制一样长的值43200(30天);bf_resolution值越小,系统开销越大,应随着bt_window增大而增大;如集群节点较多,推荐bf_resolution设置为3600(1小时)。
- 兼顾回调调度的吞吐量和调度系统响应速度
回填调度期间会持有作业和节点写锁,频繁的回填调度、长时间的回填调度都会导致调度系统的卡顿;锁机制则时刻监控系统的繁忙程度,当回填持续时间达到释放锁的时间bt_yield_interval或系统过于繁忙,则暂停回填,释放锁去处理调度外部请求。
一般的集群,可以按照持有锁的时间:释放锁的时间=4:1的比例来配置,即bf_yield_interval=2000000(2秒),bf_yield_sleep=500000(0.5秒),bf_continue。若集群比较繁忙,可以适当减小持有锁的时间:释放锁的时间比例为2:1,例如bf_yield_interval=1000000(1秒),bf_yield_sleep=500000(0.5秒)。
保持bf_yield_sleep配置为0.5秒不变,根据集群的情况,通过调整bf_yield_interval和bf_yield_sleep的比例,来兼顾调度系统的响应速度和回填调度的吞吐量。
- 兼顾回填的整体深度和分区深度
每轮回填调度能探测/启动多少作业,是回填调度的整体深度bf_max_job_test;每轮调度为每个分区探测/启动多少个作业是回填调度的分区深度bf_max_job_part。整体深度太大,回填耗费的时间过长,会在达到bf_max_time时退出,整体深度配置不起作用;分区深度太大,会导致会提前调度的时间都花在某个分区中,其他分区作业得不到调度;因此,应当结合实际的情况,来进行分区深度和整体深度的设置。
一般对于较繁忙的集群,设置bf_interval=120(2分钟),max_rpc_cnt=500,bf_max_time=60(1分钟),bf_yield_interval=1000000(1秒),bf_yield_sleep=500000(0.5秒),bf_continue。
例如3个有1200节点的分区,完整回填一个作业耗费的时间是0.02秒,当作业因为配额不足而被hold或者资源不足时,所花时间仅为0.002秒。按照1个作业被回填处理的时间为(0.02+0.002)/2 = 0.011秒,则估算:
bf_max_job_test=( ((60/(1+0.5)*1 )/ 0.011) = 3636。
则每个分区的探测作业数bf_max_part_test = bf_max_job_test / 分区数量 = 3636/3 = 1212。
如果分区之间的节点数量和作业数量差距较大,在设置bf_max_part_test时,可以稍微偏向于节点数更多、作业更多的分区情况。
- 分区的作业时间限制设置
在全局和分区的配置中,支持以下与作业时间限制相关的配置项:
- DefaultTime - 默认作业时间限制(按分区配置)
用于为未指定time limit值的作业设置运行时间限制。如果未设置,则将使用MaxTime。
- MaxTime - 最大作业时间限制(按分区配置)
如果未设置,则为UNLIMITED。
- OverTimeLimit - 作业在取消之前可以超过其时间限制的分钟数(支持全局配置和按分区配置)
默认值为0,不得超过65533分钟;还支持配置UNLIMITED。通常,作业的时间限制被视为硬性限制,一旦达到该限制,工作将被终止。配置OverTimeLimit将导致作业的时间限制被视为软限制。当作业达到时间限制后,可再运行OverTimeLimit值对应的分钟数,随后作业若还未结束则将被取消。
当用户作业在集群上运行时,一般是按照核时来进行收费,应当避免出现因为分区的时间限制配置导致用户的作业超时被杀。因此,一般集群的分区DefaultTime设置的较长,例如100天,DefaultTime=100-00:00:00,MaxTime=UNLIMITED,OverTimeLimit=0。
此时,如果用户在提交作业时不指定time limit,则集群的回填调度基本不会有效果。
5.2.2 作业time limit值的预测
从用户角度来说,对于作业预期执行时间的计算,大概分为两类方法:(1)根据同类历史作业的大致运行时间来设置经验值;(2)使用机器学习等方法来进行作业运行时间的预测。
方法1:根据同类历史作业的大致运行时间来设置经验值
slurm提供了sacct命令来查询作业的历史记录,作业运行结束后可用sacct命令查看作业执行时间Elapsed等情况,下次提交同类作业以此为参考选择合理的时间限制。
$ sacct -j 30790015 -o jobid,jobname,start,end,elapsed
JobID JobName Start End Elapsed
------------ ---------- ------------------- ------------------- ----------
30790015 vasp 2023-02-11T08:58:56 2023-02-11T14:33:47 05:34:51
30790015.ba+ batch 2023-02-11T08:58:56 2023-02-11T14:33:47 05:34:51
30790015.ex+ extern 2023-02-11T08:58:56 2023-02-11T14:33:47 05:34:51
30790015.0 vasp_std 2023-02-11T08:59:06 2023-02-11T14:33:47 05:34:41
同样类型,同样资源请求的作业,可根据该类型历史作业的平均用时Elapsed来获取该类型作业的运行时间经验值,在作业提交时,设置作业的time limit。
除sacct命令外,slurm还提供了seff命令来进行历史作业资源使用情况和运行时间的统计。当下次提交同类作业以此为参考选择合理的资源和时间限制。
$ seff 10010
Job ID: 10010
Cluster: cluster_test
User/Group: slurmtest/slurmtest
State: COMPLETED (exit code 0)
Nodes: 2
Cores per node: 16
CPU Utilized: 1-15:14:19
CPU Efficiency: 99.53% of 1-15:25:20 core-walltime
Job Wall-clock time: 01:13:55
Memory Utilized: 1.05 GB (estimated maximum)
Memory Efficiency: 3.37% of 31.25 GB (1000.00 MB/core)
方法2:使用机器学习等方法来进行作业运行时间的预测
当前有很多国内外的学者和研究人员使用机器学习等方法来进行作业运行时长的预测,例如:基于遗传算法的作业时长预测[1]、基于BRBF算法对于vasp作业时长的预测[2]和基于分类和实例学习相结合的作业运行时间预测算法[3]等。
可以通过上述或者其他算法来对同类型的历史作业数据进行训练,得到作业运行时长的预测值,进而在提交作业时,为作业设置time limit。
5.2.3 回填调度自身的优化
对于slurm中回填调度的设计,也存在着可以优化的地方。例如:对同一类资源请求的作业,进行重复调度导致的回填效率低;回填调度的粒度在节点级别,易造成资源的浪费等。从调度系统开发者的角度,对回填调度的优化思路如下所示:
(1)避免重复调度
当某个用户批量提交资源占用相同的一些作业时,若前面的作业因为资源不足不能在回填窗口内预约到合适资源,回填调度仍会去尝试该用户后续的作业,寻求合适的节点。显而易见,该用户后面的作业,也都不能在回填窗口内预约到合适资源。相当于回填调度在做一些重复而无用的工作。
以上是一种简单且常见的场景,还有其它类似的场景会出现相同的现象。针对回填调度,增加避免重复调度的模块,当待调度队列前面的作业因资源不足不能在回填窗口内预约到合适资源时,待调度队列后面与之申请资源相同的作业,不必为其执行调度,直接跳过即可。
(2)回填调度的粒度细化
出于性能原因,即使作业不需要整个节点,回填调度也会为作业保留整个节点,这将导致回填调度的粒度较粗,集群资源得不到充分的利用。可以尝试将回填调度的粒度从节点级别细化到CPU级别,以此来提高回调调度的效果,提高集群资源的利用率。但是回填粒度的细化,必然将导致回填速率的下降。
6. 总结
- 主调度是slurm调度系统中的最主要调度策略,按照优先级顺序快速调度,保证了集群的响应速度、吞吐量、和调度速率。
- 回填调度作为主调度以外的辅助调度策略,主要提高资源利用率和作业调度效率。
- 合理准确的时间限制(time limit)对于回填调度的良好运行非常重要。没有合理的作业时间限制,回填调度的成功率是很低的。
7. 参考文献
[1]许伦凡,熊敏,肖永浩.基于调度历史数据在线预测作业执行时间[J].计算机应用研究,2020,37(03):763-767.DOI:10.19734/j.issn.1001-3695.2018.08.0624.
[2]吴桂宝. 面向回填优化的vasp作此执行时间预测的研究[D].中国科学技术大学,2018.
[3]肖永浩,许伦凡,熊敏.GA-Sim:一种基于分类和实例学习相结合的作业运行时间预测算法[J].计算机工程与科学,2019,41(06):987-992.
Slurm 调度系统是当前调度系统中少有的开源且成熟的调度系统,但是仍然有少量 bug 的存在,且不能完全覆盖所有的用户场景,如果您有问题请加入社区讨论。社区以 Slurm 为切入口讨论 HPC 相关问题,致力于守卫中国 HPC 集群稳定运行,推广国产调度器助力中国 HPC 进步。联系方式请私信。

















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









