







💡 本系列文章是 DolphinScheduler 由浅入深的教程,涵盖搭建、二开迭代、核心原理解读、运维和管理等一系列内容。适用于想对 DolphinScheduler了解或想要加深理解的读者。
祝开卷有益。
大数据学习指南
大家好,我是小陶,之前分享了如果自动检测依赖缺失:文章在这,今天依然是有关依赖关系的分享。DolphinScheduler 在使用过程中,肯定会有任务出现失败的情况,那么问题来了:调度任务的告警是需要人为配置的,在生产环境中,面对海量的任务,如何找到重要的任务,并且在失败的时候,第一时间告警呢?
先思考一下。
先看思路
本文提供一个思路,接着往下看吧。
不卖关子了。
本质是路径查找,本文这里使用了图数据库,或者你也可以自己使用Java实现路径查找。
下面是需要实现的目标,看一组任务的关系,如下图所示,存在 A/B/C/D/E 五个任务,E 任务被配置为核心任务,当 B 任务报错时,检测到 B 和 E 之前存在路径,则需要电话告警。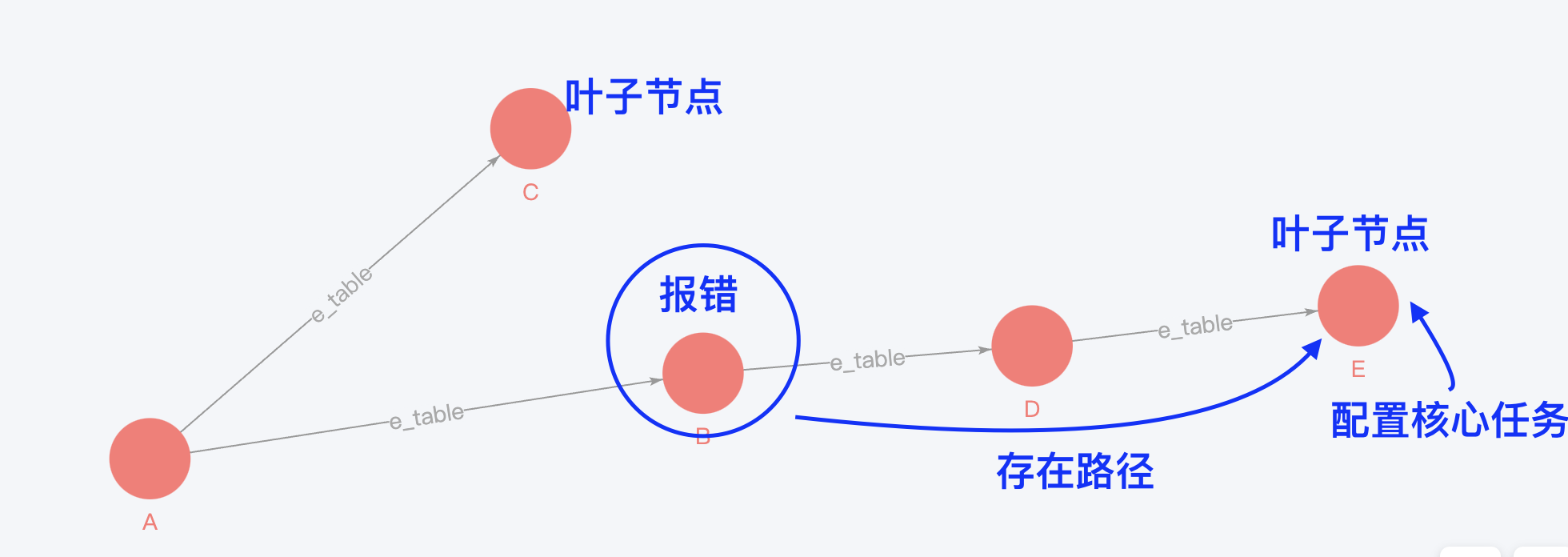
所以在配置核心链路告警的时候,我们只需要配置叶子节点,在实际生产中,一般是应用层的任务,比如报表、标签、接口数据等任务。
清洗依赖数据
核心逻辑就是把所有工作流内部、跨工作流以及跨项目的依赖全部清洗出来,生成一张关系表。具体清洗逻辑,可以看:文章在这
最终生成了
t_ds_task_node_base_data 任务基础表,后续会用于 Nebula Graph,这个后面会讲。
t_ds_dag_task_relation_data_df 关系最终表,后续会用于 Nebula Graph,这个后面会讲。
t_ds_dag_task_relation_data_df 这个表结构如下:
关系导入图数据库
这里用的国产图数据库 Nebula Graph,当然你也可以自己使用 Java 实现路径查找。
为什么我们一定要引入图数据库呢?有下面几方面考虑:
- 可以减轻调度系统Mysql的压力,把负责的路径计算放在图数据库里面。
- 探索更多调度任务数据治理和运维的可能性,比如任务权重,影响分析等。(不久的将来我也会分享这一块的实践。)
-

用到的组件是 Nebula Graph,最关键的函数是 find path 查询最短链路
① 用到的语法是:FIND SHORTEST PATH需要注意的是,注意查询步长,UPTO <N> {STEP|STEPS}:路径的最大跳数。默认值为5。
② 3.3.0 开始,子图支持了边的条件限制了,查询的时候只拿最新的一批关系。
创建图空间
CREATE SPACE s_schedule_job (partition_num = 225, replica_factor = 3, vid_type = FIXED_STRING(180)) COMMENT = "大数据平台调度系统任务的血缘关系";
创建边和点
## 任务标签
DROP tag if exists t_task;
CREATE tag if not exists t_task( id string NULL COMMENT "project_code,dag_code,task_code,拼接,", project_name string NULL COMMENT "project_name", project_code string NULL COMMENT "project_code", dag_name string NULL COMMENT "dag_name", dag_code string NULL COMMENT "dag_code", dag_version string NULL COMMENT "dag_version", task_code string NULL COMMENT "task_code", task_version string NULL COMMENT "task_version", task_name string NULL COMMENT "task_name", task_type string NULL COMMENT "task_type", create_time string NULL COMMENT "时间戳") comment='调度任务节点';
## 调度任务关系
drop edge if exists e_task;
create edge if not exists e_task( pre_project_name string NULL COMMENT "project_name", pre_project_code string NULL COMMENT "project_code", pre_dag_name string NULL COMMENT "dag_name", pre_dag_code string NULL COMMENT "dag_code", pre_dag_version string NULL COMMENT "dag_version", pre_task_code string NULL COMMENT "task_code", pre_task_version string NULL COMMENT "task_version", pre_task_name string NULL COMMENT "task_name", pre_task_type string NULL COMMENT "task_type", post_project_name string NULL COMMENT "project_name", post_project_code string NULL COMMENT "project_code", post_dag_name string NULL COMMENT "dag_name", post_dag_code string NULL COMMENT "dag_code", post_dag_version string NULL COMMENT "dag_version", post_task_code string NULL COMMENT "task_code", post_task_version string NULL COMMENT "task_version", post_task_name string NULL COMMENT "task_name", post_task_type string NULL COMMENT "task_type", create_time string NULL COMMENT "时间戳") comment='调度任务关系';
导入数据
同步点:
{
spark: {
app: {
name: Nebula_Exchange_t_task
}
driver: {
cores: 2
maxResultSize: 5G
}
}
nebula: {
address:{
graph:["10.1.x.xx:9669","10.1.x.xx:9669","10.1.x.xx:9669","10.1.x.xx3:9669","10.1.x.xx:9669"]
meta:["10.1.x.xx:9559","10.1.x.xx:9559","10.1.x.xx:9559"]
}
user: root
pswd: "nebula密码"
space: s_schedule_job
connection {
timeout: 60000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors/t_task
}
rate: {
limit: 1024
timeout: 10000
}
}
tags: [
{
name: t_task
type: {
source: mysql
sink: client
}
host:"调度系统MYSQL数据库IP"
port:3307
database:"调度系统MYSQL数据库"
table:"t_ds_task_node_base_data"
user:"调度系统MYSQL用户"
password:"调度系统MYSQL用户密码"
sentence:"SELECT concat(project_code,'_',dag_code,'_',task_code) as id,project_name,project_code,dag_name,dag_code,dag_version,task_code,task_version,task_name,task_type,create_time FROM t_ds_task_node_base_data"
fields: [project_name,project_code,dag_name,dag_code,dag_version,task_code,task_version,task_name,task_type,create_time]
nebula.fields: [project_name,project_code,dag_name,dag_code,dag_version,task_code,task_version,task_name,task_type,create_time]
vertex:{
field:id
}
batch: 256
partition: 32
}
]
}
同步边:
{
spark: {
app: {
name: Nebula_Exchange_e_task
}
driver: {
cores: 2
maxResultSize: 5G
}
}
nebula: {
address:{
graph:["10.1.x.xx:9669","10.1.x.xx:9669","10.1.x.xx:9669","10.1.x.xx3:9669","10.1.x.xx:9669"]
meta:["10.1.x.xx:9559","10.1.x.xx:9559","10.1.x.xx:9559"]
}
user: root
pswd: "aD@VX2018#"
space: s_schedule_job
connection {
timeout: 60000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors/e_task
}
rate: {
limit: 1024
timeout: 10000
}
}
edges: [
{
name: e_task
type: {
source: mysql
sink: client
}
host:"调度系统MYSQL数据库IP"
port:3307
database:"调度系统MYSQL数据库"
table:"t_ds_task_node_base_data"
user:"调度系统MYSQL用户"
password:"调度系统MYSQL用户密码"
sentence:"SELECT concat(pre_project_code,'_',pre_dag_code,'_',pre_task_code) as from_id,concat(post_project_code,'_',post_dag_code,'_',post_task_code) as to_id,pre_project_name,pre_project_code,pre_dag_name,pre_dag_code,pre_dag_version,pre_task_code,pre_task_name,pre_task_type,pre_task_version,post_project_name,post_project_code,post_dag_name,post_dag_code,post_dag_version,post_task_code,post_task_name,post_task_type,post_task_version,create_time FROM t_ds_dag_task_relation_data_df"
fields: [pre_project_name,pre_project_code,pre_dag_name,pre_dag_code,pre_dag_version,pre_task_code,pre_task_name,pre_task_type,pre_task_version,post_project_name,post_project_code,post_dag_name,post_dag_code,post_dag_version,post_task_code,post_task_name,post_task_type,post_task_version,create_time]
nebula.fields: [pre_project_name,pre_project_code,pre_dag_name,pre_dag_code,pre_dag_version,pre_task_code,pre_task_name,pre_task_type,pre_task_version,post_project_name,post_project_code,post_dag_name,post_dag_code,post_dag_version,post_task_code,post_task_name,post_task_type,post_task_version,create_time]
source: {
field: from_id
}
target: {
field: to_id
}
batch: 256
partition: 225
}
]
}
定时脚本: 使用 Nebula Graph 社区提供的 exchange 工具把数据从 mysql 导入 Nebula Graph。
#!/bin/bash
# 作业参数
basepath='/opt/vcredit-graph-db/s_schedule_job/exchange'
tmpdir='/tmp/nebula/s_schedule_job'
mkdir -p $tmpdir
sourcefile=${basepath}/${jobname}.conf
targetfile=${tmpdir}/${jobname}_${vardate}.conf
cat ${sourcefile} > ${targetfile}
sed -i "s/vardate/${vardate}/g" ${targetfile}
sed -i "s/varhivetable/${varhivetable}/g" ${targetfile}
# 运行环境
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
spark_submit="/opt/spark-2.4.8-bin-hadoop2.7/bin/spark-submit"
# 开始运行
${spark_submit} \
--principal hive@VCREDIT.COM \
--keytab /etc/security/hive.keytab \
--master "local[*]" \
--class com.vesoft.nebula.exchange.Exchange /opt/nebula/nebula-exchange_spark_2.4-3.0.0.jar -c ${targetfile} -h
Java 服务
/**
* 判断这个任务是否会影响核心任务
* @param projectName
* @param dagName
* @param taskName
* @return
*/
@ApiOperation(value = "dolphinTaskIsOnCall", notes = "判断这个任务是否会影响核心任务,是 1 ,否 0")
@ApiImplicitParams({
@ApiImplicitParam(name = "projectName", value = "T-1", required = false, dataType = "String", example = "BigData"),
@ApiImplicitParam(name = "dagName", value = "T-1", required = false, dataType = "String", example = "公共和自定义域(pub)_daily"),
@ApiImplicitParam(name = "taskName", value = "T-1", required = false, dataType = "String", example = "dwd_pub_screen_zxd_cust_df")
})
@GetMapping("/dolphinTaskIsOnCall")
@ResponseBody
public DataResult dolphinTaskIsOnCall(
@RequestParam(value = "projectName", required = true) String projectName,
@RequestParam(value = "dagName", required = true) String dagName,
@RequestParam(value = "taskName", required = true) String taskName) throws GraphDatabaseException, UnsupportedEncodingException {
HashMap<String,Object> res = dolphinService.dolphinTaskIsOnCall(projectName, dagName, taskName);
return DataResult.ok(res);
}
核心代码,在第 17 行:
@Override
public HashMap<String, Object> dolphinTaskIsOnCall(String projectName, String dagName, String taskName) throws GraphDatabaseException, UnsupportedEncodingException {
HashMap<String,Object> resMap = new HashMap<>();
// 查询该任务 codes
HashMap<String,Object> task = dolphinTaskInstanceMapper.getTaskCode(projectName,dagName,taskName);
if (task == null){
resMap.put("res","任务不存在!");
return resMap;
}
String fromCodes = task.get("project_code") + "_" + task.get("dag_code") + "_" + task.get("task_code");
// 查询核心任务 codes
List<HashMap<String,Object>> tasks = dolphinTaskInstanceMapper.getOnCallTasks();
// 查询最短链路
for (HashMap<String,Object> t : tasks){
String toCodes = t.get("project_code") + "_" + t.get("dag_code") + "_" + t.get("task_code");
// 查询Nebula
String NgSql = "FIND SHORTEST PATH with PROP FROM \"" + fromCodes + "\" TO \"" + toCodes + "\" OVER * WHERE e_task.create_time > '" + DateUtils.dayToString(DateUtils.getSomeDay(new Date(), -1)) + "' UPTO 100 STEPS YIELD path AS p;";
int res = nebulaService.isOnCallTask("s_schedule_job",NgSql);
if (res > 0){
resMap.put("res",res);
return resMap;
}
}
resMap.put("res",0);
return resMap;
}
返回值说明:
① 影响核心任务,需要打电话
{“data”:{“res”:1},“code”:0,“msg”:“success”}
② 不影响核心任务,不需要打电话
{“data”:{“res”:0},“code”:0,“msg”:“success”}
③ 任务不存在,忽略
{“data”:{“res”:“任务不存在!”},“code”:0,“msg”:“success”}
④ code 不等于 0 ,接口异常,忽略。
封装好接口之后,任务失败的程序调这个接口,判断失败任务是否影响核心任务,如果影响就打电话。
钉钉告警样式:

电话告警,直接给对应负责人打电话。
至此,我们减少了很多任务告警的配置工作,只需要关注核心的叶子节点是什么,也就是核心的应用任务是什么,大大提高了任务告警的配置效率!!!
注意:清洗数据 和 导入图数据库,在每天的 23:30 分进行,一天初始化一次,确保凌晨的任务关系是最新的,主要是用于凌晨告警。
以上就使用图关系网络解决核心链路告警的全部内容,如果有任何疑问,都可以与我交流,希望可以帮到你,下次见。
**大数据学习指南 **专注于大数据技术分享与交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









