







目录
在讨论了干预效果异质性之后,是时候转换一下思路,回到平均干预效果上来了。在接下来的几章中,您将学习如何利用面板数据进行因果推断。
面板数据是一种跨时间重复观测的数据结构。在多个时间段观察同一单位,可以了解同一单位在干预前后的情况。这就使得面板数据成为在无法进行随机化时确定因果效应的一种有前途的替代方法。当你有观察性(非随机)数据,并且可能存在未观察到的混杂因素时,面板数据方法是正确识别干预效果的最佳方法。
在本章中,你将了解为什么面板数据对因果推断如此重要。然后,您将学习最著名的面板数据因果推理估计器:双重差分及其多种变体。为了保持趣味性,所有这些都将在计算离线营销活动效果的背景下进行。
Panel Data
为了激发对面板数据的使用,我将主要谈谈因果推理在市场营销中的应用。市场营销之所以特别有趣,是因为它在进行随机实验方面存在众所周知的困难。在市场营销中,你往往无法控制谁会接受干预,也就是说,谁会看到你的广告。当一个新用户访问您的网站或下载您的应用程序时,您无法很好地知道该用户是因为看到了您的广告活动还是因为其他原因。即使您知道客户点击了您的某个营销链接,也很难判断他们是否会购买您的产品。例如,如果客户点击了您赞助的谷歌链接,如果他们真的在寻找您的产品,他们也可能会向下滚动一下,然后点击未付费的链接。
线下营销的问题更大。你怎么知道在一个城市投放广告牌是否能带来超过成本的价值?因此,市场营销中常见的做法是进行地理实验:您可以在某些地理区域部署营销活动,而不在其他区域部署,然后进行比较。在这种设计中,面板数据方法尤其有趣:您可以在多个时间段内收集整个地域(单位)的数据。就像我说过的,面板数据是指在多个时间段 t 内有多个单位 i。在一些市场网站中,单位可能是人,t 可能是天或月。但单位并不一定是单个客户。例如,在线下营销活动中,i 可以是城市,您可以在这些城市放置产品广告牌。
下面的数据框 mkt_data 是一个面板格式的营销数据。每一行都是(日期、城市)的组合:
import pandas as pd
import numpy as np
mkt_data = (pd.read_csv("./data/short_offline_mkt_south.csv")
.astype({"date":"datetime64[ns]"}))
mkt_data.head()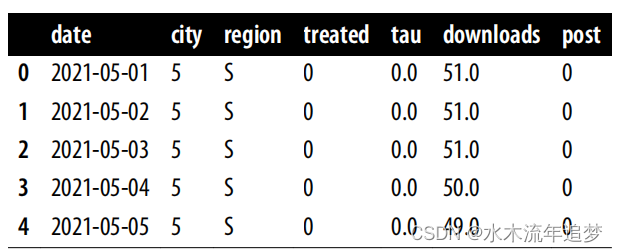
该数据框按日期和城市排序。您关心的结果变量是下载次数。由于 t 将用来表示时间,为了避免混淆,从现在起,我将用 D 来表示干预。另外,在面板数据文献中,处理通常被称为干预。我将交替使用这两个术语。在本例中,营销团队在 Di = 1 的城市发起了线下活动。至于时间维度,让我们确定 T 将是期间数, 是干预前的期间数。你可以把时间向量看作
. 干预后的时间段
, ... . , T 被方便地称为干预后。为了简化符号,我通常使用 "后 "虚拟变量,当 t >
时为 1,否则为 0。
干预只发生在干预后时期(t > )的治疗单位(D = 1)。干预和干预后的组合将用
或
表示。下面是营销数据中的一个示例:
(mkt_data
.assign(w = lambda d: d["treated"]*d["post"])
.groupby(["w"])
.agg({"date":[min, max]}))
如您所见,干预前的时间段为 2021-05-01 至 2021-05-15,干预后的时间段为 2021-05-15 至 2021-06-01。
这个数据集还有一个 τ 变量来表示干预效果。由于该数据是模拟的,因此我很清楚该效应是什么。我把它包含在这个数据集中,只是为了让你检查一下,你将要学习的方法是否能很好地识别因果效应。但不要习惯它。在现实生活中,你不会有这样的奢侈。
现在,您对数据有了更好的了解,也学会了一些新的技术符号,您可以更准确地重述您的目标。您想了解线下营销活动在干预发生后对受干预城市的影响:
这就是 ATT,因为您只想了解活动启动 后对 D = 1 的城市产生的影响。由于
是可观测的,因此您可以通过推算缺失的潜在结果
来实现这一目标。
图 显示了为什么用单位时间矩阵表示观察到的结果时,面板数据会变得特别有趣。该矩阵突出了这样一个事实,即只有在干预后的时间段内,才能观察到被干预单位的 ,而对于所有其他单元,您可以观察到
。尽管如此,这些单元仍可用于估计缺失的潜在结果
。您可以通过使用干预后期间对照单元的结果来利用单元间的相关性,也可以通过使用干预前期间受治疗单元的结果来利用跨时间的相关性。
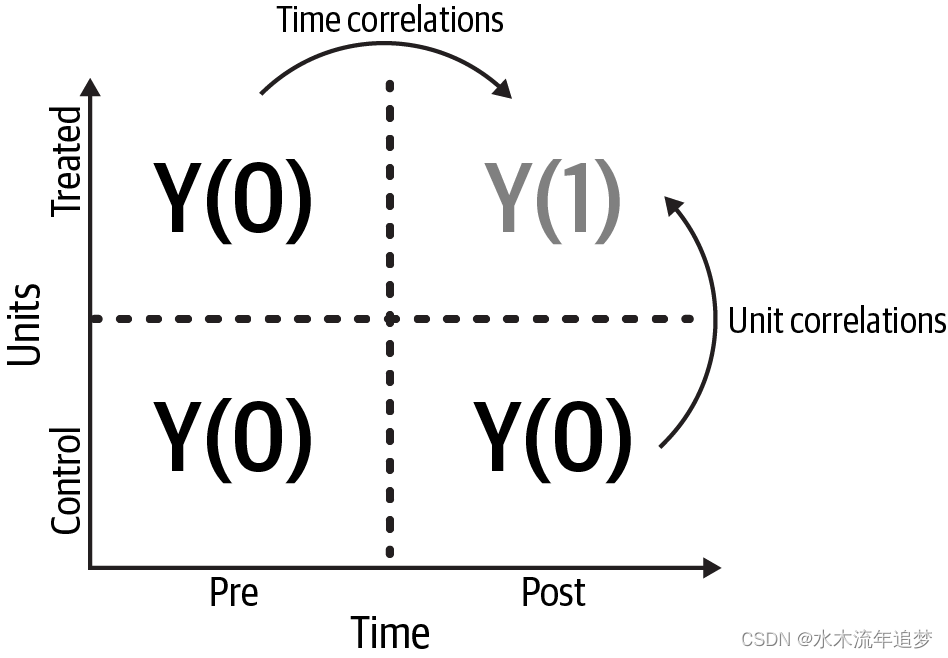
图 还说明了为什么在大多数面板数据应用中应该关注 ATT:对被处理单位的 进行推算要容易得多。如果您想要的是 ATC(对对照组的平均影响),则必须计算
。但是,您只有一个单元格可以观察到该潜在结果。现在,您已经对面板数据有了简单的了解,是时候探索一些利用面板数据来识别和估计干预效果的机制了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











