







有些网站需要
登录
后才能爬取所需要的信息,此时可以设计爬虫进行模拟登录,原理是利用浏览器cookie。
一、浏览器访问服务器的过程
:
(1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request);
(2)Web服务器收到请求,发回响应信息(Http Response);
(3)浏览器解析内容呈现给用户。
二、利用
Fiddler
查看浏览器行为信息:
Http请求消息
:
(1)起始行:包括请求方法、请求的资源、HTTP协议的版本号
这里GET请求没有消息主体,因此消息头后的空白行中没有其他数据。
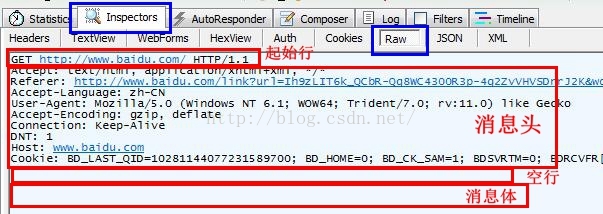
(2)消息头:包含各种属性
(3)消息头结束后的空白行
(4)可选的消息体:包含数据
Http响应消息:
(1)起始行:包括HTTP协议版本,http状态码和状态
(2)消息头:包含各种属性
(3)消息体:包含数据
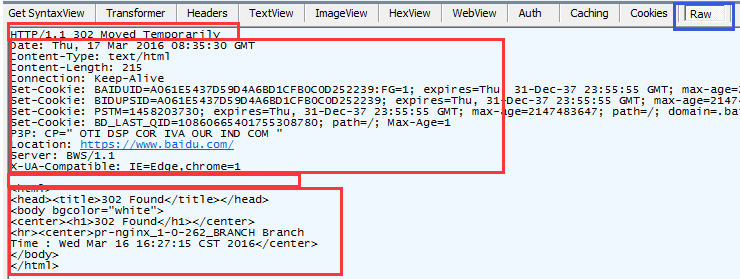
从上面可见,cookie在Http请求和Http响应的头消息中是很重要的属性。
三、什么是cookie
:
当用户通过浏览器首次访问一个域名时,访问的Web服务器会给客户端发送数据,以保持Web服务器与客户端之间的状态,这些数据就是Cookie。
它是站点创建的,为了辨别用户身份而储存在用户本地终端上的数据,其中的信息一般都是经过加密的,存在缓存或硬盘中,在硬盘中是一些小文本文件。
当访问该网站时,就会读取对应网站的Cookie信息。
作用
:记录不同用户的访问状态。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









