






 本文提出了一种基于转移的密度估计算法SDE,旨在解决多目标优化算法在高维度问题上的收敛性和多样性问题。SDE通过改变个体的位置来评估其密度,从而改善选择压力,增强算法的性能。实验表明,将SDE整合到NSGA-II、SPEA2和PESA-II等算法中,能显著提升它们在多目标问题上的表现。
本文提出了一种基于转移的密度估计算法SDE,旨在解决多目标优化算法在高维度问题上的收敛性和多样性问题。SDE通过改变个体的位置来评估其密度,从而改善选择压力,增强算法的性能。实验表明,将SDE整合到NSGA-II、SPEA2和PESA-II等算法中,能显著提升它们在多目标问题上的表现。
论文:Shift-based density estimation for Pareto based algorithms in many-objective optimization
- 改变pareto dominance 关系
- 改变多样性维护机制
这篇文章提出了 shift-based density estimation (SDE) strategy基于转移的密度估计策略,SDE可以同时兼顾收敛性与分布的多样性。SDE是通过改变多样性的方式提高选择压力的。SDE的原理很简单,就是将收敛性不好的个体转移到拥挤区域并分配一个大的density value,这样在选择过程中很容易被删除。
Density Estimation in EMO Algorithms EMO中的密度估计算法:
EMO算法中有很多密度估计的方法,他们基本都是作用于个体的不同邻居,或不同的方法的。比如niched Pareto genetic algorithm(NPGA)考虑到小生境中的个体并计算小生境的拥挤程度,strength Pareto EA (SPEA)采用基于聚类的方法估计拥挤程度,NSGA-II定义了拥挤距离crowding distance反映一个个体的密度,这个方法只考虑一个个体两边的最近的个体,grid-based EMO 比如 PESA-II和dynamic multiobjective EA (DMOEA)通过对hyperbox中个体计数估计密度。SPEA2考虑了种群中个体的K个近邻,距离的计算方式可以采用Euclidean distance欧式距离或者Tchebycheff distance切比雪夫距离。
Shift-Based Density Estimation (SDE)基于转移的密度估计:
当估计一个个体p的密度时,SDE通过对比收敛性将p的位置转移到种群中其他个体的位置上。具体地讲就是当一个个体p在一个目标上表现比另一个个体好时就将p转移到另一个个体的当前目标位置,否则p的位置不动。如公式所示,![]() 是p在种群P中新的密度估计,N是种群个数。
是p在种群P中新的密度估计,N是种群个数。
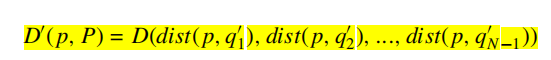
![]() 是两个个体的相似度,
是两个个体的相似度,![]() 是
是![]() 的转换后的点
的转换后的点
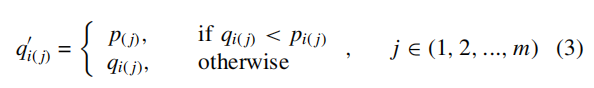

举个例子,如图所示,在两个目标最小化问题的二维图中,四个点A(10, 17), B(1, 18), C(11, 6), and D(18, 2), B 被转移到 ![]() (10, 18) ,因为 B1 = 1 < A1 = 10, C 和 D 转移到
(10, 18) ,因为 B1 = 1 < A1 = 10, C 和 D 转移到 ![]() (11, 17) and
(11, 17) and ![]() (18, 17), respectively, since C2 = 6 < A2 = 17 and D2 = 2 < A2 = 17.可以看到,A原来与其他点具有较低的相似度,但是转移后有两个近邻此时被分配较高密度值。这是因为B和C在收敛性上比A好。虽然在某个目标值上不如A,但是其他目标上比A远远有优势。因此SDE中没有明显优势的点会被分配一个高的密度值。
(18, 17), respectively, since C2 = 6 < A2 = 17 and D2 = 2 < A2 = 17.可以看到,A原来与其他点具有较低的相似度,但是转移后有两个近邻此时被分配较高密度值。这是因为B和C在收敛性上比A好。虽然在某个目标值上不如A,但是其他目标上比A远远有优势。因此SDE中没有明显优势的点会被分配一个高的密度值。

为了进一步说明SDE的效果,对最小化问题四种情况下的收敛性和多样性进行说明:(a)很好的收敛性和多样性,(b)收敛性不好和多样性好 (c)收敛性好和多样性不好 (d)收敛性和多样性都不好
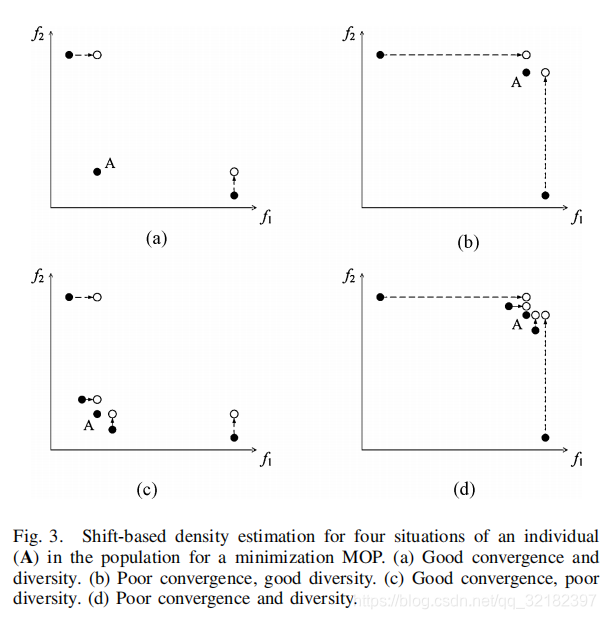
从(c)(d)中可以看出不管收敛性好不好,如果多样性差的话个体种群会聚集在拥挤区域。
不管是收敛性不好还是多样性不好,个体都会有几个近邻,因此,SDE兼顾了多样性和收敛性。

















 2321
2321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









