







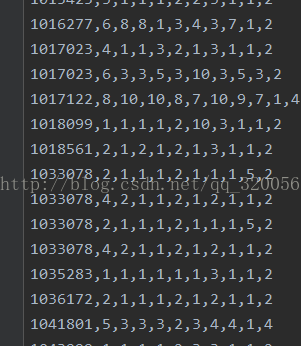
此实例是利用svm算法预测乳腺癌肿瘤是良性还是恶性,数据格式如下图所示:第一列表示编号,2到10列表示数据属性,第11列表示肿瘤标签2表示良性4表示恶性。
代码如下
from sklearn import svm # x = [[2, 0], [1, 1], [2, 3]] # 特征向量 # y = [0, 0, 1] # 标签 # clf = svm.SVC(kernel = 'linear') # clf.fit(x, y) # # print(clf) # print(clf.support_vectors_) # 打印支持向量点的坐标 # print(clf.support_) # 打印支持向量点的位置 # print(clf.n_support_) # 打印支持向量点的个数 # print(clf.predict([5,5])) # 预测 import pandas from sklearn.cross_validation import train_test_split from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix import numpy as np # ---------------------------------由于数据中很多实例存在问号以下是去问号过程------------------------------------- breast_cancer_wisconsin = np.genfromtxt("breast_cancer_wisconsin.txt", delimiter=",",dtype="str",skip_header=1) X = breast_cancer_wisconsin[:,1:-1] list1 = breast_cancer_wisconsin.tolist() a = [] for i in range(X.shape[0]): if '?' not in list1[i]: a.append(list1[i][0]) breast_cancer_wisconsin1 = pandas.read_csv("breast_cancer_wisconsin.txt",dtype="str") breast_cancer_wisconsin_a = breast_cancer_wisconsin1.set_index('a') b = breast_cancer_wisconsin_a.loc[a] # b.to_csv(file_path, encoding='utf-8', index=False) b.to_csv(r'D:\BaiduNetdiskDownload\代码与素材\代码与素材(1)\04NN\test1.csv', encoding='utf-8') # ---------------------------------------------数据预处理结束--------------------------------------------------------- test1 = np.genfromtxt("test1.csv", delimiter=",",dtype="int",skip_header=1) X = test1[:,1:-1] y = test1[:,-1] X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25) clf = svm.SVC(kernel = 'linear') clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) print(confusion_matrix(y_test, y_pred)) print(clf.support_vectors_) # 打印支持向量点的坐标 print(clf.n_support_) # 打印支持向量点的个数 print(clf.support_) # 打印支持向量点的位置 print(clf.predict([1,2,4,8,3,7,3,6,4])) # 预测
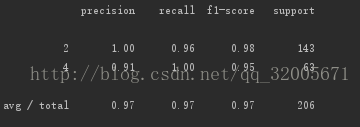
预测结果如下图:















 4318
4318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









