



 在使用 PyTorch 的 Embedding 层时,遇到`index out of range in self`错误。问题源于输入数据未经词典映射,导致数值超出了有效范围[0, num_embeddings-1]。通过检查张量的最小值和最大值,修正超出范围的数值,可以避免此错误。提供了一个修正后的正确使用embedding层的示例。"
132134546,11389520,Python实现心电信号时域特征分析,"['Python', '开发语言', '数据分析', '生物医学信号处理', '心电图分析']
在使用 PyTorch 的 Embedding 层时,遇到`index out of range in self`错误。问题源于输入数据未经词典映射,导致数值超出了有效范围[0, num_embeddings-1]。通过检查张量的最小值和最大值,修正超出范围的数值,可以避免此错误。提供了一个修正后的正确使用embedding层的示例。"
132134546,11389520,Python实现心电信号时域特征分析,"['Python', '开发语言', '数据分析', '生物医学信号处理', '心电图分析']
使用pytorch时,数据过embedding层时报错:
Traceback (most recent call last):
File "C:/Users/gaosiqi/PycharmProjects/DeepFM/main.py", line 68, in <module>
out = model(train_data)
File "C:\Anaconda3\envs\tensorflow\lib\site-packages\torch\nn\modules\module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "C:/Users/gaosiqi/PycharmProjects/DeepFM/main.py", line 26, in forward
embedding = self.word_embedding(x)
File "C:\Anaconda3\envs\tensorflow\lib\site-packages\torch\nn\modules\module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "C:\Anaconda3\envs\tensorflow\lib\site-packages\torch\nn\modules\sparse.py", line 126, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "C:\Anaconda3\envs\tensorflow\lib\site-packages\torch\nn\functional.py", line 1814, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
原因是输入进embedding层的数据并不是经过词典映射的,而是原始数据,因此张量内部有超出embedding层合法范围的数。
embedding层需检查张量内部具体值的大小,并确保它们的值在有效范围内[0, num_embeddings-1]。例如此次出错就是张量内最大值是30000+,最小是-2,因此这两种过大和过小的值就引起问题。
再例如:
train_data = [[1,-1,1,1,2,2,2,3,4,23,2,3,1,2,2,2],
[4,3,2,5,3,2,8,9,3,66,7,7,4,3,2,3]]
用
print(train_data.max()) #(已转变为张量后)
print(train_data.min())
来检查张量内部的最大最小值
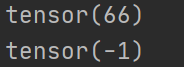
此时会报错:

如果我们将大于num_embeddings和小于0的值都改掉看看:
train_data = [[1,1,1,1,2,2,2,3,4,2,2,3,1,2,2,2],
[4,3,2,5,3,2,8,9,3,6,7,7,4,3,2,3]]
此时就顺利经过了embedding层,并且得到了嵌入层的结果:

正确使用embedding层示例:
from collections import Counter
import torch.nn as nn
# Let's say you have 2 sentences(lowercased, punctuations removed) :
sentences = "i am new to PyTorch i am having fun"
words = sentences.split(' ')
vocab = Counter(words) # create a dictionary
vocab = sorted(vocab, key=vocab.get, reverse=True)
vocab_size = len(vocab)
# map words to unique indices
word2idx = {word: ind for ind, word in enumerate(vocab)}
# word2idx = {'i': 0, 'am': 1, 'new': 2, 'to': 3, 'pytorch': 4, 'having': 5, 'fun': 6}
encoded_sentences = [word2idx[word] for word in words]
# encoded_sentences = [0, 1, 2, 3, 4, 0, 1, 5, 6]
print(encoded_sentences)
# let's say you want embedding dimension to be 3
emb_dim = 3

















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









