









本套大屏,在某云服务大规模测试环境,良好运行3年+.
本文主要展示这套监控大屏的逻辑架构.不做具体操作与配置的解释.
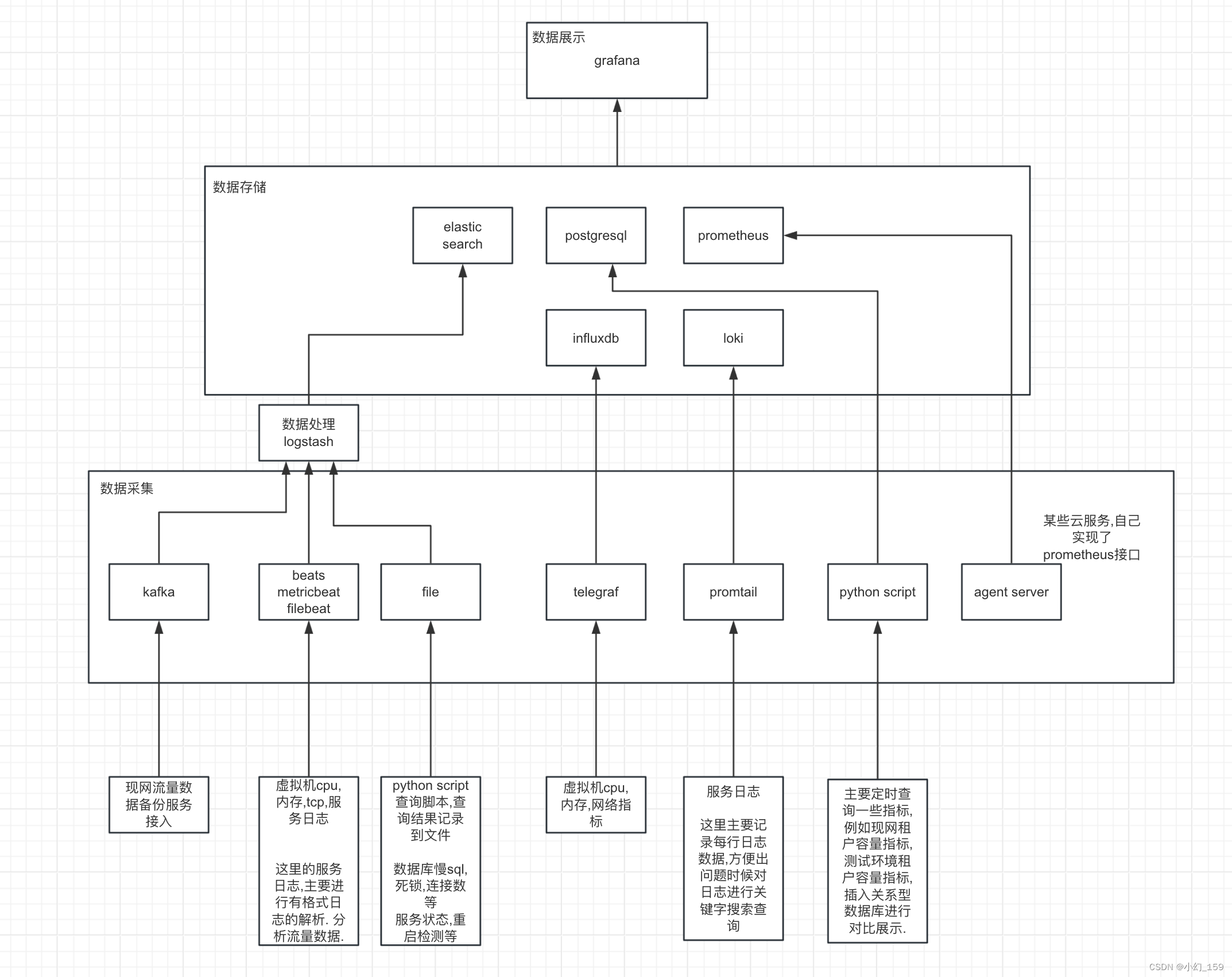
监控主要分为三部分:
- 数据展示部分
- 数据存储
- 数据采集
1. 数据展示
数据展示方面主要使用grafana
2. 数据存储
根据数据种类和特性和用途的不同,本套监控采用了几种数据存储
- elasticsearch
- postgresql
- prometheus
- influxdb
- loki
- 可以使用其他任何grafana支持的数据源
3.数据采集和处理
- logstash 数据处理,处理后的数据写入elasticsearch
- kafka 主要是其他团队的数据, 会提供一条kafka日志流, 我们通过logstash读取后进行处理,写入elasticsearch
- beats-metricbeat 主要读取虚拟机(服务器)的基本指标数据,包括cpu,内存,网络资源,磁盘,进程等指标,写入elasticsearch
- beats-filebeat 主要读取各个云服务产生的有格式化的日志,通过logstash进行格式化解析, 变成各种指标写入elasticsearch, 主要用于对服务流量访问日志的获取解析展示.
- file
- telegraf 实现的功能跟3完全一样,但是对接的存储是influxdb, 最开始就是用3 metricbeat来采集数据,写入elastic进行展示, 后来当虚拟机数量提升, 指标数量较高,es的存储有点跟不上了,因为es主要是为搜索服务的,同样的指标量会占用大量存储资源, 通过调研选用了telegraf, 存储占用大幅下降,还有展示页面的加载速度大幅提升.原来只能展示1小时,选到3小时就会比较卡,选择24小时的范围基本无法展示. 换了telegraf采集+influxdb存储之后,选24小时范围的查询毫无压力,存储时间也超过3个月
- promtail 主要功能为日志搜集, 使用loki存储, 实现日志转储,关键字查询的功能. 因为各个服务的机器给日志存储留用空间较小.并且是大规模环境,频繁进行性能压测,日志打印刷新非常快速. 基本十几分钟就会达到配置的日志存储上限,这时候会把旧的日志刷掉. 测试发现问题后,找开发定位非常麻烦. 又要重新复现. 用这个组件之后,目前可以把所有服务的日志,统一在loki服务器上存储1个月, 直接按照组件名+服务器id+时间 +关键词过滤,可以很快的查到相关日志.
- python script 某些自定义的数据,使用开源组件采集不便, 自己使用脚本采集, 然后 通过写入文件,logstash解析,进入elasticsearch ,或 直接写入关系型数据库. 通过grafana进行展示.
- agent-server 某些云服务,自己实现了prometheus的拉取接口, 暴露自己的监控指标,这部分直接部署prometheus对这些云服务agent-server进行拉取.














 3110
3110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









