







最左前缀法则
若MySQL建立了联合索引,要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列(即条件查询少了某一个联合索引中的字段名),索引将部分失效(后面的字段索引失效)。
在建立联合索引时,即构建一颗B+树,但有多个字段,根据的是联合索引最左侧的字段来构建B+树,如果该字段相同则第二个字段是有序的,所以联合索引的最左侧字段是有序的,如果查询时不包含该列,便无法使用索引
//对stu表中的sex,age,name字段建立联合索引
create index idx_stu_sex_age_name on stu(sex,age,name);
select * from stu where age = 18;#未使用索引
select * from stu where name ='Lee';#未使用索引
select * from stu where sex = 'gender' and age = 18;#使用索引
select * from stu where sex = 'gender' and name ='Lee';#只有sex使用索引
select * from stu where name = 'Lee' and sex = 'gender' and age = 18;#使用索引(与顺序无关)
select * from stu where age = 18 and name = 'Lee';#未使用索引注意:
-
在创建联合索引时,根据业务需求,where子句中使用最频繁的列放在最左侧,以提升效率
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效;
-
可以对索引最左侧的列进行范围查询
create index idx_a_b_c on table(a,b,c);建立联合索引
select * from table where a > 1 and a < 3;使用索引-
如果左边的列是精确查找,那么右边的列可以范围查询
select * from table where a = 1 and b < 3;#使用索引-
只有a使用索引,b不使用。因为1<a<3的范围内b是无序的,无法进行索引
select * from table where 1 < a < 3 and b < 3;#只有a使用到索引注意:
-
.>=或<=右侧的列索引不会失效!所以业务允许的情况下使用>=或<=
-
如果第一个字段是范围查询,那么最好要为其单独建一个索引
索引列运算
不要再索引列上进行运算操作(如函数运算),索引将失效,如
explain select * from tb_user where substring(phone,10,2) = '15';字符串不加引号
字符串类型字段使用时,不加引号,索引将失效
explain select * from tb_user where profession = '软件工程' and age = 31 and status = 0;
此处的0没有加上引号,导致status的索引失效模糊查询
如果仅仅是尾部模糊匹配,索引不会失效;如果头部模糊匹配,索引失效。如
select * from tb_user where profession like '软件%';--->不失效
select * from tb_user where profession like '%工程';--->失效注意:在大数据量的情况下避免模糊查询前面加%的情况,否则为全表扫描,效率低
or连接的条件
用or分割开的条件,如果or前面的条件有索引,而or后面的列中没有索引,则整个索引都失效。如
explain select * from tb_user where id = 1 or age = 23;-->失效
explain select * from tb_user where phone = '110' or age = 23;-->失效由于age没有索引,即使id和phone有索引也会失效
解决办法:对age也加上索引
create index idx_user_age on tb_user(age);数据分布影响
如果MySQL评估使用索引比全表扫描更慢,则不使用索引
SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为提示来达到优化操作的目的
use index(索引名)(给建议,接不接受取决于mysql)
explain select * from tb_user use index(idx_user_pro) where profession = "软件工程";ignore index(索引名)(忽略指定的索引)
explain select * from tb_user ignore index(id_user_pro) where profession = '软件工程';force index(索引名)(强制使用指定索引)
explain select * from tb_user force index(id_user_pro) where profession = '软件工程';覆盖索引(重要)
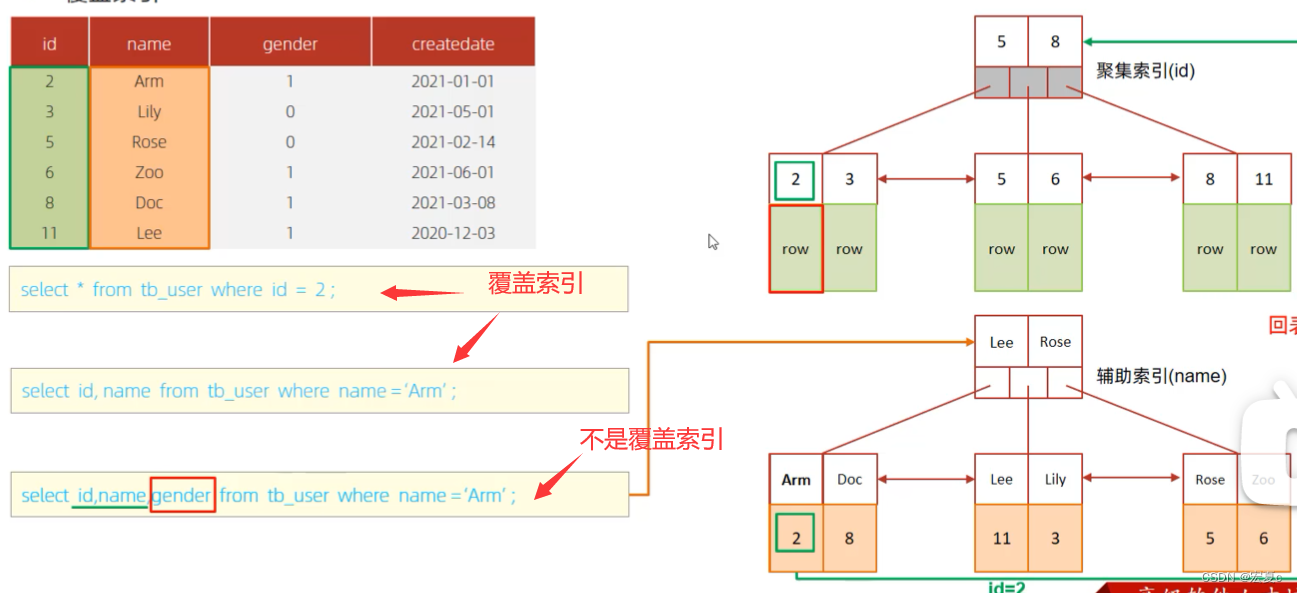
查询所需要的列在索引中能够全部覆盖到,无需回表查询
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能找到),避免了回表查询,减少select *。(研究的是select返回的字段)
explain命令中的extra字段有如下内容:

思考:为什么避免select * ?
答:因为容易出现回表查询,而不是覆盖索引。除非对所有字段都创建了联合索引
前缀索引
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串或大文本字段,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率
语法:
create index idx_xxx on table_name(column(n));-
前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的
#选择性
select count(distinct email)/count(*) from emp;
select count(distinc substring(email,1,5))/count(*) from emp;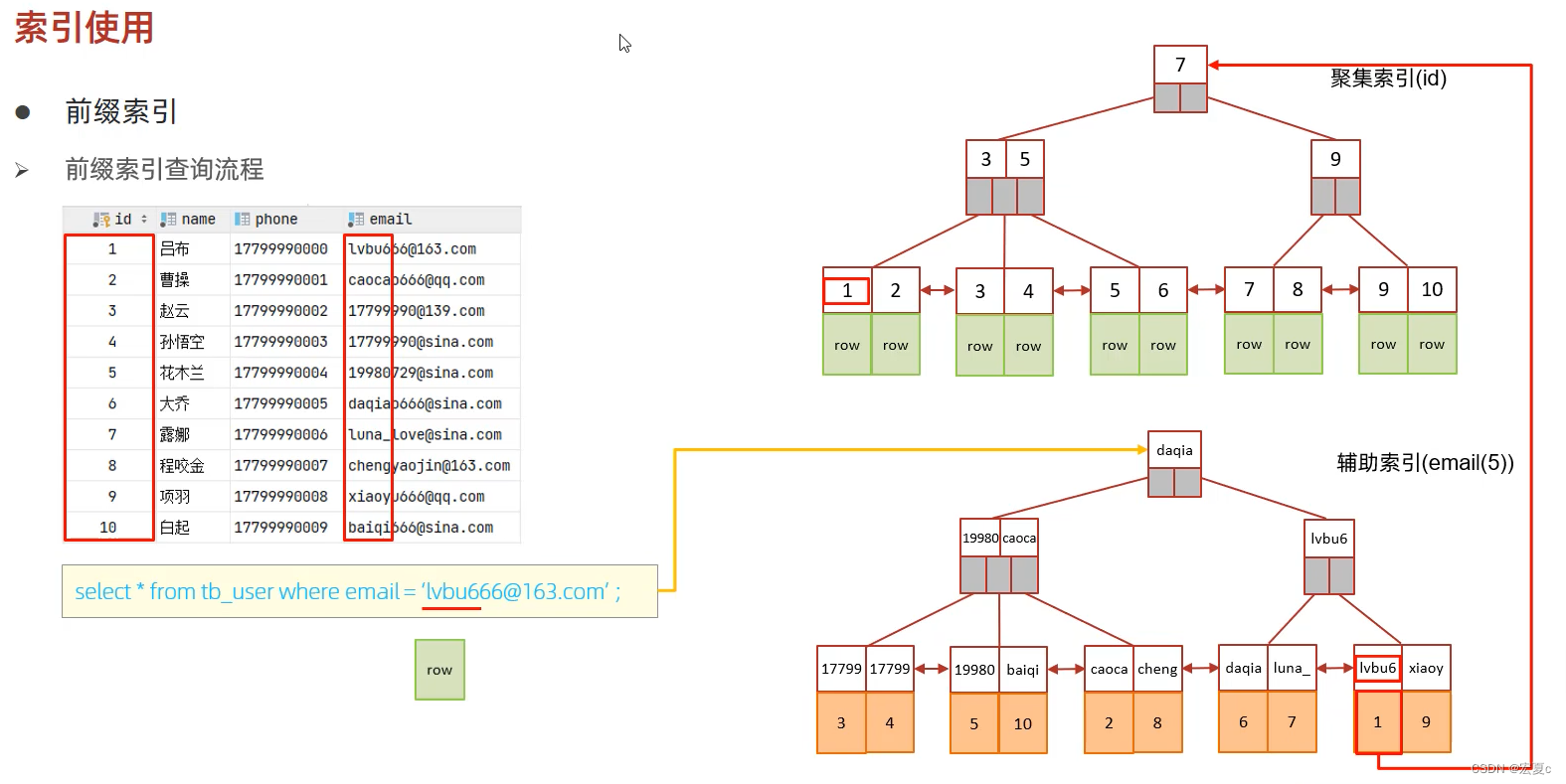
单列索引与联合索引
单列索引:即一个索引只包含单个列
联合索引:即一个索引包含了多个列
多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询
注意:
-
在业务场景中,如果存在多个查询条件,考虑针对查询字段建立索引时,建议建立联合索引,而非单列索引
-
建立联合索引时,考虑字段的顺序,即查询最频繁的放最左侧
索引设计原则
-
【表】针对于数据量较大(如一百万而非几千条),且查询比较频繁的表建立索引
-
【字段】针对常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
-
尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。(区分度高如:手机号,身份证号;区分度不高如:姓氏,状态字段)
-
如果时字符串类型的字段,且字段的长度较长,可以针对于字段的特点,建立前缀索引
-
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
-
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率
-
如果索引列不能存储null值,请在创建表时使用not null约束它。当优化器知道每列是否包含null值时,它可以更好地确定哪个索引最有效地用于查询
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









