










文章链接:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Abstract
Transformers在学习长序列依赖上有潜在优势,但也受限于语言模型序列长度固定的问题。我们提出了一个新颖的网络结构:Transformer-XL,在不打破时序关系的前提下可以突破固定长度的限制。它由片段级的循环机制(a segment-level recurrence mechanism)和全新的位置编码框架(positional encoding scheme)构成。该架构不进可以学习文本的长依赖关系,还可以解决上下文碎片问题。最终,Transformer-XL可以学习相较RNN长80%,相较原始Transformer长450%的依赖关系,在短文本和长文本上都取得了不错的效果,在推断阶段,比原始Transformer快1800倍。
代码已开源:https://github.com/kimiyoung/transformer-xl
Introduction
直接连接长距离词对的注意力机制容易优化,可以学习长距离依赖关系。Al-Rfou et al. (2018) 通过设计辅助损失为字符语言模型训练Transformer网络,它在性能上大大优于LSTMs。但是,这个结构是在独立的固定长度的片段上进行的,缺乏片段之间的信息联系。模型无法捕捉那些长度超过预定义的上下文长度的文本依赖关系。另外,这些片段是在不考虑句子或其它语义边界的情况下选择连续字符构成长度固定的片段(fixed-length segment)来构建的,这样的模型在前几步的预测中缺乏必要的上下文信息,继而带来优化及性能方面的问题,本文将该方面的问题称为上下文碎片问题(context fragmentation)。
为了解决这种固定长度限制的问题,我们提出了Transformer-XL(eXtra Long),引入了循环的概念到自注意力网络中。此外,代替从头计算每个新片段的隐状态,我们复用了上一个片段的隐状态。复用的这个隐状态作为当前片段的记忆单元,从而建立起片段之间的循环连接。这样的做法由于信息可以在片段的循环连接之间得以传播使得为特别长的依赖关系建模成为可能,同时也解决了上下文碎片的问题。另外,为了在复用状态时不会引发时序错乱的问题,我们说明了相对位置编码的必要性。因此,这篇文章的额外技术贡献就是我们引入了简单但是很实用的相对位置编码公式,可以泛化到比在训练期间更长的注意力序列。
本文的技术贡献包括:提出循环的概念到注意力网络中、提出全新的位置编码方式。这两个技巧缺一不可。Transformer-XL是首个同时在字符级别(character-level)和词级别(word-level)语言模型上超越RNN模型的自注意力模型。
Related Work
语言模型领域近年来的发展有很多,包括但不限于设计更好的编码上下文的新架构、改进的正则化和优化算法、softmax计算的加速以及对输出分布的优化等等。
为了捕捉语言模型中的长范围的上下文,部分工作直接将更长的上下文表示作为附加输入送入神经网络中。现有的工作包括人为定义上下文表示以及从数据中学习篇章级别的主题等等。
更广泛而言,在一般的序列建模问题中,如何捕捉长依赖关系一直是一个长期存在的研究问题。由于LSTM的普适性,大量工作关注解决其梯度消失的问题,包括更好的参数初始化、附加的损失计算、增强的记忆单元结构以及一些修改RNN结构以便于优化的方法等。与这些做法不同的是,本文的工作基于Transformer架构,同时证明了学习长依赖关系的能力对现实任务中的语言建模的优势。
Model
给定token的语料库 x = ( x 1 , . . . , x T ) x = (x_1, ..., x_T) x=(x1,...,xT),语言模型的任务是估计联合概率 P ( x ) = ∏ t P ( x t ∣ x < t ) P(x)=\prod_tP(x_t|x_{<t}) P(x)=∏tP(xt∣x<t)。基于因式分解,该问题简化为估计各条件因子。本工作采用标准的神经网络方法为各条件概率建模。具体而言,以一个可训练的神经网络将上下文编码为一个固定大小的隐藏状态,继而乘上词嵌入以获得其逻辑表示,该表示将送入softmax方程产生下一个token的概率分布。
Vanilla Transformer Language Models
为了将Transformer或自注意力用到语言模型上, 核心问题是训练一个可以高效编码任意长度序列到固定长度表征的Transformer。给定有限的存储和计算资源,一个简单的方案是用一个绝对的Transformer解码来处理整个文本序列,和FFN比较相似。然而实践中由于资源的限制,这往往不太可行。
一个可行但比较粗糙的方案是:将整个文本切分成易处理的短片段,在每一个片短上训练模型,忽略之前片段的上下文信息。这由Al-Rfou et al. (2018) 提出,称为Vanilla Transformer,如下图1。
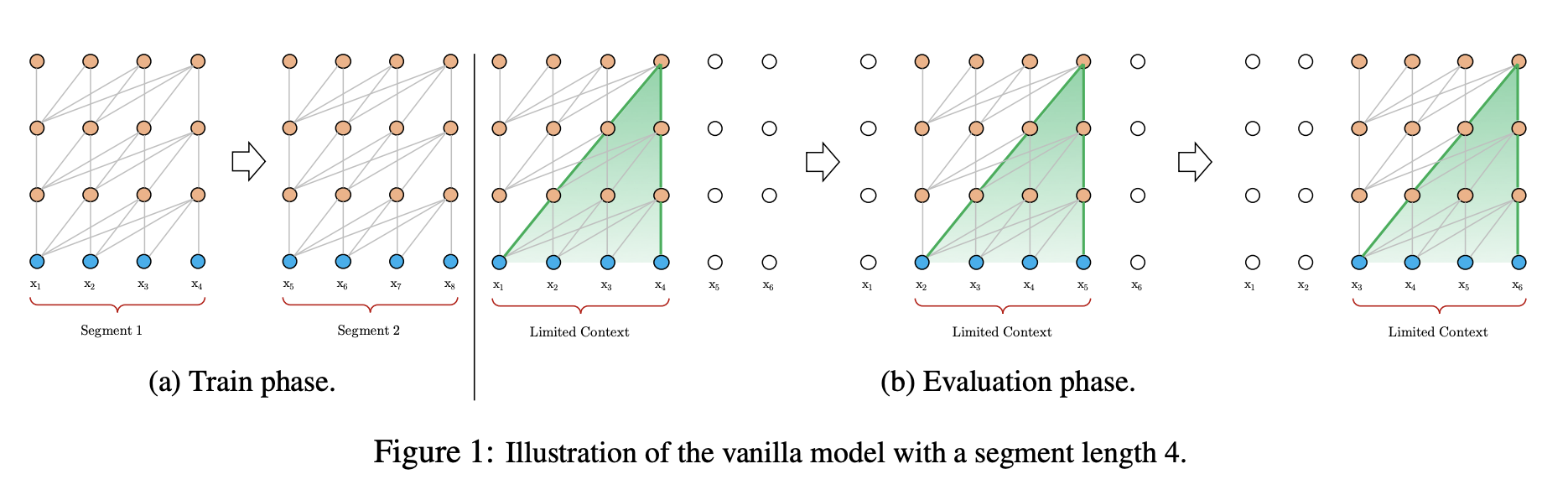
在这种训练范式下,信息无法在片段间流动。使用固定长度的上下文存在两点关键限制:一、最长依赖长度上限是由片段长度决定的,在字符级别的语言模型中,片段长度也就好几百,即使自注意力机制能在一定程度上缓解RNN梯度消失的问题,但该模型未能充分利用自注意力机制的这一优化优势。二、尽管可以通过padding延续文本的句子或其他语义边界特性,但事实上为了提高效率,简单将长文本划分成固定长度的片段已然成为标准做法,这种做法又会导致上下文碎片问题。
在评估阶段的每一步中,the vanilla model依旧采用训练阶段相同的片段长度,但仅对最后一个位置进行预测。而在下一步中,片段将向右平移一个位置,再重新从头开始处理整个片段进行当前片段最后位置的预测。如图所示,该过程确保每一次预测用到了训练阶段能看到的最长的上下文,同时缓解了训练阶段的上下文碎片问题。但相应的评估阶段的计算成本也有所提高。这一点在本文提出的框架中得以解决。
Segment-Level Recurrence with State Reuse
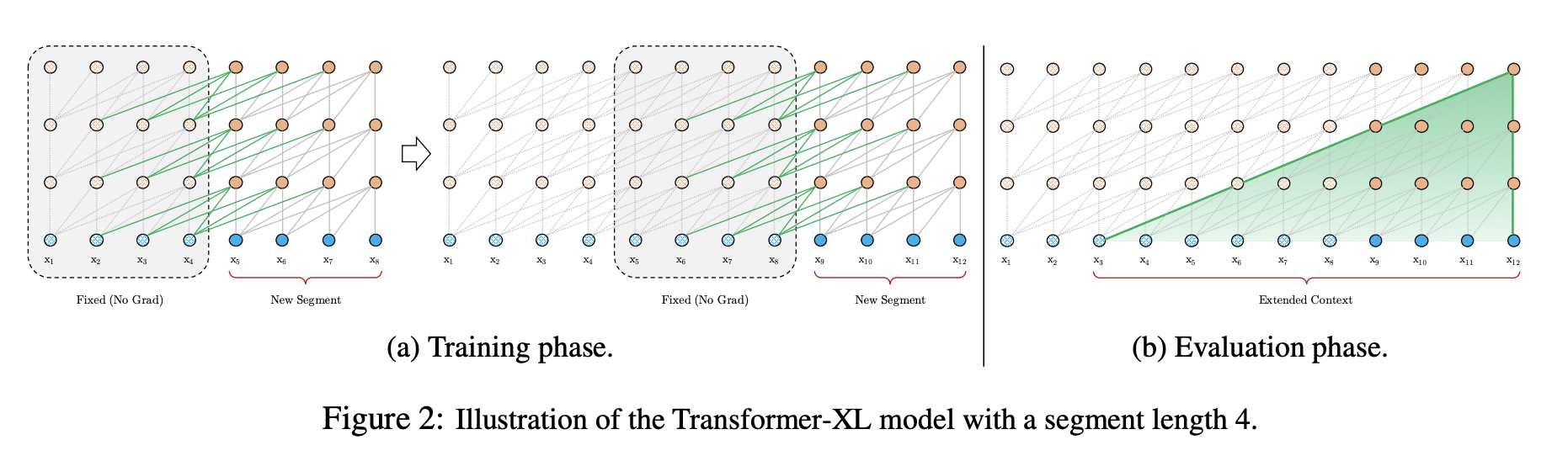
为了解决使用固定长度上下文带来的限制,本文提出在Transformer架构中引入循环机制,其过程如Figure 2所示。在训练阶段,前一个片段计算得到的隐藏状态序列将被固定(fixed)并缓存起来(cached),在模型处理接下来的一个新片段时,刚刚缓存的隐藏层序列将作为一个扩展上下文进行复用。尽管梯度仍保留于每个片段内部,但这个附加的输入使得网络可以处理历史信息,继而使得模型可以对长依赖建模,同时避免了上下文碎片问题。
该过程以公式化形式将表述如下:
两个长度为L的连续片段
s
τ
s_\tau
sτ和
s
τ
+
1
s_{\tau+1}
sτ+1,
s
τ
=
[
x
τ
,
1
,
.
.
.
,
x
τ
,
L
]
s_\tau=[x_{\tau,1},...,x_{\tau,L}]
sτ=[xτ,1,...,xτ,L]
s
τ
+
1
=
[
x
τ
+
1
,
1
,
.
.
.
,
x
τ
+
1
,
L
]
s_{\tau+1}=[x_{\tau+1,1},...,x_{\tau+1,L}]
sτ+1=[xτ+1,1,...,xτ+1,L]
第
τ
\tau
τ个片段
s
τ
s_\tau
sτ的第
n
n
n层隐状态序列为:
h
τ
n
∈
R
L
×
d
h_\tau^n\in\mathbb{R}^{L\times d}
hτn∈RL×d, d是维度。
s
τ
+
1
s_{\tau+1}
sτ+1的第
n
n
n层隐状态序列的计算如下:
h
~
τ
+
1
n
−
1
=
[
SG
(
h
τ
n
−
1
)
○
h
τ
+
1
n
−
1
]
\widetilde{h}_{\tau+1}^{n-1}=[\text{SG}({h}_{\tau}^{n-1})○{h}_{\tau+1}^{n-1}]
h
τ+1n−1=[SG(hτn−1)○hτ+1n−1]
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
=
h
τ
+
1
n
−
1
W
q
T
,
h
~
τ
+
1
n
−
1
W
k
T
,
h
~
τ
+
1
n
−
1
W
v
T
,
{q}_{\tau+1}^{n}, {k}_{\tau+1}^{n}, {v}_{\tau+1}^{n}={h}_{\tau+1}^{n-1}W_q^T,\widetilde{h}_{\tau+1}^{n-1}W_k^T,\widetilde{h}_{\tau+1}^{n-1}W_v^T,
qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h
τ+1n−1WkT,h
τ+1n−1WvT,
h
τ
+
1
n
=
Transformer-Layer
(
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
)
{h}_{\tau+1}^{n}=\text{Transformer-Layer}({q}_{\tau+1}^{n}, {k}_{\tau+1}^{n}, {v}_{\tau+1}^{n})
hτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)
其中函数
SG
(
⋅
)
\text{SG}(\cdot)
SG(⋅)表示停止梯度计算,
h
u
○
h
v
{h}_u○{h}_v
hu○hv表示两个隐藏层序列沿length维度的拼接,
W
⋅
W_{\cdot}
W⋅表示模型参数。与标准Transformer相比,关键的不同点在于,
k
τ
+
1
n
{k}_{\tau+1}^{n}
kτ+1n和
v
τ
+
1
n
{v}_{\tau+1}^{n}
vτ+1n基于扩展后上下文
h
~
τ
+
1
n
−
1
\widetilde{h}_{\tau+1}^{n-1}
h
τ+1n−1得来,因此
h
τ
+
1
n
{h}_{\tau+1}^{n}
hτ+1n可从之前的片段中获取信息。Figure 2(a)中由绿色路径标注了本文的特殊设计。
通过在每两个连续片段之间应用循环机制,建立起了隐藏层片段级别的循环。因此有效的上下文信息将不仅仅在两个片段内被利用。然而需要注意的是,
h
τ
+
1
n
{h}_{\tau+1}^{n}
hτ+1n和
h
τ
n
−
1
{h}_{\tau}^{n-1}
hτn−1之间的循环依赖每一片段将向下移动一层,这与传统的基于RNN的语言模型中的同层循环是有所不同的。最终,最长依赖长度随层数和片段长度呈线性增长,即
O
(
N
×
L
)
O(N\times L)
O(N×L),如Figure 2(b)的阴影部分所示。这与一训练基于RNN的语言模型采用的方法truncated BPTT类似。但与其不同的是,本文提出的方法缓存的是隐藏状态序列而非上一序列,同时还应该结合后文将介绍的相对位置编码技术一起使用。
该架构除了能利用更长的上下文以及解决上下文碎片问题外,循环机制还使得评估时的效率显著提高。具体而言,在评估阶段,之前片段的表示可以同the vanilla model一样进行重用。
最后需要注意的是,循环机制不必仅限于邻接的前一个片段。理论上,在GPU内存允许的情况下,可以缓存尽可能多的之前的片段,并在处理当前片段时复用所有的这些片段作为额外的上下文。因此,可以缓存一个预定义的长度—— M M M个旧的隐藏状态,并将它们表示为记忆单元 m τ n ∈ R M × d m_{\tau}^n\in\mathbb{R}^{M\times d} mτn∈RM×d。实验中,本文将 M M M设为等同于片段长度的大小,并在评估中,将其值加倍增长。
Relative Positional Encodings
上述方案存在的问题是重用隐藏层状态的顺序问题,即在重用时是如何保证位置信息的连贯问题(the positional information coherent)。在标准Transformer中,序列顺序信息是通过一个位置编码集合
U
∈
R
L
m
a
x
×
d
\mathbb{U}\in \mathbb{R}^{L_{max}\times d}
U∈RLmax×d提供的,其中第
i
i
i行
U
i
\mathbb{U}_i
Ui表示某一片段中第
i
i
i个绝对位置,
L
m
a
x
L_{max}
Lmax表示建模的最大长度;随后输入将有文本的词嵌入表示和位置编码相加得来。倘若将这样的位置编码方式直接运用到本文的循环机制中,隐藏状态序列的计算如下:
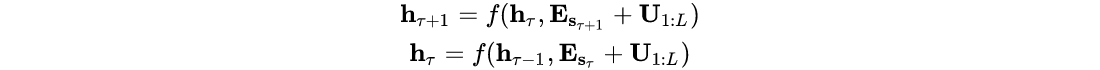
其中
E
s
τ
\mathbb{E}_{s_\tau}
Esτ表示序列
s
τ
{s_\tau}
sτ的词嵌入,
f
f
f表示一个转换方程。需要注意的是,
E
s
τ
\mathbb{E}_{s_\tau}
Esτ和
E
s
τ
+
1
\mathbb{E}_{s_{\tau+1}}
Esτ+1用到了同样的位置编码
U
1
:
L
\mathbb{U}_{1:L}
U1:L。因此,对于任意的
j
=
1
,
.
.
.
,
L
j = 1,...,L
j=1,...,L,模型没有用于分辨
x
τ
,
j
x_{\tau, j}
xτ,j和
x
τ
+
1
,
j
x_{\tau+1, j}
xτ+1,j位置区别的信息,继而造成严重的性能损失。
$$
为了避免上述问题,最基础的想法是在隐藏状态中仅编码相对位置信息。从概念上来说,位置编码给予了模型如何汇聚信息的时序线索或偏置,即注意力。出于同样的目的,替代将统计偏置纳入初始化embedding中,可以在每一层中将类似的信息映射到attention分值上。更重要的是,以相对位置定义时序偏差是更直观且有利于泛化的。例如,当一个query向量 q τ , i q_{\tau, i} qτ,i在key向量 k τ , ≤ i k_{\tau, \leq i} kτ,≤i上计算注意力时,无需了解每一个key向量的绝对位置,了解每一个key向量 k τ , j k_{\tau, j} kτ,j和自身 q τ , i q_{\tau, i} qτ,i的相对位置 i − j i-j i−j即可反映片段内的时序关系。实践中,可以创建一个相对位置编码集合 R ∈ R L m a x × d R\in \mathbb{R}^{L_{max}\times d} R∈RLmax×d,其中第 i i i行 R i \text{R}_i Ri表示 i i i和其它位置的相对距离。通过将相对位置动态地映射到注意力分值中,query向量可以轻松地根据不同的距离区分 x τ , j x_{\tau, j} xτ,j和 x τ + 1 , j x_{\tau+1, j} xτ+1,j的表示,继而使得状态重用机制可行。与此同时,由于绝对位置信息可以递归地从相对距离中获取,时序信息并未丢失。
之前,相对位置编码的思想已被用于机器翻译和音乐生成任务中。这里,本文提出一种不同的相对位置编码新形式的推导,不仅与其绝对位置有一对一的对应关系,而且具有更好的泛化能力。首先,在标准Transformer中,同一片段内的query向量
q
i
q_i
qi和key向量
k
j
k_j
kj之间的注意力得分计算可做如下分解:
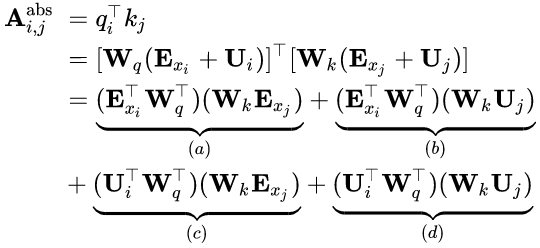
根据仅依赖相对位置信息的思想,将上式中的四项重新参数化如下:
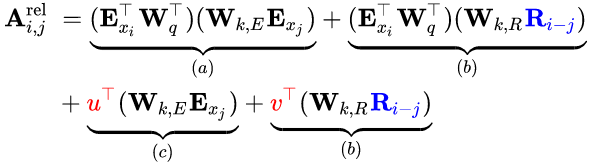
- 将所有在公式项 ( b ) (b) (b)和 ( d ) (d) (d)中出现的计算key向量用到的绝对位置编码 U j \mathbb{U}_j Uj替换为对应的绝对位置编码 R i − j \mathbb{R}_{i-j} Ri−j。这从本质上反映了只考虑相对位置的前提。需要注意的是, R \mathbb{R} R是没有可训练参数的正弦编码矩阵。
- 引入了可训练参数来替代公式项中的query向量。在采用相对位置编码的情况下,无论是哪个查询位置,此处的query向量应是一致的,其位置信息由相对位置编码反映,因此此处采用一个可训练的参数表示。出于同样的原因,将公式项中的替换为可训练参数。
- 将两个权重矩阵和区别开来,以分别表示基于内容的key向量和基于位置的key向量。
在这样全新的参数化表示下,每一项都具备一个直观的含义: ( a ) (a) (a)表示内容上的关联(content-based addressing); ( b ) (b) (b)捕捉了依赖内容的位置偏差; ( c ) (c) (c)控制着全局内容偏差; ( d ) (d) (d)编码了全局位置偏差。
综上,带有单个注意力头的
N
N
N层的Transformer-XL的计算过程如下:
对于
n
=
1
,
2
,
.
.
.
,
N
n=1,2,...,N
n=1,2,...,N:
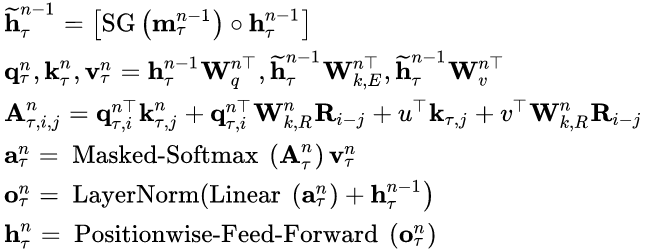
初始化
h
τ
0
:
E
s
τ
h_{\tau}^0:\mathbb{E}_{s_\tau}
hτ0:Esτ为词嵌入序列。此外,计算
A
\mathbb{A}
A的效率随序列长度呈二次方变化。下面将介绍一个对
A
\mathbb{A}
A的高效计算方式,其效率随序列长度呈线性变化。
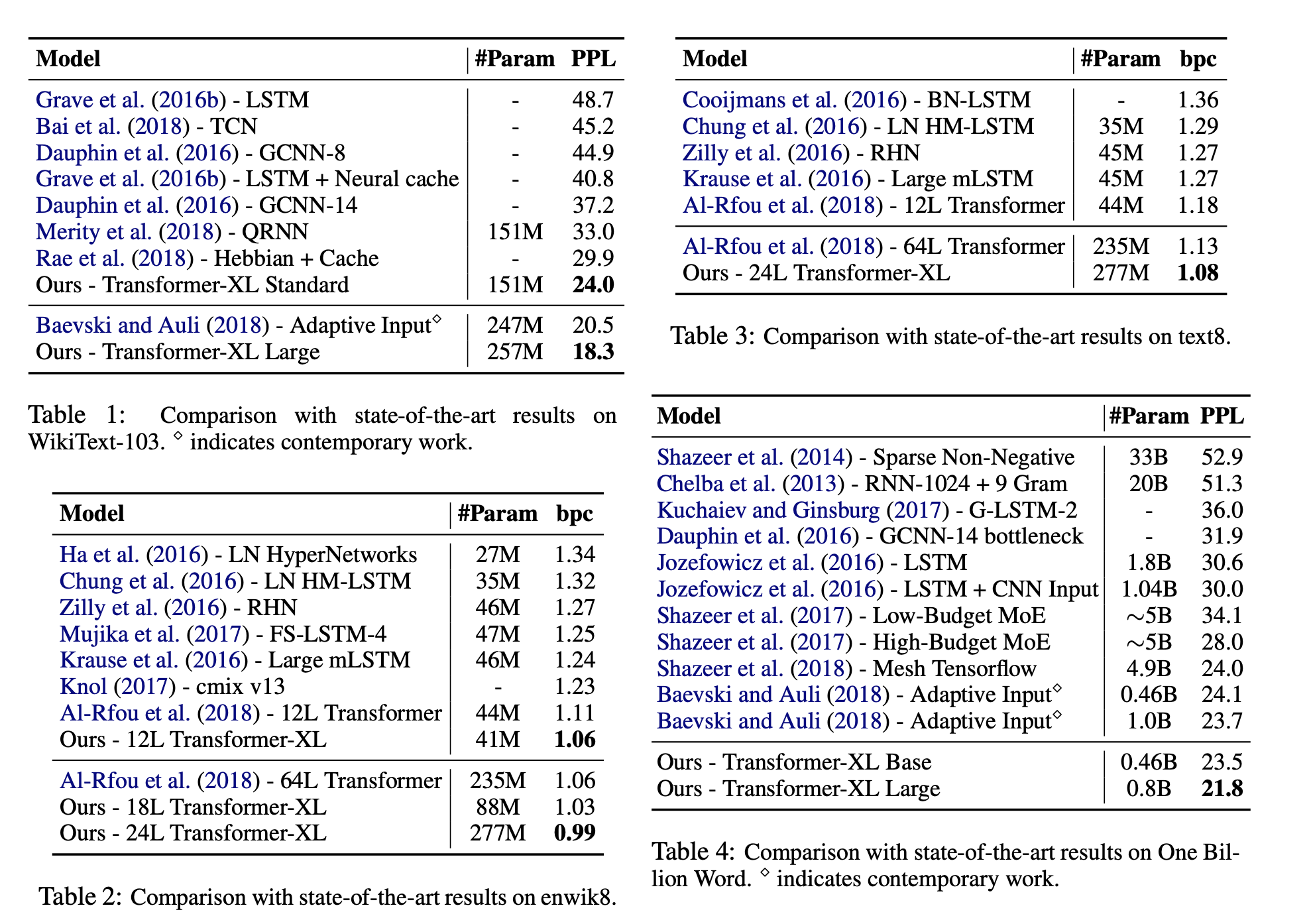
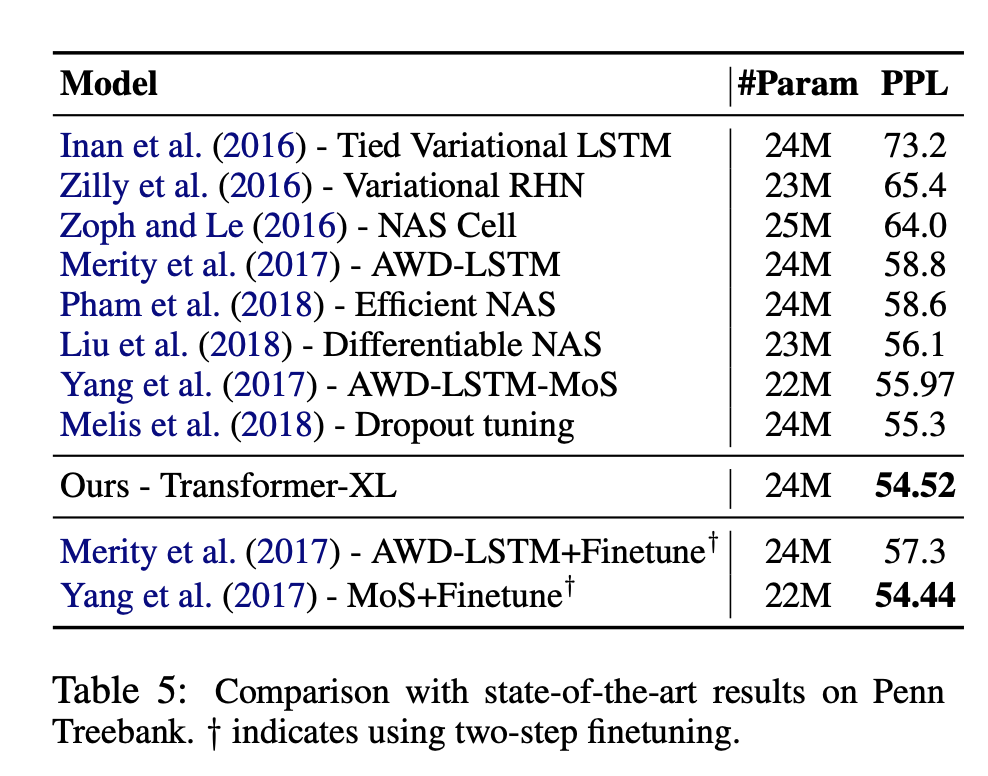
Experiments
Conclusions
Transformer-XL在困惑度指标上取得了很强的结果,可以建模比RNNs和原始Transformer更长的序列依赖关系,在推断上,也有着显著的加速,可以生成条理清楚的文章。我们设想Transformer-XL在文本生成、无监督特征学习、图像和语音建模等领域有趣的应用。

















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











