








 本文深入探讨了Spark的Shuffle过程,包括原始的Hash Shuffle机制及其内存与磁盘文件过多的问题,以及Consolidated HashShuffle的优化,减少了磁盘文件数量。另外,还介绍了Sort-Based Shuffle,特别是bypass运行机制,它在某些条件下能提高性能,因为它不进行数据排序。
本文深入探讨了Spark的Shuffle过程,包括原始的Hash Shuffle机制及其内存与磁盘文件过多的问题,以及Consolidated HashShuffle的优化,减少了磁盘文件数量。另外,还介绍了Sort-Based Shuffle,特别是bypass运行机制,它在某些条件下能提高性能,因为它不进行数据排序。
目录
Hash-based Shuffle
原始的Hash Shuffle机制
Hash shuffle经历了两个阶段,第一个阶段是最开始的阶段,原理图如下:
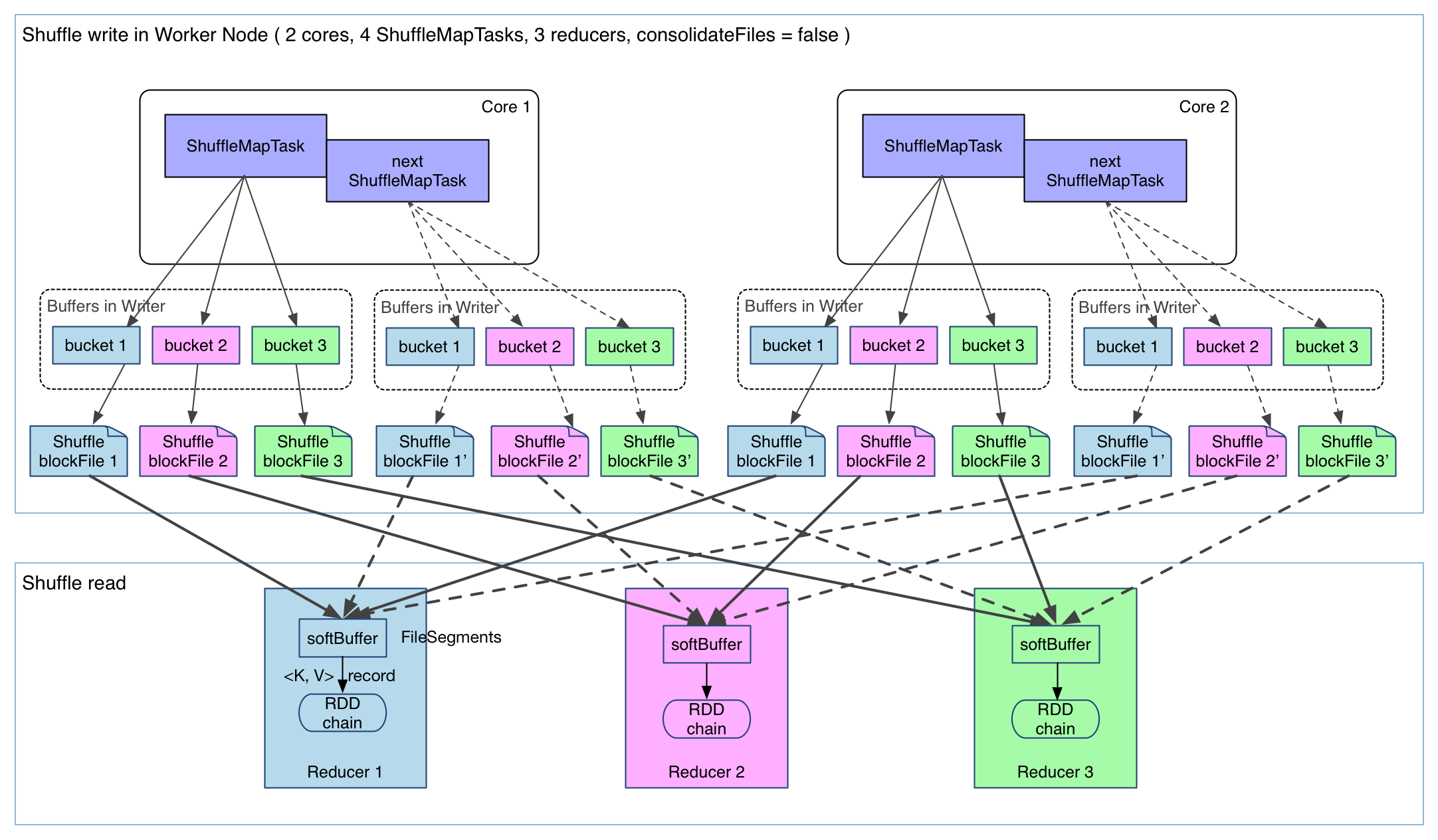
- 首先每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M×RM×R,其中MM是Map的个数,RR是Reduce的个数。
- 其次Mapper产生的结果会根据设置的partition算法填充到每个bucket中去。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中去。
1:shuffle write阶段
主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey,groupByKey),而将每个task处理的数据按key进行“分区”。所谓“分区”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于reduce端的stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?很简单,下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个task,总共有10个Executor,每个Executor执行5个Task,那么每个Executor上总共就要创建500个磁盘文件,所有Executor上会创建5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
2:shuffle read阶段
shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给Reduce端的stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
Hash shuffle普通机制的问题
1 产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
2 缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores * R * 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
优化后的 HashShuffle 机制-Consolidated HashShuffle
- Consolidated HashShuffle解决了上面的第一个问题,原理图如下:

这里还是有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。Consoldiated Hash-Shuffle的优化有一个很大的好处就是假设现在有200个Mapper Tasks在同一个进程中,也只会产生3个本地小文件; 如果用原始的 Hash-Based Shuffle 的话,200个Mapper Tasks 会各自产生3个本地小文件,在一个进程已经产生了600个本地小文件。3个对比600已经是一个很大的差异了。
Sort-Based Shuffle
- Sort-based Shuffle的工作方式如下:Shuffle的目的就是:数据分类,然后数据聚集。
- SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。

1) 首先每个ShuffleMapTask不会为每个Reducer单独生成一个文件,相反,Sort-based Shuffle会把Mapper中每个ShuffleMapTask所有的输出数据Data只写到一个文件中。因为每个ShuffleMapTask中的数据会被分类,所以Sort-based Shuffle使用了index文件存储具体ShuffleMapTask输出数据在同一个Data文件中是如何分类的信息!!
2) 基于Sort-base的Shuffle会在Mapper中的每一个ShuffleMapTask中产生两个文件:Data文件和Index文件,其中Data文件是存储当前Task的Shuffle输出的。而index文件中则存储了Data文件中的数据通过Partitioner的分类信息,此时下一个阶段的Stage中的Task就是根据这个Index文件获取自己所要抓取的上一个Stage中的ShuffleMapTask产生的数据的,Reducer就是根据index文件来获取属于自己的数据。
涉及问题:Sorted-based Shuffle:会产生 2*M(M代表了Mapper阶段中并行的Partition的总数量,其实就是ShuffleMapTask的总数量)个Shuffle临时文件。
Shuffle产生的临时文件的数量的变化一次为:
Basic Hash Shuffle: M*R;
Consalidate方式的Hash Shuffle: C*R;
Sort-based Shuffle: 2*M;
bypass运行机制
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
2)不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
bypass运行机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









