






#Attention Please
#网上看了很多关于NSGA2的讲解,但是总觉得少了点意思,为此经过多出选择裁剪给出了最通俗易懂的讲解,如果错误欢迎批评指正。
#以下部分内容来源于网上公开的讲解。
1、原理
了解NSGA2的前提是学会NSGA,而对于NSGA算法,我们需要了解非支配排序和遗传算法,进一步地就过渡到NSGA2;
NSGA2也就是用到了所谓的快速非支配排序算法,以及采用精英策略对新产生的父代和子代解进行选择;
这里精英策略作为一个主循环,在主循环里嵌套选择策略,对新生成的解进行快速非支配排序。
2、过程
随机初始化产生一组解--->非支配排序进行选择--->交叉--->变异--->将旧解【父代解】和新解【子代解】合并--->对合并后的解进行精英策略选择生成父代--->循环以上过程直到达到终止条件。
补充说明:
二进制锦标赛法作为选择操作的一种方法,具体步骤如下:
假设种群规模为n,该法的步骤为:
step1.随机产生n个个体作为第一代(其实这步准确的说不是属于选择操作的,但每个算子并没有绝对的界限,这个是在选择操作之前的必做之事);
step2.从这n个个体中随机(注意是随机)选择k(k小于n)个个体,k的取值小,效率就高(节省运行时间),但不宜太小,一般取为n/2(取整);
step3.从这k个个体中选择最大的一个个体(涉及到排序的方法),作为下一代n个个体中的一个个体
step4.重复2-4步,至得到新的n个个体;
step5.进行这新的n个个体之间的交叉操作。
3、关键步骤
适应度:可以通俗理解就是你定义的所谓目标函数,当然几个目标【多目标】就可以算出几个适应度的数值。
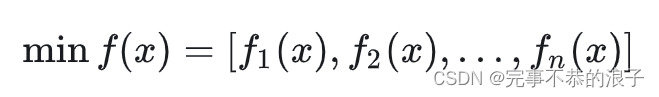
如上式中的可以作为其中一个适应度函数。
更形象的,我们可以建立一个二维坐标系,这里的两个维度代表的是2个目标的适应度函数。
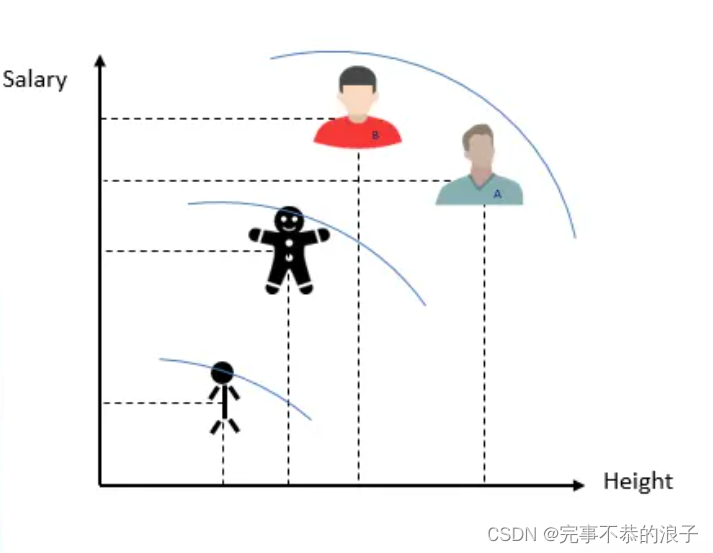
非支配排序:以上图为例,我们可以看到4个小人分别位于不同的层,并且在两个坐标轴都有对应的数值:Salary和Height,现在要做的就是:A、B、C、D这四个人的综合评价指标,谁的更好呢?我们到底是更多的考虑身高还是更多的考虑薪资水平呢?由此,我们引出非支配排序的概念。
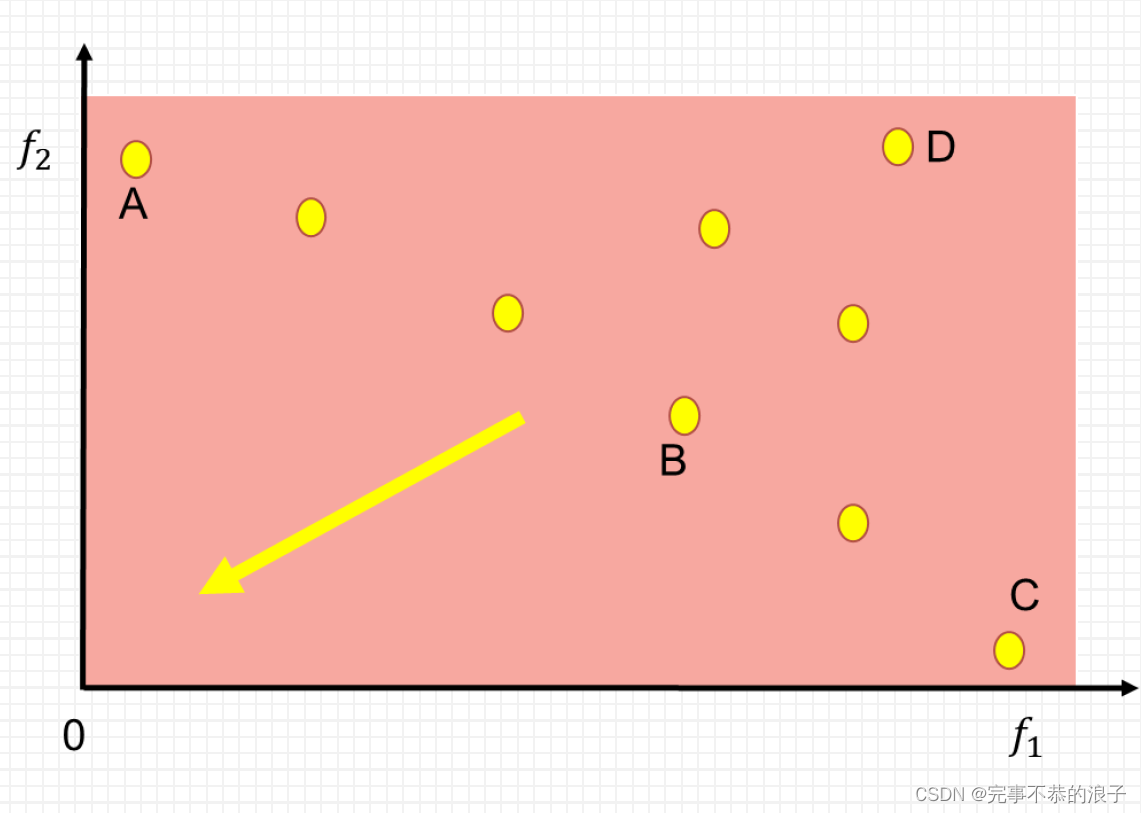


拥挤距离:以下定义来源于原论文,《A Fast and Elitist Multiobjective Genetic Algorithm:NSGA-II》

中文版本的解释如下:


为了获得对种群中某一特定解附近的密度估计, 我们沿着对应目标计算这个解两侧的两点间的平均距离。 这个值是对用最近的邻居作为顶点形成的长方体的周长的估计称之为拥挤距离)。在图 1 中, 第i 个解在其前沿的拥挤距离(用实心圆标记)是长方体的平均边长(用虚线框表示。(用实心圆标记的点是同一非支配前沿的解)

非支配排序:

快速非支配排序:NSGA2


精英策略:

首先有一群具有多个目标的个体做为父代,在每个迭代中,在GA操作之后合并父代和子代。通过非支配排序,我们将所有个体分类到不同的帕累托最优前沿层次。然后按照不同层次的顺序从帕累托最优前沿选择个体作为下一个种群。对于多样性保护,还计算了“拥挤距离”。拥挤距离比较将算法各阶段的选择过程引向一致展开的帕累托最优前沿。


4、引用
[8]A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II
5、附赠一张很精辟的图

6、总结说明
(1)排挤算法和精英策略
原始的NSGA算法中使用共享函数的方法来维持物种的多样性,这种方法包含一个**共享参数,该参数为所求解问题中所期望的共享范围。在该范围内,两个个体共享彼此的适应度。**但是该方法有两个难点:
(1).共享函数方法在保持多样性的性能很大程度上依赖于所选择的共享参数值。
(2).种群中的每个个体都要与其余的个体相比较,因此该方法的全局复杂度为O(N^2)。
在NSGA2中使用了排挤算法和精英策略来代替共享函数算法。而要实现这两种方法,首先我们需要定义两个操作:密度估算和排挤算子。
密度估算方法:
要对拥挤距离进行计算,则需要根据每个目标函数对种群中的所有个体按升序进行排序。第一个和最后一个个体的拥挤距离设为无穷大,第i个个体的拥挤距离则设为第i+1和第i个体的所有目标函数值之差的和。
(2)为何拥挤度距离大的值会被选择?
通过一张图理解,可以看到在左上角和右下角区间内,密度明显比Cuboid里的密度大,这里的,需要注意的是拥挤距离必须放在同一类前端才有讨论的意义。我的理解为,拥挤距离越小,说明密度越大,这一片区域“探索”的越彻底,容易陷入局部最优解。反观密度小的区域内,密度小,说明“探索”的并不彻底,有很大的开发价值。
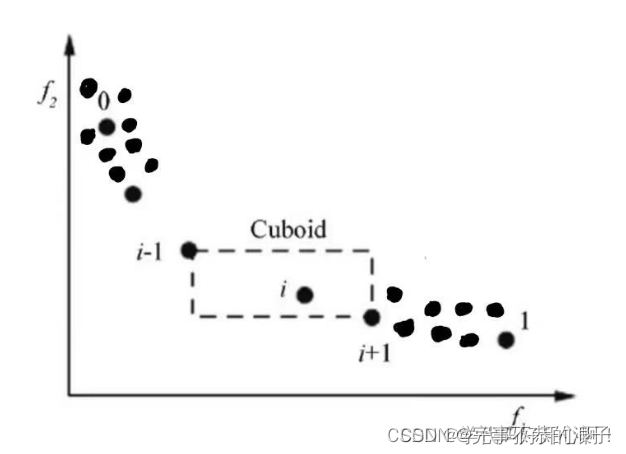

通过适应度测试得出不同前端的个体。例如F1、F2、F3。为了保持种群数量稳定性。从图中可以看出F1、F2前端的所有都会进入下一轮筛选。而F3中会有部分被淘汰掉……
所以会优先选出拥挤距离大的个体,来进入下一轮筛选,从而全面的探索各种可能性。
如果你觉得不错,佛系随缘打赏,感谢,你的支持是我继续耕耘的动力。


















 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









