







location 匹配规则
| 规则 | 匹配 |
|---|---|
| = | 严格匹配。如果请求匹配这个 location,那么将停止搜索并立即处理此请求 |
| ~ | 区分大小写匹配(可用正则表达式) |
| ~* | 不区分大小写匹配(可用正则表达式) |
| !~ | 区分大小写不匹配 |
| !~* | 不区分大小写不匹配 |
| ^~ | 前缀匹配 |
| @ | “@” 定义一个命名的location,使用在内部定向时 |
| / | 通用匹配,任何请求都会匹配到 |
location 原文
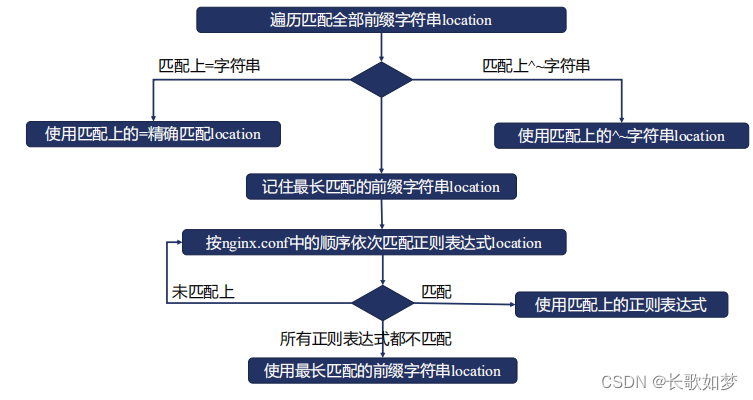
A location can either be defined by a prefix string, or by a regular expression. Regular expressions are specified with the preceding “~*” modifier (for case-insensitive matching), or the “~” modifier (for case-sensitive matching). To find location matching a given request, nginx first checks locations defined using the prefix strings (prefix locations). Among them, the location with the longest matching prefix is selected and remembered. Then regular expressions are checked, in the order of their appearance in the configuration file. The search of regular expressions terminates on the first match, and the corresponding configuration is used. If no match with a regular expression is found then the configuration of the prefix location remembered earlier is used.
If the longest matching prefix location has the “^~” modifier then regular expressions are not checked.
Also, using the “=” modifier it is possible to define an exact match of URI and location. If an exact match is found, the search terminates. For example, if a “/” request happens frequently, defining “location = /” will speed up the processing of these requests, as search terminates right after the first comparison. Such a location cannot obviously contain nested locations.
location 的定义分为两种:
- 前缀字符串(prefix string)
- 正则表达式(regular expression),具体为前面带 ~* 和 ~ 修饰符的
而匹配 location 的顺序为:
- 检查使用前缀字符串的 locations,在使用前缀字符串的 locations 中选择最长匹配的,并将结果进行储存。
- 如果符合带有 = 修饰符的 URI,则立刻停止匹配
- 如果符合带有 ^~ 修饰符的 URI,则也立刻停止匹配。
- 如果不满足2和3,使用1中记住的最长匹配前缀字符串location,按照定义文件的顺序,检查正则表达式,匹配到就停止。
- 当正则表达式匹配不到的时候,使用之前储存的前缀字符串
location的两种语法
约定: []表示里面的参数能省略, <>表示里面的参数不能省略.
第一种语法分为3个部分, 分别是: location关键字+@name别名(name是自己取的名字)+如何处理, 这个语法很简单, 就是做内部跳转, 这里不讨论了.
location @name { … }
第二种语法分为4个部分, 分别是: location关键字 + 匹配方式符号(可省略)+匹配规则+如何处理, 这个最复杂也是最常用, 我们只讨论这个.
location [ = | ~ | ~* | ^~ ] uri { … }
普通匹配和正则匹配
[ = | ~ | ~* | ^~ ]分为两种匹配模式, 分别是普通匹配和正则匹配.
普通匹配概述
-
= : 这代表精准匹配全路径, 命中它后直接返回, 不再进行后续匹配, 优先级最高.
-
^~ : 这代表精准匹配开头, 命中开头后直接返回, 不再进行后续匹配, 优先级第二.
-
无匹配方式符号 : 这代表通用性匹配, 命中后还会继续后续匹配, 最后选取路径最长的匹配, 并储存起来, 优先级第四.
正则匹配概述
-
~: 这是区分大小写的正则匹配, 命中后则不进行后续匹配, 立即返回, 优先级第三.
-
*~: 不区分大小写的正则匹配, 命中后则不进行后续匹配, 立即返回, 优先级第三.
注:正则匹配中 ~ 和 * ~ 优先级一样, 它们按照从上到下的顺序进行匹配, 最先命中的立即返回, 后续的不会进行匹配, 所以精细的正则匹配规则往前放, 通用的正则匹配规则往后放.
location 匹配顺序
- “=” 精准匹配,如果匹配成功,则停止其他匹配
- 普通字符串指令匹配,优先级是从长到短(匹配字符越多,则选择该匹配结果)。匹配成功的location如果使用^~,则停止其他匹配(正则匹配)
- 正则表达式指令匹配,按照配置文件里的顺序(从上到下),成功就停止其他匹配,如果正则匹配成功,使用该结果;否则使用普通字符串匹配结果
(location =) > (location 完整路径) > (location ^~ 路径) > (location ,* 正则顺序) > (location 部分起始路径) > (location /)
即:
(精确匹配)> (最长字符串匹配,但完全匹配) >(非正则匹配)>(正则匹配)>(最长字符串匹配,不完全匹配)>(location通配)
location 匹配案例
server {
listen 9876;
location = / {
return 200 "精确匹配/";
}
location ~* /ma.*ch {
return 200 "正则匹配/ma.*ch";
}
location ~ /mat.*ch {
return 200 "正则匹配/match.*";
}
location = /test {
return 200 "精确匹配/test";
}
location ^~ /test/ {
return 200 "前缀匹配/test";
}
location /test/hello/world {
return 200 "完全匹配/test/hello/world";
}
location /test/hello {
return 200 "部分匹配/test/hello";
}
location ~ /test/he*o {
return 200 "正则匹配/test/he*o";
}
location /document {
return 200 "/document";
}
location ~ /docu* {
return 200 "~/docu";
}
location / {
return 200 "通配/";
}
}
curl localhost:9876/test
精确匹配/test
curl localhost:9876/test/hello/world
完全匹配/test/hello/world
curl localhost:9876/test/
前缀匹配/test
curl localhost:9876/test/hell
前缀匹配/test
curl localhost:9876/test/hello/aaa
部分匹配/test/hello
curl localhost:9876/test/heao
前缀匹配/test
curl localhost:9876/match
正则匹配/ma.*ch
curl localhost:9876/test/hello/world/ss
完全匹配/test/hello/world
curl localhost:9876/document
~/docu
上面例子中最后一个需要好好理解















 2884
2884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









