







这篇博客记录刷题第12天的解题过程与学习所得。
146. LRU 缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。
实现 LRUCache 类:
- LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
输入 [“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”,
“get”, “get”] [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1],
[3], [4]]
输出 [null, null, null, 1, null, -1, null, -1, 3, 4]解释
LRUCache lRUCache = new LRUCache(2); lRUCache.put(1, 1); // 缓存是{1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2} lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到) lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到) lRUCache.get(3); 返回 3
lRUCache.get(4); // 返回 4提示:
- 1 <= capacity <= 3000
- 0 <= key <= 3000
- 0 <= value <= 104
- 最多调用 3 * 104 次 get 和 put
这题非常难,我好不容易才看懂题解,以下分析和代码也都全摘自题解区[1]。
LRU的思路:删除最久未被使用的数据,核心是:快速查找+数据存储的有序性
- 快速查找 O ( 1 ) O(1) O(1) 完成,那么立即就要想到哈希表;
- 因为哈希表是无序的,所以为了保证数据的有序性,可以借助链表来实现,插入、删除可以在常数时间 O ( 1 ) O(1) O(1) 内完成;
- 链表的表尾为最久未被使用数据,头部为最近使用数据。所以插入数据若key不存在则直接插在链表头部,存在则更新val后移到表头,删除数据则直接删除表尾数据。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
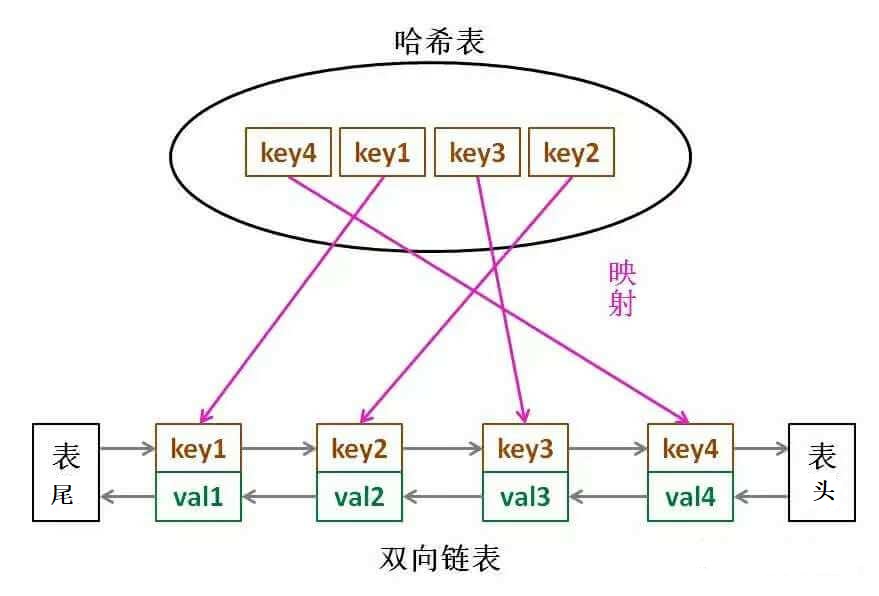
思想很简单,就是借助哈希表赋予了链表快速查找的特性嘛:可以快速查找某个 key 是否存在缓存(链表)中,同时可以快速删除、添加节点。
-
get方法访问缓存中的数据,并把当前访问的数据(key, val) 提到表头(最近使用标记);
-
put方法插入新的元素对;
- 如果已存在key, 则更新对应的val并移到表头;
- 若链表未满,则直接插入新数据到表头;
- 若链表已满,则删除表尾数据(最久未被使用);
struct DLinkedNode { //双向链表(插入、删除O(1))+ 哈希表(查找O(1))
int key, value;
DLinkedNode* prev;
DLinkedNode* next;
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private: //成员变量
unordered_map<int, DLinkedNode*> cache; //哈希表对节点的映射
DLinkedNode* head;
DLinkedNode* tail;
int size;
int capacity;
public:
LRUCache(int _capacity): capacity(_capacity), size(0) { //类初始化
// 使用伪头部和伪尾部节点,避免检查相邻的节点是否存在。
head = new DLinkedNode();
tail = new DLinkedNode();
head->next = tail; //向右是next
tail->prev = head; //向左是pre
}
int get(int key) {
if (!cache.count(key)) { //key 不存在
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到双向链表头部
DLinkedNode* node = cache[key];
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (cache.count(key)){
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到双向链表头部
DLinkedNode* node = cache[key];
node->value = value;
moveToHead(node);
} else {
// 如果 key 不存在,创建一个新的节点
DLinkedNode* node = new DLinkedNode(key, value);
// 添加进哈希表,cache中新建 key 对新节点 node 的映射;
cache[key] = node;
// 添加至双向链表的头部
addToHead(node);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode* removed = removeTail();
// 删除哈希表中对应的项
cache.erase(removed->key);
// 防止内存泄漏
delete removed;
--size;
}
}
}
void addToHead(DLinkedNode* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
void removeNode(DLinkedNode* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void moveToHead(DLinkedNode* node) {
removeNode(node);
addToHead(node);
}
DLinkedNode* removeTail() {
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}
};
- 为什么必须要用双向链表?
因为我们需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前节点的指针,而双向链表才能支持直接查找前节点,保证操作的时间复杂度 O ( 1 ) O(1) O(1); - 哈希表中已经存储key为什么要在链表中仍要同时存储 key 和 val,而不是只存储 val?
(1) 首先创建节点时需添加进哈希表,map中需创建key对新节点的映射:
DLinkedNode* node = new DLinkedNode(key, value);
cache[key] = node;
(2) 当缓存容量已满,我们不仅仅要删除表尾节点,还要把 map 中映射到该节点的 key 同时删除,而这个 key 只能由 node 得到。如果 node 结构中只存储 val,那么我们就无法得知 key 是什么,就无法删除 map 中的键,造成错误。
DLinkedNode* removed = removeTail();
cache.erase(removed->key);
148.排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
进阶:
- 你可以在 O(n log n) 时间复杂度和常数级 O ( 1 ) O(1) O(1) 空间复杂度下,对链表进行排序吗?
示例 1:
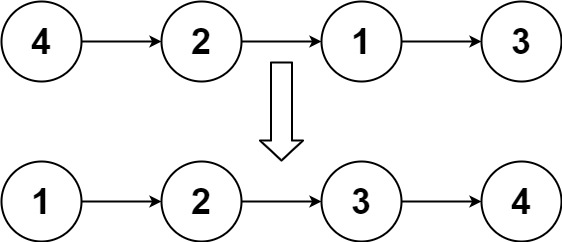
输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
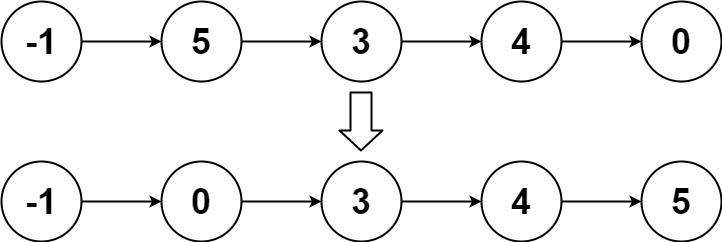
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目在范围 [0, 5 * 1 0 4 10^4 104] 内
- - 1 0 5 10^5 105 <= Node.val <= 1 0 5 10^5 105
直接引用官方题解[2],分析如下:时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn) 的排序算法包括归并排序、堆排序和快速排序(快速排序的最差时间复杂度是 O ( n 2 ) O(n^2) O(n2),其中最适合链表的排序算法是归并排序。
归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是 O ( l o g n ) O(log n) O(logn)。如果要达到 O ( 1 ) O(1) O(1) 的空间复杂度,则需要使用自底向上的实现方式。
方法一:自顶向下归并排序
对链表自顶向下归并排序的过程如下。
-
找到链表的中点,以中点为分界,将链表拆分成两个子链表。寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2 步,慢指针每次移动 1 步,当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点。
-
对两个子链表分别排序。
-
将两个排序后的子链表合并,得到完整的排序后的链表。可以使用「21. 合并两个有序链表」的做法,将两个有序的子链表进行合并。
上述过程可以通过递归实现。递归的终止条件是链表的节点个数小于或等于 1,即当链表为空或者链表只包含 [1] 个节点时,不需要对链表进行拆分和排序。
class Solution {
public:
ListNode* sortList(ListNode* head) {
return sortList(head, nullptr);
}
ListNode* sortList(ListNode* head, ListNode* tail) { //拆分排序合并,递归调用
if (head == nullptr) {
return head;
}
if (head->next == tail) {
head->next = nullptr;
return head;
}
ListNode* slow = head, *fast = head; //快慢指针找链表中点
while (fast != slow) {
slow = slow -> next;
fast = fast -> next;
if (fast != slow) fast = fast -> next;
}
ListNode* mid = slow;
return merge(sortList(head, mid), sortList(mid, tail))
}
ListNode* merge(ListNode* head1, ListNode* head2) { //合并两有序链表
ListNode* dummyHead = new ListNode(0);
ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2;
while (temp != nullptr && temp2 != nullptr) {
if (temp1->val <= temp2->val) {
temp->next = temp1;
temp1 = temp1->next;
} else {
temp->next = temp2;
temp2 = temp2->next;
}
}
if (temp1 != nullptr) {
temp->next = temp1
} else if (temp2 != nullptr) {
temp->next = temp2;
}
return dummyHead->next;
}
};
方法二:自底向上归并排序
使用自底向上的方法实现归并排序,则可以达到 O ( 1 ) O(1) O(1) 的空间复杂度。
首先求得链表的长度 length,然后将链表拆分成子链表进行合并。
具体做法如下。
1. 用 subLength 表示每次需要排序的子链表的长度,初始时
s
u
b
L
e
n
g
t
h
=
1
subLength=1
subLength=1。
2. 每次将链表拆分成若干个长度为 subLength 的子链表(最后一个子链表的长度可以小于 subLength ),按照每两个子链表一组进行合并,合并后即可得到若干个长度为
s
u
b
L
e
n
g
t
h
×
2
subLength×2
subLength×2 的有序子链表(最后一个子链表的长度可以小于
s
u
b
L
e
n
g
t
h
×
2
subLength×2
subLength×2 )。合并两个子链表仍然使用「21. 合并两个有序链表」的做法。
3. 将 subLength 的值加倍,重复第 2 步,对更长的有序子链表进行合并操作,直到有序子链表的长度大于或等于 length,整个链表排序完毕。
如何保证每次合并之后得到的子链表都是有序的呢?可以通过数学归纳法证明。
1. 初始时
s
u
b
L
e
n
g
t
h
=
1
subLength=1
subLength=1 ,每个长度为 1 的子链表都是有序的。
2. 如果每个长度为subLength 子链表已经有序,合并两个长度为 subLength 的有序子链表,得到长度为
s
u
b
L
e
n
g
t
h
×
2
subLength×2
subLength×2 的子链表,一定也是有序的。
3. 当最后一个子链表的长度小于 subLength 时,该子链表也是有序的,合并两个有序子链表之后得到的子链表一定也是有序的。
因此可以保证最后得到的链表是有序的。
class Solution {
public:
ListNode* sortList(ListNode* head) {
if (head == nullptr) {
return head;
}
int length = 0;
ListNode* node = head;
while (node != nullptr) {
length++;
node = node->next;
}
ListNode* dummyHead = new ListNode(0, head);
for (int subLength = 1; subLength < length; subLength <<= 1) {
ListNode* prev = dummyHead, *curr = dummyHead->next;
while (curr != nullptr) {
ListNode* head1 = curr;
for (int i = 1; i < subLength && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* head2 = curr->next;
curr->next = nullptr;
curr = head2;
for (int i = 1; i < subLength && curr != nullptr && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* next = nullptr;
if (curr != nullptr) {
next = curr->next;
curr->next = nullptr;
}
ListNode* merged = merge(head1, head2);
prev->next = merged;
while (prev->next != nullptr) {
prev = prev->next;
}
curr = next;
}
}
return dummyHead->next;
}
ListNode* merge(ListNode* head1, ListNode* head2) {
ListNode* dummyHead = new ListNode(0);
ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2;
while (temp1 != nullptr && temp2 != nullptr) {
if (temp1->val <= temp2->val) {
temp->next = temp1;
temp1 = temp1->next;
} else {
temp->next = temp2;
temp2 = temp2->next;
}
temp = temp->next;
}
if (temp1 != nullptr) {
temp->next = temp1;
} else if (temp2 != nullptr) {
temp->next = temp2;
}
return dummyHead->next;
}
};
155. 最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
- push(x) —— 将元素 x 推入栈中。
- pop() —— 删除栈顶的元素。
- top() —— 获取栈顶元素。
- getMin() —— 检索栈中的最小元素。
示例:
输入:
[“MinStack”,“push”,“push”,“push”,“getMin”,“pop”,“top”,“getMin”]
[[],[-2],[0],[-3],[],[],[],[]]输出:
[null,null,null,null,-3,null,0,-2]解释:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.提示:
- pop、top 和 getMin 操作总是在 非空栈 上调用。
参考
[1]https://leetcode-cn.com/problems/lru-cache/solution/cpp-unorder_maplist-jie-jue-by-zhangm365-tj57/
[2]https://leetcode-cn.com/problems/sort-list/solution/pai-xu-lian-biao-by-leetcode-solution/















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









