







## 正则表达式概述 ##
正则表达式,又称正规表达式,正规表示法。(Regular Expression) 代码中通常简称为regex,正则表达式用耽搁字符串来描述,匹配一系列匹配的某个句法规则的字符串,在文本编辑器中通常用来检索和,替换匹配文本。
re模块
早Python中需要通过正则表达式对字符串进行匹配的时候,我们会用到re模块。名字RE
1.RE模块的使用过程
#导入re模块
import re
result=re.match('正则表达式',要匹配的字符串)
#如果要上一步匹配的数据,调用group方法来取得。
result.group()
re.match是用来进行正则匹配和检查的方法,若字符串能够匹配正则表达式。则match方法返回匹配对象(match object),否则返回none(注意不是空字符)
匹配对象有一个Match object又一个group方法,用来返回字符串的匹配部分。
2.re模块示例(匹配以itcast开头的语句)
#导入re模块
import re
result=re.match('itcast','itcast.cn')
#如果要上一步匹配的数据,调用group方法来取得。
print(result.group())
3说明
re.match()能够匹配出以xxx开头的字符串。
#导入re模块
import re
result=re.match('itcast','itcast.cn')
#如果要上一步匹配的数据,调用group方法来取得。
print(result.group())
m='c:\\a\\b\\c'
ret1=re.match(r'c:\\a',m).group()
ret2=re.match('c:\\\\a',m).group()
print(ret1)
print(ret2)说明python字符串前面加上r表示原生字符串。
与大多数的编程语言相同,正则表达式使用’\’作为转义字符,这就可能造成反斜杠的困扰。假如你要匹配字符串中的’\’,那么python重就需要4个反斜杠。
python中的原生字符串就很好的解决这个问题,有了原生字符串,再也不用担心漏写反斜杠。写出来的表达式也更加的直观。
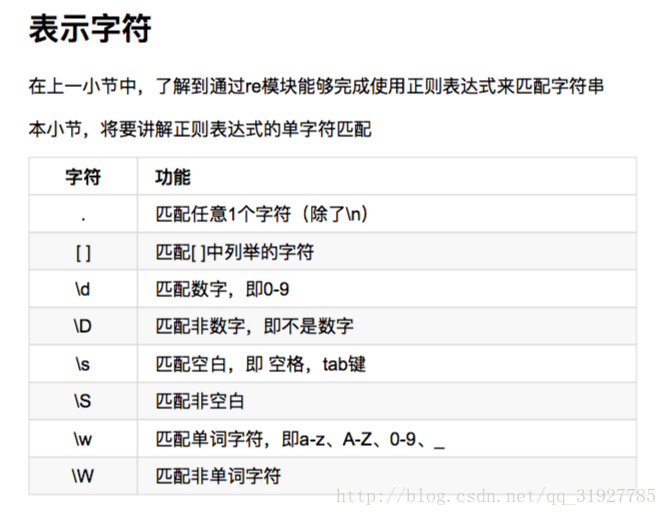
表示数量

#导入re模块
import re
ret=re.match('[A-Z][a-z]*','Mn')
print(ret.group())
ret1=re.match('[a-zA-Z]+[\w_]*','name')
print(ret1.group())
ret2=re.match('[a-zA-Z]+[\w_]*','_name')
print(ret2.group())
# ret3=re.match('[a-zA-Z]+[\W_]','2name')
# print(ret3.group())例如我们来匹配一个手机号码。
ret3=re.match(‘1[35678]\d{9}’,’13618646855’)
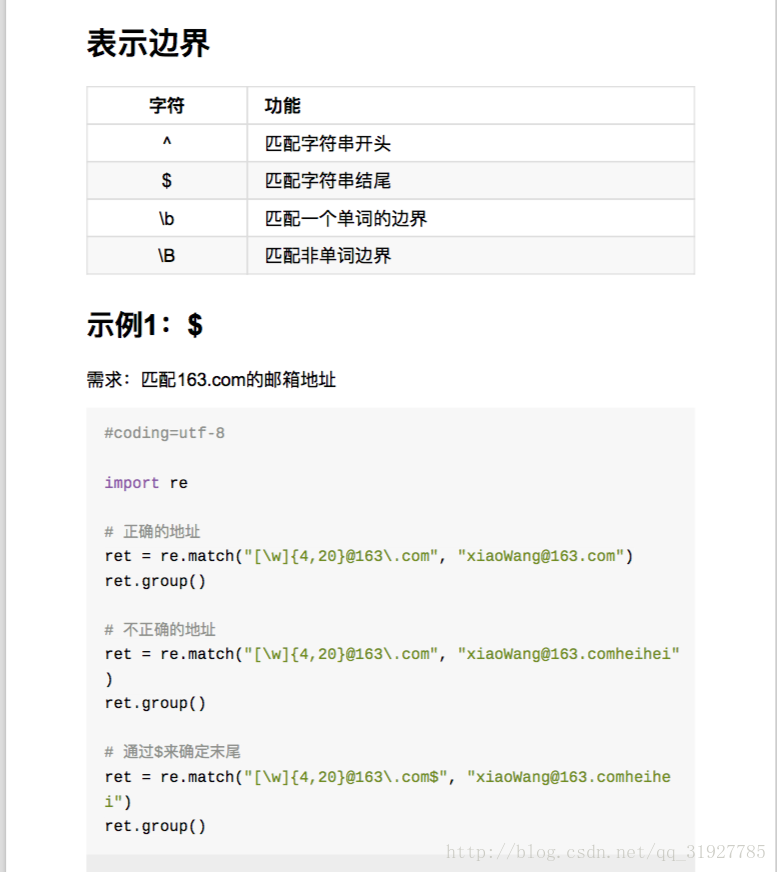
表示边界
匹配分组
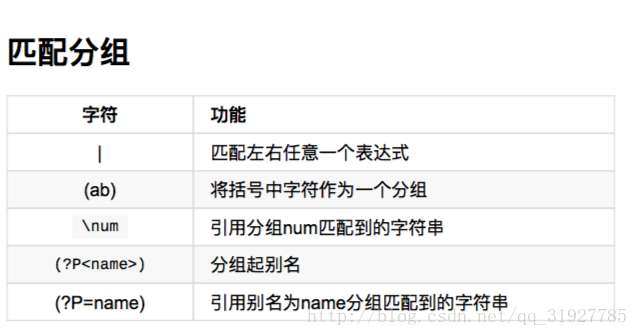
代码示例;匹配出0到100之间的数字。
import re
ret1=re.match(r'[1-9]?\d?$|100$','87')
print(ret1.group())#导入re模块
import re
# patterm=re.compile(r'\d+')
# #match是从字符串开始找。
# m=patterm.match('aaa1243bbb345')
# m1=patterm.match('aaa123bbb456',3,5)
# print(m1.group())
#pattern.match():从起始位置开始往后查找,返回一个符合规则的
#pattern.search():从任何位置开始查找
#pattern.findall()所有全部匹配,返回列表。
#pattern.finditer():所有全部匹配返回一个迭代器
#pattern.split()分割列表,返回列表
#patterrn.sub()替换。
#忽略大小写。
pattern=re.compile(r'([a-z]+) ([a-z]+)',re.I)
m2=pattern.match('Hello world hello Python')
print(m2.group())
print(m2.group(1))
pattern2=re.compile(r'\d+')
ret2=pattern2.search(r'aaa123bbb456',2,6)
ret3=pattern2.search('hello 123456 789')
print(ret2.group())
print(ret3.group())
#findall他返回是一个列表,下面执行结果[123,456,789]
ret4=pattern2.findall('hello 123 456 789')
print(ret4)
pattern3=re.compile(r'\d?')
ret5=pattern3.findall('hello 123 456 789')
print(ret5)
pattern4=re.compile(r'[\s\d\\\;]+')
m=pattern4.split(r'a bb\aa;mm a')
print(m)














 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









