






学习目标:mIoU(均交并比)
交并比:Intersection over Union
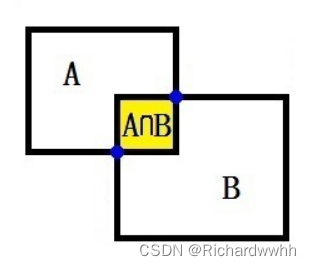
公式:
S
A
∪
B
=
S
A
+
S
B
−
S
A
∩
B
S_{A\cup{B}} = S_A + S_B - S_{A\cap{B}}
SA∪B=SA+SB−SA∩B
例如:语义分割中的IoU
语义分割问题中的两个集合为:真实值(ground truth) 和预测值(prediction segmentation),该比例可以变形为真正数(Intersection)比上真正(TP)
MIoU的计算:
- (真正)TP: 预测正确(真),预测结果为正样本,实际也为负样本
- (假正)FP: 预测错误(假),预测结果为正样本,实际为负样本
- (假负)FN: 预测错误(假),预测结果为负样本,实际为正样本
- (真负)TN: 预测正确(假),预测结果为负样本,实际也为负样本
以pascal数据集为例
(其中包含21个类别,分别对每个类别求IoU)
令
k
k
k表示类别,
(
k
+
1
)
(k+1)
(k+1)表示加上了背景类,
i
i
i表示真实类别,
j
j
j表示预测类别
那么有
- p ( i , j ) p_{(i,j)} p(i,j)表示将 i i i类别预测为 j j j类别,为假负(FN)
- p ( i , i ) p_{(i,i)} p(i,i)表示将 i i i类别预测为 i i i类别,为真正(TP)
-
p
(
j
,
i
)
p_{(j,i)}
p(j,i)表示将
j
j
j类别预测为
i
i
i类别,为假正(TP)
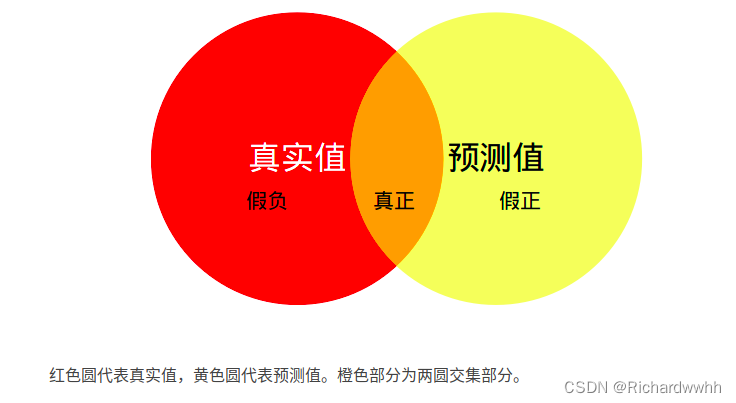
从韦恩图可以看出,两个计算公式是等价的,理想情况就是所有预测值都是与真实值相符,也就是两个圆重合,比例为1
所以mIoU的公式可以用下列式子表示
m I o U = 1 k + 1 ⋅ ∑ i = 0 k ( p ( i , i ) ∑ j = 0 k p ( i , j ) + ∑ j = 0 k p ( j , i ) − p ( i , i ) ) mIoU = \frac{1}{k+1} \cdot \sum_{i=0}^{k} (\frac{p_{(i,i)}}{\sum_{j=0}^{k}p_{(i,j)} + \sum_{j=0}^{k}p_{(j,i)} - p_{(i,i)}}) mIoU=k+11⋅i=0∑k(∑j=0kp(i,j)+∑j=0kp(j,i)−p(i,i)p(i,i))
比如说我们有三个类别:1, 2, 3
那么加上背景类别0之后,预测类别为1的IoU就是
I o U ( p r e d i c t i o n → 1 ) = p ( 1 , 1 ) ∑ j = 0 3 p ( 1 , j ) + ∑ j = 0 k p ( j , 1 ) − p ( 1 , 1 ) IoU(prediction \rightarrow 1) = \frac{p_{(1,1)}}{\sum_{j=0}^{3}p_{(1, j)} + \sum_{j=0}^{k}p_{(j,1)} - p_{(1,1)}} IoU(prediction→1)=∑j=03p(1,j)+∑j=0kp(j,1)−p(1,1)p(1,1)
mIoU计算实例:
混淆矩阵:表示预测值和真实值之间的差距的矩阵,形式如下
(
TP
FN
FP
T
N
)
\left( \begin{matrix} \textbf{TP} & \textbf{FN} \\ \textbf{FP} & TN \end{matrix} \right)
(TPFPFNTN)
可见:
- 混淆矩阵的每一行之和=实际为该类的所有样本之和
- 混淆矩阵的每一列之和=预测为该类的所有样本之和
那么混淆矩阵的每一行(FN+TP)再加上每一列(FP+TP),最后减去对角线上(TP)的值:















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









