









基于词向量实现文本分类
摘要
本文基于词向量(Word2Vec),使用支持向量机(SVM)作为分类器来预测文本的类别,来实现文本分类任务。代码的功能是加载预训练的Word2Vec模型,并利用该模型将文本转化为向量,再用支持向量机(SVM)进行训练和预测,最后输出分类结果的报告。
以下是代码各部分的详细解释:
1. 导入库和模块
import json
import jieba
import numpy as np
from gensim.models import Word2Vec
from sklearn.metrics import classification_report
from sklearn.svm import SVC
from collections import defaultdict
json: 用于解析JSON格式的数据。jieba: 一个中文分词库,用于对文本进行分词。numpy: 用于处理数值计算,特别是数组和矩阵操作。gensim.models.Word2Vec: 用于加载和使用Word2Vec模型。sklearn.metrics.classification_report: 用于输出分类报告,评估分类器性能。sklearn.svm.SVC: 用于支持向量机(SVM)分类器的实现。collections.defaultdict: 用于提供一个默认值字典,但在这段代码中似乎并未使用。
2. LABELS 字典
LABELS = {'健康': 0, '军事': 1, '房产': 2, '社会': 3, '国际': 4, '旅游': 5, '彩票': 6, '时尚': 7, '文化': 8, '汽车': 9, '体育': 10, '家居': 11, '教育': 12, '娱乐': 13, '科技': 14, '股票': 15, '游戏': 16, '财经': 17}
LABELS 是一个字典,用于将文本的标签(如“健康”、“军事”等)转换为对应的数值类别(0 到 17)。这在机器学习中非常常见,因为大部分机器学习算法需要数值化的输入。
3. 加载Word2Vec模型
def load_word2vec_model(path):
model = Word2Vec.load(path)
return model
这个函数通过提供的文件路径加载已经训练好的Word2Vec模型。Word2Vec 是一种用于将单词转化为向量的模型,训练过程中会学习到每个单词的词向量表示。这里加载的是一个已经训练好的模型文件。
训练好的词向量文件词向量模型权重文件
4. 加载数据集
def load_sentence(path, model):
sentences = []
labels = []
with open(path, encoding="utf8") as f:
for line in f:
line = json.loads(line)
title, content = line["title"], line["content"]
sentences.append(" ".join(jieba.lcut(title)))
labels.append(line["tag"])
train_x = sentences_to_vectors(sentences, model)
train_y = label_to_label_index(labels)
return train_x, train_y
这个函数从给定的路径加载文本数据集。每一行包含新闻的标题和内容,同时还包含标签(新闻的分类)。在加载数据时:
- 使用
jieba.lcut()对标题进行中文分词。 - 将分词后的标题连接成一个字符串,并存储在
sentences列表中。 - 标签(
tag)也被存储在labels列表中。
然后:
- 使用
sentences_to_vectors()将分词后的句子转换为词向量(每个句子对应一个向量)。 - 使用
label_to_label_index()将标签转化为数值索引(0 到 17)。
5. 标签转化
def label_to_label_index(labels):
return [LABELS[y] for y in labels]
这个函数将文本标签(如“健康”、“军事”等)转换为对应的数字索引,方便机器学习模型处理。
6. 文本向量化
def sentences_to_vectors(sentences, model):
vectors = []
for sentence in sentences:
words = sentence.split()
vector = np.zeros(model.vector_size)
for word in words:
try:
vector += model.wv[word]
except KeyError:
vector += np.zeros(model.vector_size)
vectors.append(vector / len(words))
return np.array(vectors)
这个函数将每个句子转化为一个向量。具体步骤如下:
- 每个句子被分成单个词(
words)。 - 为每个词查找其在Word2Vec模型中的向量表示,并将这些词向量相加。若词不存在于模型中(
KeyError),则为该词使用零向量。 - 最后将所有词向量的和除以词数,得到该句子的平均词向量。这样每个句子都被表示为一个固定维度的向量。
7. 主函数 main()
def main():
model = load_word2vec_model("model.w2v")
train_x, train_y = load_sentence("../data/train_tag_news.json", model)
test_x, test_y = load_sentence("../data/valid_tag_news.json", model)
classifier = SVC()
classifier.fit(train_x, train_y)
y_pred = classifier.predict(test_x)
print(classification_report(test_y, y_pred))
model = load_word2vec_model("model.w2v"): 加载已经训练好的Word2Vec模型。train_x, train_y = load_sentence("../data/train_tag_news.json", model): 加载训练集数据,将文本转化为词向量(train_x)并获得标签(train_y)。test_x, test_y = load_sentence("../data/valid_tag_news.json", model): 加载验证集数据,同样进行文本转化。classifier = SVC(): 创建一个支持向量机分类器(SVM)。classifier.fit(train_x, train_y): 使用训练集对SVM进行训练。y_pred = classifier.predict(test_x): 使用训练好的模型对测试集进行预测。print(classification_report(test_y, y_pred)): 输出分类报告,评估模型在测试集上的表现(准确率、召回率、F1分数等)。
8. 程序入口
if __name__ == "__main__":
main()
这行代码确保当该脚本直接运行时,会调用 main() 函数执行程序。
9.运行结果
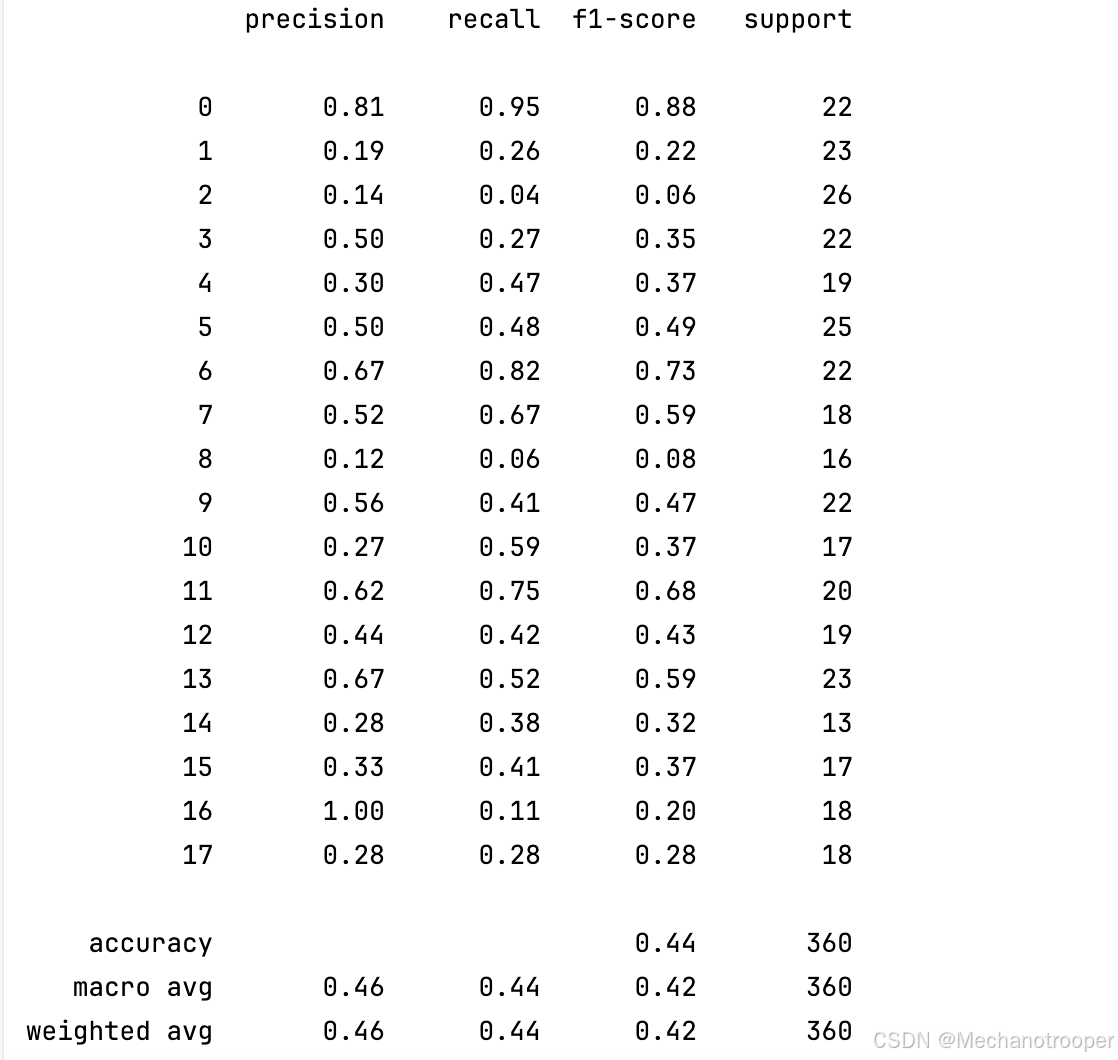
根据给出的 分类报告,我们可以从多个角度进行分析:
9.1 总体表现
- 准确率(Accuracy):整体准确率为 0.44,即44%的样本被正确分类。这个结果说明,模型的表现相对较差,尤其是在多类别分类任务中。因为准确率并没有达到50%,这表明模型可能在某些类别上的预测结果不理想。
- 宏平均(Macro Average):
- Precision(精确率):0.46
- Recall(召回率):0.44
- F1-Score:0.42
宏平均计算的是各个类别的平均值,不考虑类别的不平衡。这里,F1-Score较低,说明模型在整体上可能存在精度与召回率之间的较大差异。
- 加权平均(Weighted Average):
- Precision(精确率):0.46
- Recall(召回率):0.44
- F1-Score:0.42
加权平均考虑了每个类别样本数的影响,相比于宏平均,加权平均给大类别更多权重。在这里加权平均和宏平均相似,表明类别分布对模型的影响较大。
9.2各类别的分析
观察每个类别的具体表现:
12. 类别0(健康):
13. Precision: 0.81
14. Recall: 0.95
15. F1-Score: 0.88
16. 支持度(Support): 22
健康类的分类效果较好,召回率非常高(0.95),表明该类别的大部分样本都被正确分类,但精确率(0.81)略低,意味着模型在预测健康类时有些误分类。
17. 类别16(游戏):
18. Precision: 1.00
19. Recall: 0.11
20. F1-Score: 0.20
21. 支持度(Support): 18
游戏类的精确率极高(1.00),意味着当模型预测为游戏类时,几乎所有的预测都是准确的。然而,召回率非常低(0.11),说明模型几乎没有成功识别游戏类的样本。这个不平衡的表现表明,模型可能过于保守,没有积极识别游戏类。
- 类别2(房产):
- Precision: 0.14
- Recall: 0.04
- F1-Score: 0.06
- 支持度(Support): 26
房产类的分类效果非常差,精确率和召回率都很低,尤其是召回率(0.04),表明模型几乎没有识别出房产类的样本。这个类别可能存在样本不足、特征不明显或者模型无法有效区分该类别的原因。
27. 类别1(军事):
28. Precision: 0.19
29. Recall: 0.26
30. F1-Score: 0.22
31. 支持度(Support): 23
军事类也表现不佳,虽然召回率稍高于精确率,但F1-Score仍然较低,表明在该类样本中,模型预测效果差。
9.3. 模型问题和挑战
- 类别不平衡:从报告中可以看出,不同类别的支持度差异较大,部分类别的样本数量较少(如类别16游戏类支持度为18)。类别不平衡通常会导致模型在某些类别上的表现不佳(如房产类、军事类、游戏类)。
- 低召回率与低精确率:某些类别的召回率和精确率都较低,尤其是房产类和军事类。这可能意味着模型无法有效识别这些类别,或者这些类别的特征在训练数据中没有很好地被捕捉到。
9.4. 改进建议
- 数据增强:考虑对训练集进行数据增强,尤其是对于样本较少的类别(如游戏类和房产类)。可以通过添加更多样本或使用过采样/欠采样方法来平衡类别。
- 模型调优:调整SVM模型的超参数,特别是C和gamma的值,可能会改善分类效果。
- 特征工程:探索其他的特征工程方法,或使用更多类型的文本特征来丰富模型的输入(例如,TF-IDF、n-grams等)。
- 其他模型尝试:考虑尝试其他更复杂的模型,如深度学习模型(如BERT、LSTM等),它们可能在处理文本分类任务时能捕捉更复杂的特征。
9.5. 结论
总体来看,模型在不同类别上的表现差异较大。对于某些类别(如健康类),模型的效果不错,而对于其他类别(如房产类、军事类),则表现较差。模型的准确性可以进一步通过优化数据处理、调整模型参数或更换算法来提升。
总结:
这段代码的主要目的是:
- 利用已训练好的 Word2Vec 模型,将新闻文本的标题转化为词向量。
- 然后使用支持向量机(SVM)对这些词向量进行训练和分类。
- 最终输出分类报告,评估模型的性能。
主要使用了:
Word2Vec模型来进行词向量的获取。jieba分词库处理中文文本。SVC(支持向量机)进行文本分类任务。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









