







项目介绍
使用Scrapy框架进行爬取伯乐在线的所有技术文章
所用知识点
- Scrapy项目的创建
- Scrapy框架Shell命令的使用
- Scrapy自带的图片下载管道
- Scrapy自定义图片下载管道(继承自带的管道)
- Scrapy框架ItemLoader的使用
- Scrapy自定义ItemLoader
- Scrapy中同步将Item保存入Mysq数据库
- Scrapy中异步将Item保存入Mysq数据库
项目初始
创建新项目
scrapy startproject bole
创建爬虫
scrapy
genspider
jobbole
blog
.jobbole.com
爬虫调试
为了方便对爬虫进行调试,在项目目录中创建一个main.py文件
from
scrapy.cmdline
import
execute
import
sys,os
# 将项目目录动态设置到环境变量中
# os.path.abspath(__file__) 获取main.py的路径
# os.path.dirname(os.path.abspath(__file__) 获取main.py所处目录的上一级目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute([
'scrapy'
,
'crawl'
,
'jobbole'
])
在爬虫开始运行时,建议修改项目中的配置文件,找到
ROBOTSTXT_OBEY
将其改为False,如果不修改的话,Scrapy会自动的查找网站的ROBOTS协议,会过滤不符合协议的URL
在windows环境下可能会出现
No moudle named 'win32api'
,因此需要执行
pip install pypiwin32
如果下载速度过慢可使用豆瓣源进行安装
前置知识
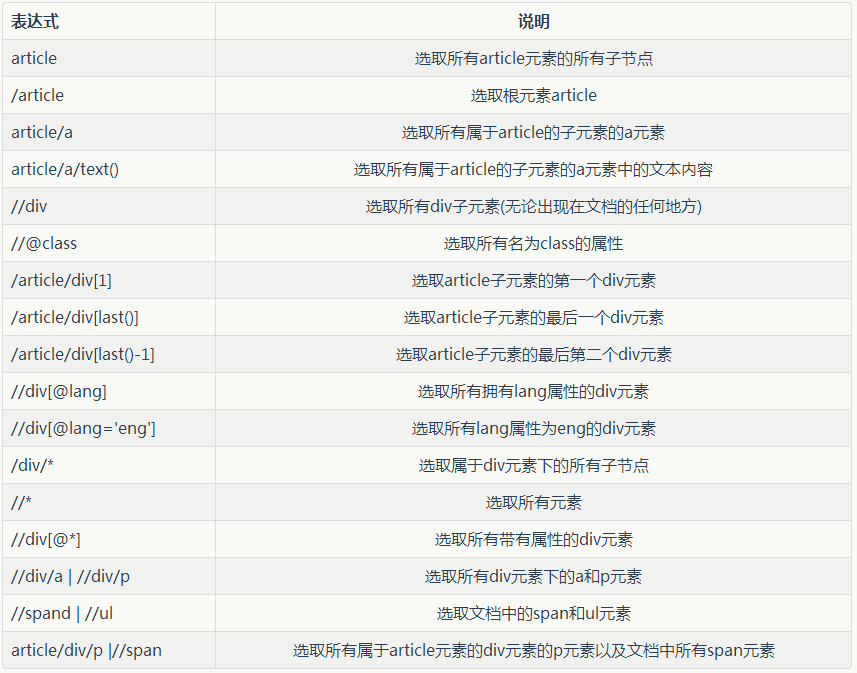
XPath语法简介
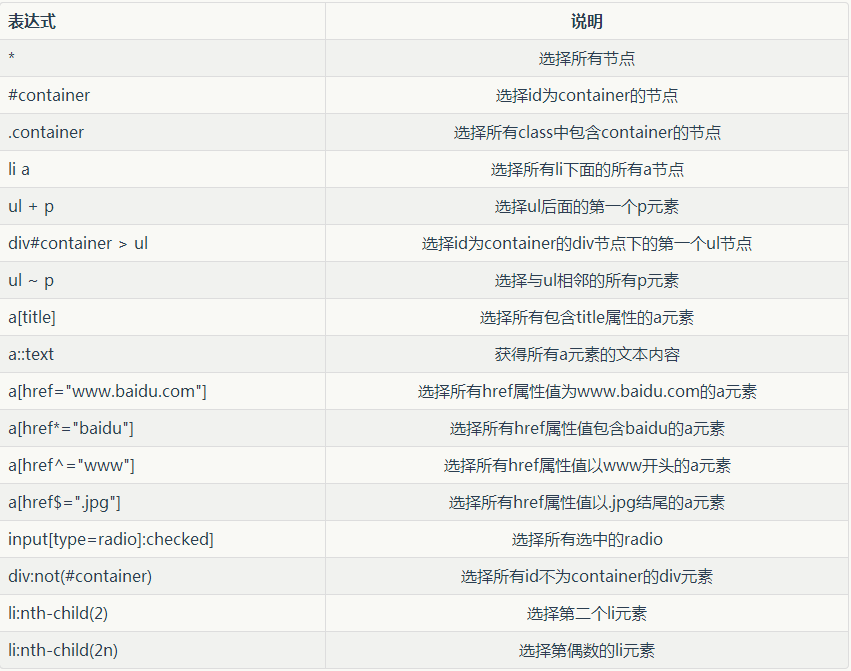
CSS常用选择器
Scrapy shell模式
在解析页面的时候如果要查看运行结果则必须要运行Scrapy爬虫发起一个请求,而Scrapy提供了一种方便的调试方法可以只请求一次。
scrpay shell http:
//blog.jobbole.com/111144/
文章解析
文章详情页
Xpath的解析方式
def
parse_detail
(self, response):
# xpath方式进行解析
# 文章标题
title = response.xpath(
'//div[@class="entry-header"]/h1/text()'
).extract_first()
# 发布时间
create_time = response.xpath(
'//p[@class="entry-meta-hide-on-mobile"]/text()'
).extract_first().replace(
'·'
,
''
).strip()
# 点赞数
# contains函数是找到class中存在vote-post-up这个类
up_num = response.xpath(
'//span[contains(@class,"vote-post-up")]/h10/text()'
).extract_first()
# 收藏数
fav_num = response.xpath(
'//span[contains(@class,"bookmark-btn")]/text()'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
,fav_num)
if
match_re:
fav_num = match_re.group(
1
)
else
:
fav_num =
0
# 评论数
comment_num = response.xpath(
'//a[@href="#article-comment"]/span/text()'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
, comment_num)
if
match_re:
comment_num = match_re.group(
1
)
else
:
comment_num =
0
# 文章正文
content = response.xpath(
'//div[@class="entry"]'
).extract_first()
# 获取标签
tags_list = response.xpath(
'//p[@class="entry-meta-hide-on-mobile"]/a/text()'
).extract()
tags_list = [element
for
element
in
tags_list
if
not
element.strip().endswith(
'评论'
)]
tags =
","
.join(tags_list)
CSS解析方式
def
parse_detail
(self, response):
# CSS方式进行解析
# 文章标题
title = response.css(
'div.entry-header h1::text'
).extract_first()
# 发布时间
create_time = response.css(
'p.entry-meta-hide-on-mobile::text'
).extract_first().replace(
'·'
,
''
).strip()
# 点赞数
up_num = response.css(
'span.vote-post-up h10::text'
).extract_first()
# 收藏数
fav_num = response.css(
'span.bookmark-btn::text'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
,fav_num)
if
match_re:
fav_num = match_re.group(
1
)
else
:
fav_num =
0
# 评论数
comment_num = response.css(
'a[href="#article-comment"] span::text'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
, comment_num)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1858
1858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









