







论文链接:Efficient Estimation of Word Representations in Vector Space
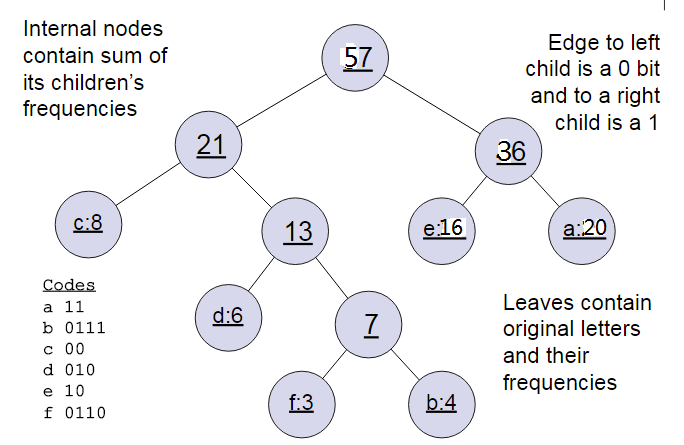
哈夫曼树
输入:权值为
(
w
1
,
w
2
,
.
.
.
,
w
n
)
(w1, w2, ..., wn)
(w1,w2,...,wn)的n个节点【对应文本的话,为每个词的词频】
输出:对应的哈夫曼树
step1:将
(
w
1
,
w
2
,
.
.
.
,
w
n
)
(w1, w2, ..., wn)
(w1,w2,...,wn)看做是有n棵树的森林,每棵树仅有一个几点;
step2:在森林中选择根节点权值最小的两棵树进行合并,得到一棵新的树,这两棵树分别作为新树的左右子树。
新树的根节点权值为左右子树的根节点权重之和;
step3:将之前的根节点权值最小的两棵树从森林中删除,并把新树加入森林;
step4:重复步骤2)和3)直到森林里只有一棵树为止。
在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
示例:我们有(a,b,c,d,e,f)共6个节点,节点的权值分布是(20,4,8,6,16,3)。
Hierarchical Softmax
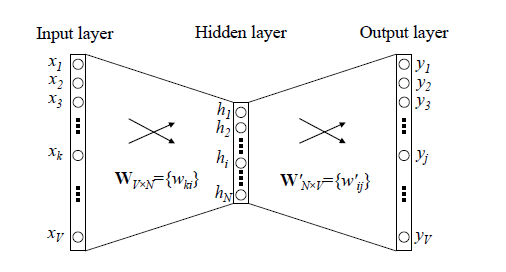
两个优化点:
1、输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入向量取平均的方法;
2、从隐藏层到输出层的改进,避免所有词的softmax概率【百万级别】,采用哈夫曼树,做 hierarchical softmax。
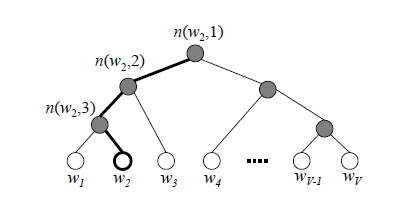
我们使用最大似然法来寻找所有节点的词向量和所有内部节点
θ
\theta
θ。先拿上面的
w
2
w_2
w2来看,我们期望最大化下面的似然函数:
∏
i
=
1
3
P
(
n
(
w
i
)
,
i
)
=
(
1
−
1
(
1
+
e
−
x
w
T
θ
1
)
)
(
1
−
1
(
1
+
e
−
x
w
T
θ
2
)
)
1
(
1
+
e
−
x
w
T
θ
3
)
\prod_{i=1}^3P(n(w_i), i) = (1-\frac{1}{(1+e^{-x_w^T\theta_1})})(1-\frac{1}{(1+e^{-x_w^T\theta_2})})\frac{1}{(1+e^{-x_w^T\theta_3})}
∏i=13P(n(wi),i)=(1−(1+e−xwTθ1)1)(1−(1+e−xwTθ2)1)(1+e−xwTθ3)1
定义 w w w经过的霍夫曼树某一个节点 j j j的逻辑回归概率为,其表达式为:
P
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
=
{
σ
(
x
w
T
θ
j
−
1
w
)
d
j
W
=
0
1
−
σ
(
x
w
T
θ
j
−
1
w
)
d
j
W
=
1
P(d_j^w|x_w, \theta_{j-1}^w)=\left\{ \begin{aligned} \sigma(x_w^T\theta_{j-1}^w) & & d_j^W=0 \\ 1- \sigma(x_w^T\theta_{j-1}^w) & & d_j^W=1 \end{aligned} \right.
P(djw∣xw,θj−1w)={σ(xwTθj−1w)1−σ(xwTθj−1w)djW=0djW=1
那么对于某一个目标输出词𝑤w,其最大似然为:
∏ j = 2 l w P ( d j w ∣ x w , θ j − 1 w ) = ∏ j = 2 l w ( σ ( x w T θ j − 1 w ) ) 1 − d j w ( 1 − σ ( x w T θ j − 1 w ) ) d j w \prod_{j=2}^{l_w}P(d_j^w|x_w, \theta_{j-1}^w) = \prod_{j=2}^{l_w}(\sigma(x_w^T\theta_{j-1}^w))^{1-d_j^w}(1-\sigma(x_w^T\theta_{j-1}^w))^{d_j^w} ∏j=2lwP(djw∣xw,θj−1w)=∏j=2lw(σ(xwTθj−1w))1−djw(1−σ(xwTθj−1w))djw
Negative Sampling
负采样方法
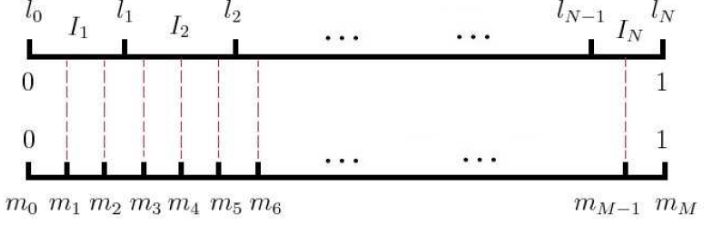
现在我们来看看如何进行负采样,得到
n
e
g
neg
neg个负例。word2vec采样的方法并不复杂,如果词汇表的大小为
V
V
V,那么我们就将一段长度为1的线段分成
V
V
V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词
w
w
w的线段长度由下式决定:
l e n ( w ) = c o u n t ( w ) Σ u ∈ v o c a b c o u n t ( u ) len(w) = \frac{count(w)}{\Sigma_{u\in{vocab}}count(u)} len(w)=Σu∈vocabcount(u)count(w)
在word2vec中,分子和分母都取了3/4次幂如下:
l
e
n
(
w
)
=
c
o
u
n
t
(
w
)
3
/
4
Σ
u
∈
v
o
c
a
b
c
o
u
n
t
(
u
)
3
/
4
len(w) = \frac{count(w)^{3/4}}{\Sigma_{u\in{vocab}}count(u)^{3/4}}
len(w)=Σu∈vocabcount(u)3/4count(w)3/4
在采样前,我们将这段长度为1的线段划分成 M M M等份,这里 M > > V M>>V M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而 M M M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从 M M M个位置中采样出 n e g neg neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。

















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











