







核心概念
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数
拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
绑定表
分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分
片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联
查询效率将大大提升。
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。
适用于数据量不大且需要与海量数据的表进行关联查询的场景。字典表就是典型的场景。
Quick start
1. pom依赖引入
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${version}</version>
<scope>compile</scope>
</dependency>
2. spring-boot使用
spring:
shardingsphere:
enabled: true
datasource:
#数据源名称 不配置的话不会创建数据源
#这里有个坑(使用下划线可能会有异常产生,字符不支持,如:m_0)
names: m1,m2
#数据源 m1配置
m1:
#数据库方言
driver-class-name: com.mysql.cj.jdbc.Driver
#数据库密码
password: 1a!gHco@d2mrgf^*^4lwGpB^
#数据源类型
type: com.zaxxer.hikari.HikariDataSource
#数据源地址
jdbcUrl: jdbc:mysql://rm-wz9gtu4pe3f6vom022o.mysql.rds.aliyuncs.com:3306/ideamake_um?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
#数据源用户名
username: ideamake_dbuser
#数据源 m1配置
m2:
driver-class-name: com.mysql.cj.jdbc.Driver
password: 1a!gHco@d2mrgf^*^4lwGpB^
type: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://rm-wz9gtu4pe3f6vom022o.mysql.rds.aliyuncs.com:3306/ideamake_um?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
username: ideamake_dbuser
#属性配置 是否打印sql
props:
sql:
show: true
#分片键配置
sharding:
tables:
#分片键表名称
um_agent_info:
#数据源分片算法 只能有一个分片算法
database-strategy:
hint:
#自定义分片算法类位置
algorithmClassName: cn.ideamake.cloud.um.HintTestSharding
#数据节点配置
actual-data-nodes: m$->{1..2}.um_agent_info_$->{0..1}
#表分片算法 只能有一个分片算法
table-strategy:
standard:
#自定义分片算法类位置
precise-algorithm-class-name: cn.ideamake.cloud.um.TestSharding
#根据那个列来分片
sharding-column: is_authentication
多库不配置数据源分配算法则每个库都会查询一次
属性配置项说明
| 名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
| sql-show (?) | boolean | 是否在日志中打印 SQL打印 SQL 可以帮助开发者快速定位系统问题。日志内容包含:逻辑 SQL,真实 SQL 和 SQL 解析结果。如果开启配置,日志将使用 Topic ShardingSphere-SQL,日志级别是 INFO | FALSE |
| sql-simple (?) | boolean | 是否在日志中打印简单风格的 SQL | FALSE |
| kernel-executor-size (?) | int | 用于设置任务处理线程池的大小每个 ShardingSphereDataSource 使用一个独立的线程池,同一个 JVM 的不同数据源不共享线程池 | infinite |
| max-connections-size-per-query (?) | int | 一次查询请求在每个数据库实例中所能使用的最大连接数 | 1 |
| check-table-metadata-enabled (?) | boolean | 在程序启动和更新时,是否检查分片元数据的结构一致性 | FALSE |
| check-duplicate-table-enabled (?) | boolean | 在程序启动和更新时,是否检查重复表 | FALSE |
| sql-federation-enabled (?) | boolean | 是否开启联邦查询 | FALSE |
常用的分片方式
inline表达式分片
sharding:
#默认分库策略
default-database-strategy:
inline:
sharding-column: is_authentication
#根据 Groovy 做的语句解析 m为库名
algorithm-expression: m$->{is_authentication % 2 + 1}
tables:
um_agent_info:
database-strategy:
inline:
sharding-column: is_authentication
#根据 Groovy 做的语句解析
algorithm-expression: m$->{is_authentication % 2 + 1}
actual-data-nodes: m$->{1..2}.um_agent_info_$->{0..1}
table-strategy:
inline:
#根据 Groovy 做的语句解析
algorithm-expression: um_agent_info_$->{is_authentication % 2}
sharding-column: is_authentication
standard方式分片
sharding:
tables:
um_agent_info:
database-strategy:
inline:
sharding-column: is_authentication
algorithm-expression: m$->{is_authentication % 2 + 1}
# hint:
# algorithmClassName: cn.ideamake.cloud.um.HintTestSharding
actual-data-nodes: m$->{1..2}.um_agent_info_$->{0..1}
table-strategy:
standard:
#范围分片算法
range-algorithm-class-name: cn.ideamake.cloud.um.TestRangeShardingAlgorithm
#自定义分片算法类位置
precise-algorithm-class-name: cn.ideamake.cloud.um.TestSharding
#根据那个列来分片
sharding-column: is_authentication
TestRangeShardingAlgorithm
范围分片
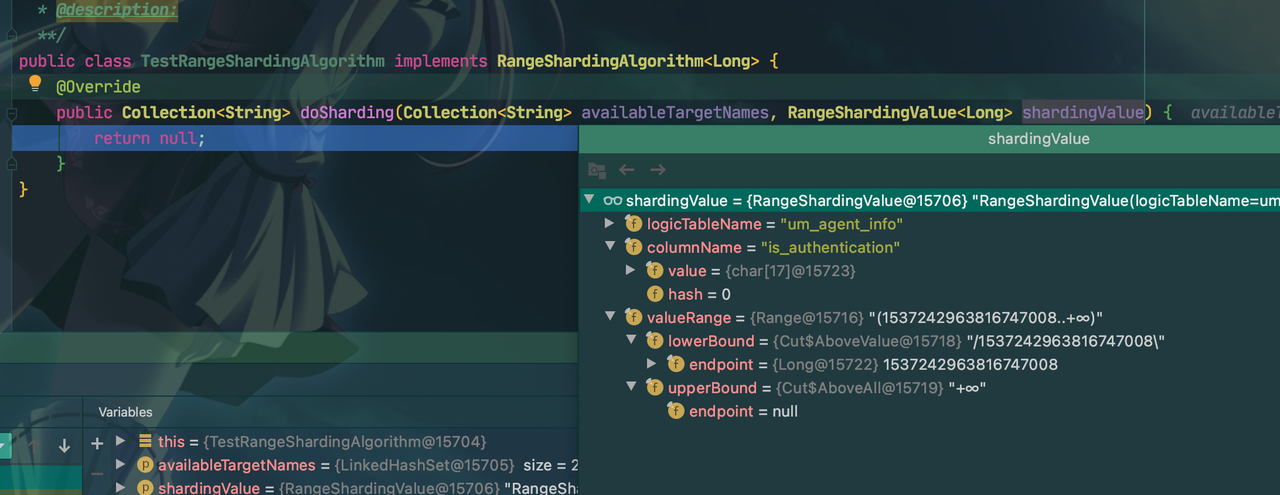
public class TestRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
return null;
}
}
TestSharding:
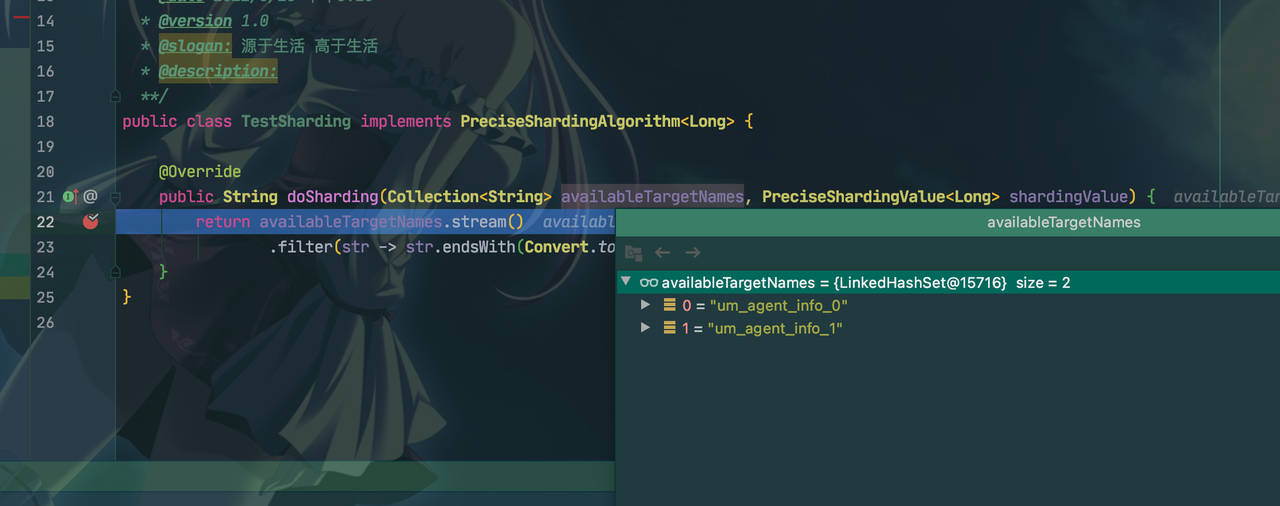
public class TestSharding implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
return availableTargetNames.stream()
.filter(str -> str.endsWith(Convert.toStr(shardingValue.getValue() % 2))).findFirst().orElse("");
}
}
hint方式分片
sharding:
tables:
um_agent_info:
database-strategy:
# inline:
# sharding-column: is_authentication
# algorithm-expression: m$->{is_authentication % 2 + 1}
hint:
algorithmClassName: cn.ideamake.cloud.um.HintTestSharding
actual-data-nodes: m$->{1..2}.um_agent_info_$->{0..1}
table-strategy:
standard:
#自定义分片算法类位置
precise-algorithm-class-name: cn.ideamake.cloud.um.TestSharding
#根据那个列来分片
sharding-column: is_authentication
配置HintManager
HintManager hintManager = HintManager.getInstance();
hintManager.addDatabaseShardingValue("um_agent_info","m1");
hintManager.addTableShardingValue("um_agent_info","m1");
IPage<AgentInfo> page = agentInfoService.page(new IdeamakePage<>(1, 10));
hintManager.close();
HintTestSharding
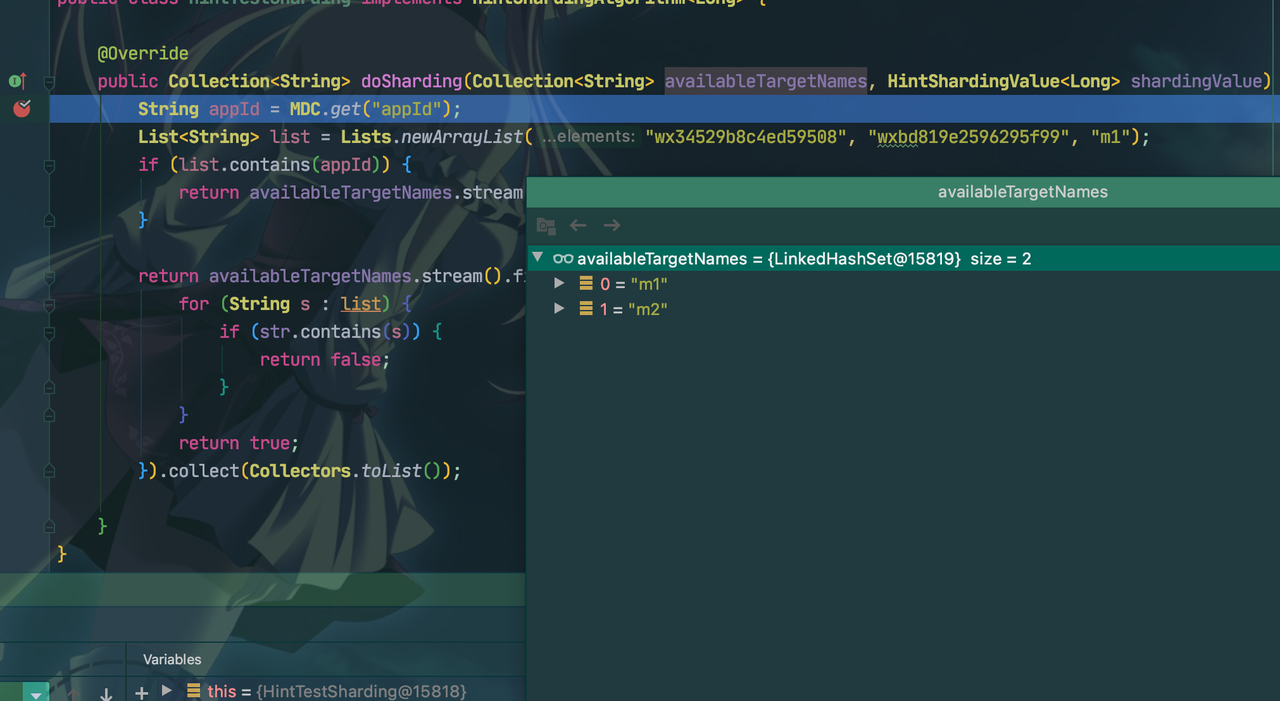
public class HintTestSharding implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Long> shardingValue) {
String appId = MDC.get("appId");
List<String> list = Lists.newArrayList("wx34529b8c4ed59508", "wxbd819e2596295f99", "m1");
if (list.contains(appId)) {
return availableTargetNames.stream().filter(str -> str.contains(appId)).collect(Collectors.toList());
}
return availableTargetNames.stream().filter(str -> {
for (String s : list) {
if (str.contains(s)) {
return false;
}
}
return true;
}).collect(Collectors.toList());
}
}
complex方式分片
sharding:
tables:
um_agent_info:
database-strategy:
# inline:
# sharding-column: is_authentication
# algorithm-expression: m$->{is_authentication % 2 + 1}
hint:
algorithmClassName: cn.ideamake.cloud.um.HintTestSharding
actual-data-nodes: m$->{1..2}.um_agent_info_$->{0..1}
table-strategy:
complex:
#分片键 多个“,”隔开
shardingColumns: is_authentication,open_id
algorithmClassName: cn.ideamake.cloud.um.TestComplexKeysShardingAlgorithm
TestComplexKeysShardingAlgorithm
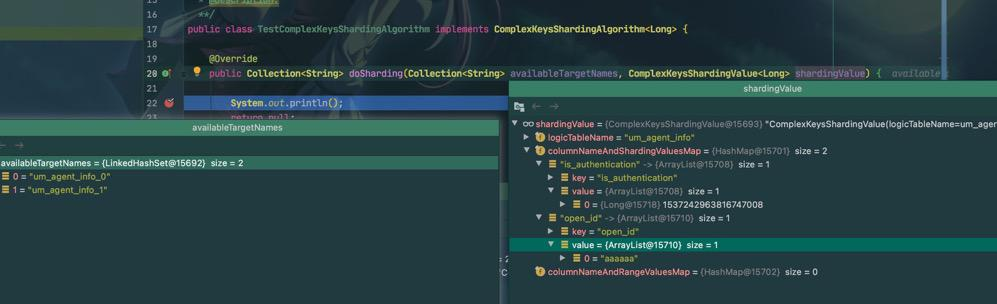
public class TestComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
System.out.println();
return null;
}
}
内置分片算法:
https://shardingsphere.apache.org/document/5.1.1/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/
常见坑
LocalDateTime转换问题

可以跟源码看一下,Shareding-jdbc 并没有支持

直接抛出异常的。
默认的转换器 LocalDateTimeTypeHandler 调用的就是 getObject返回泛型的方法
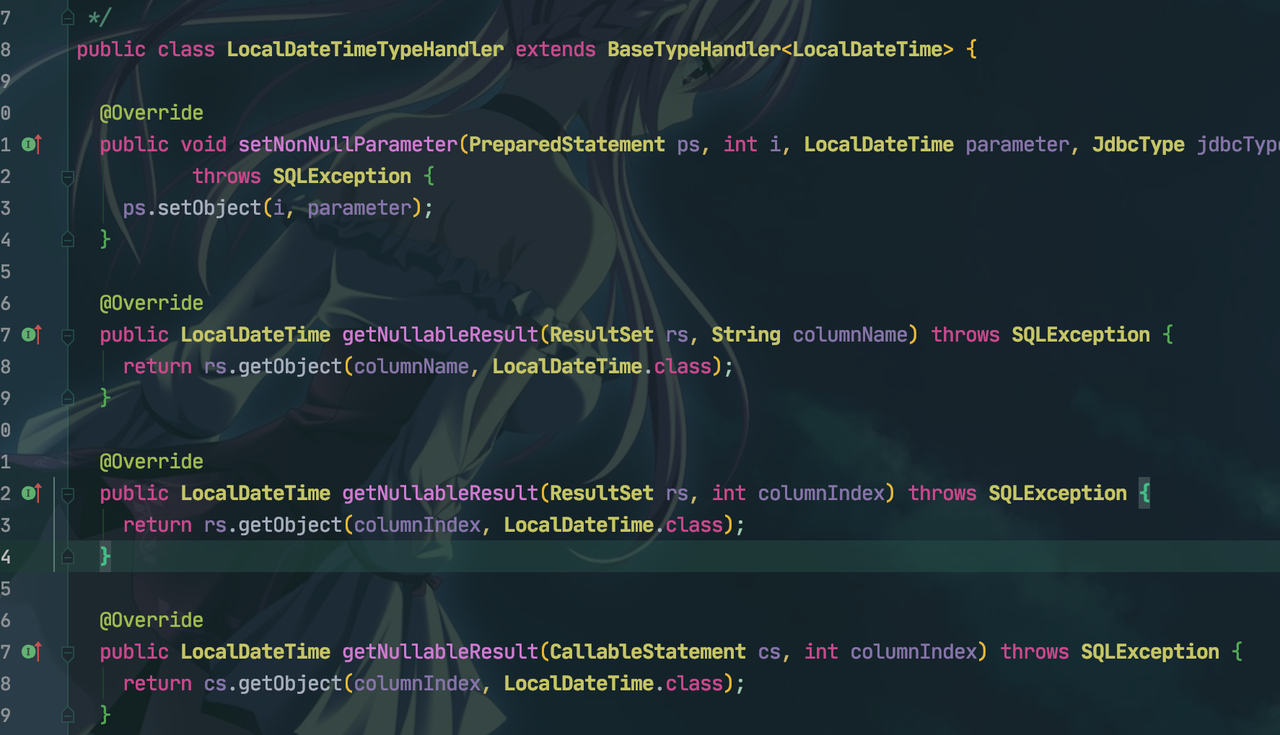
两种方案解决
一: 自己修改源码,但是后面sharding-jdbc 升级了想要扩展就比较麻烦,代码需要迁移
二:继承BaseTypeHandler 重写里面方法
数据源名称带下划线
使用下划线可能会有异常产生,字符不支持,如:m_0















 1445
1445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









