







今天主要聊聊数仓的基础知识,分为两篇文章介绍,这是第一篇。
主要内容:
数仓基本概念
数仓架构演变
实时数仓和离线数仓的区别
首先说一下数据仓库的概念,以下简称数仓。
数仓是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
主题是公司从宏观出发,为了分析数据,分了用户主题、商品主题、设备主题等有助于决策的数据模型。
随着互联网的发展,数据源头越来越多且是分散的,除了业务库,APP埋点,web网站log,LOT 设备等会产生各种各样的海量数据,这些数据在进入数据仓库之前(或之后),需要进行统一(字段定义、主题归属、项目划分等),数据集成在一起。
数仓中的数据是不可修改的,主要用于数据查询,是相对稳定的。
数仓的数据一般都带有时间特征,数据是随着时间的变化而变化的。数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,反应历史变化。
数仓从模型层面分为三层:
ODS,操作数据层,保存原始数据;
DWD,数据仓库明细层,根据主题定义好事实与维度表,保存最细粒度的事实数据;
DM,数据集市/轻度汇总层,在DWD层的基础之上根据不同的业务需求做轻度汇总;
很多面试的时候,面试官会问数仓和数据库的区别,其实只要从下面这几个方面回答就可以。根本的还是问 OLAP 和 OLTP 的区别
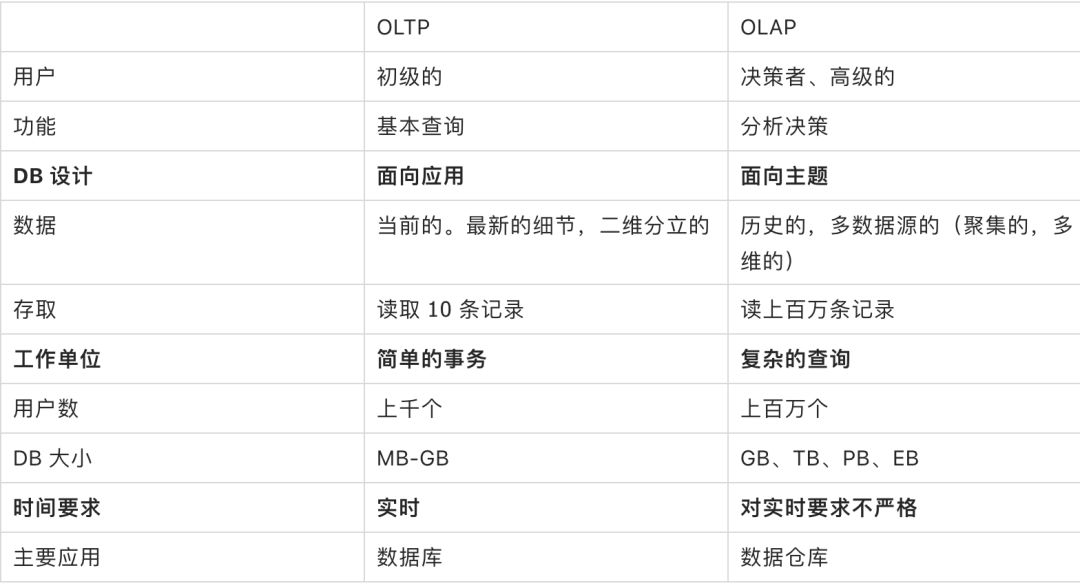
数仓有两个环节:一个是数仓的建设、另一个数仓的应用。
早期的数仓建设主要是把企业的业务数据库(ERP、CRM、SCM等数据按照决策分析的要求建模并汇总到数据仓库引擎中,其应用以报表为主,目的是支持管理层和业务人员决策(中长期策略型决策)。

传统数仓
目前,随着企业信息化的发展,数据源变得越来越丰富,在原来业务数据库的基础上出现了非结构化数据,比如网站log,IoT设备数据,APP埋点数据等,这些数据量比以往结构化的数据大了几个量级,对ETL过程、存储都提出了更高的要求;互联网的在线特性也对实时性提出了要求,比如用户反欺诈、用户审核等随着用户的暴涨,只靠人工干预是远远不够的。
总结一句话就是:实时数仓是个趋势,大量异构的数据存储和处理也是新的挑战。
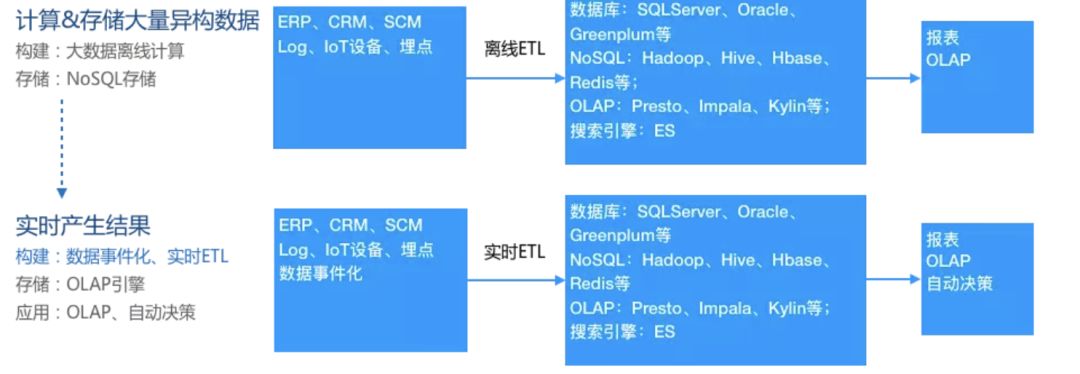
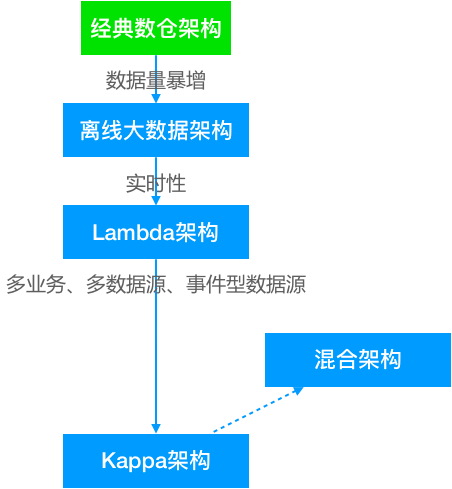
数据仓库概念是Inmon于1990年提出并给出了完整的建设方法。随着互联网时代来临,数据量暴增,开始使用大数据工具来替代经典数仓中的传统工具。此时仅仅是工具的取代,架构上并没有根本的区别,可以把这个架构叫做离线大数据架构。
后来随着业务实时性要求的不断提高,人们开始在离线大数据架构基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,这便是Lambda架构。
再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的Kappa架构。
下面是 Lambda 架构和Kappa架构的区别,以便大家可以深入了解这两种架构的优缺点。
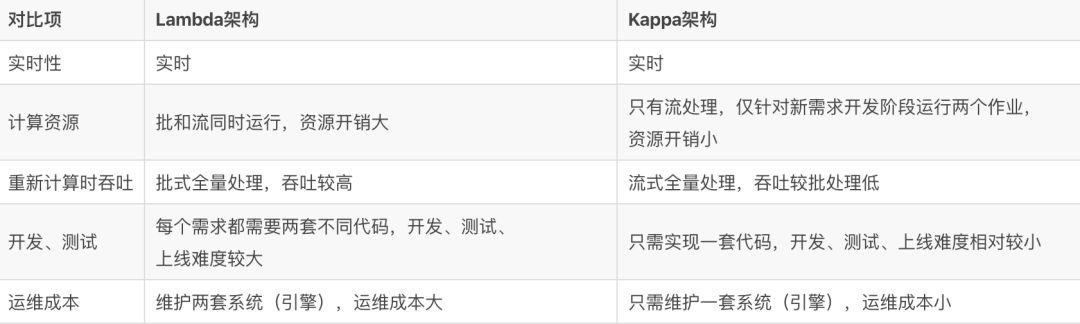
在真实的企业生产中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如大部分实时指标使用Kappa架构完成计算,少量关键指标(比如金额相关)使用Lambda架构用批处理重新计算,增加一次校对过程。Kappa 架构并不是中间结果完全不落地,现在很多大数据系统都需要支持机器学习(离线训练),所以实时中间结果需要落地对应的存储引擎供机器学习使用,另外有时候还需要对明细数据查询,这种场景也需要把实时明细层写出到对应的引擎中。
接下来我会分别介绍离线数仓和实时数仓的架构:
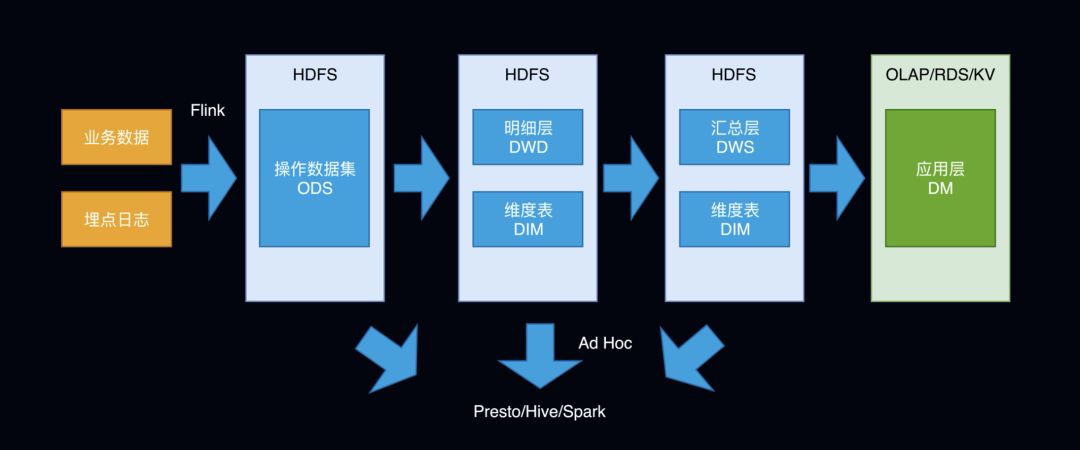
离线数仓
离线数仓,一般地,(业务、日志)数据存储在 HDFS 上,一般分这几层:ods/dwd/dws/dm,其中 dm 层的数据会导出到 olap、rds、kv数据库中供业务方使用。ad-hoc查询的数据来源一般来自 ods层或dw层,ad-hoc的查询引擎为 hive/spark/presto。
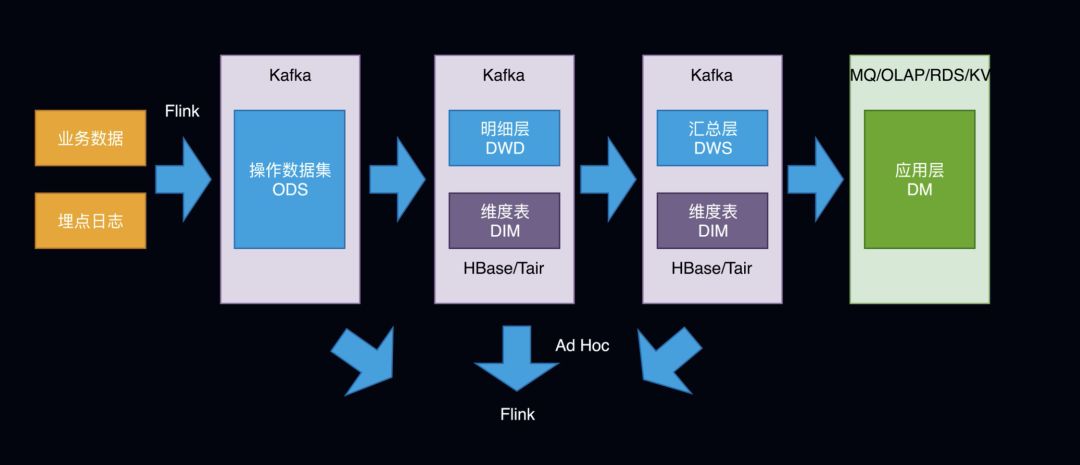
实时数仓
实时数仓,也是基于分层的模型 ods/dwd/dws/,业务数据和日志数据,事实数据存储在 kafka 中,维度数据存储在 Hbase/Tair 中,dm层的数据最终导出到 mq/olap/rds/kv中。ad-hoc 查询基于 Flink 来做。(都是流动的数据),如上图所示,就是 Kappa 架构。
主要:实时数仓的存储需考虑支持数据重放,方便支持任务重跑。选择一个具有重放功能的、能够保存历史数据并支持多消费者的消息队列,根据需求设置历史数据保存的时长,比如Kafka,可以保存全部历史数据。
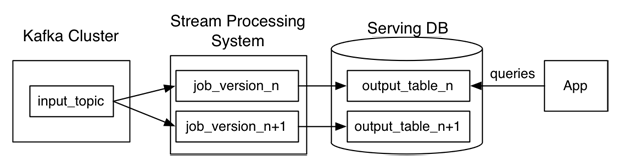
说到任务重跑,在实时数仓里面是这样做的:
1.当某个或某些指标有重新处理的需求时,按照新逻辑写一个新作业,然后从上游消息队列的最开始重新消费,把结果写到一个新的下游表中。
2.当新作业赶上进度后,应用切换数据源,读取2中产生的新结果表。
3.停止老的作业,删除老的结果表。
https://yq.aliyun.com/articles/691541
(完)
本文分享自微信公众号 - 大数据每日哔哔(bb-bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。















 7323
7323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









