









Six Basic Cache Optimizations
普通内存访问时间公式给了我们一个框架,来提高缓存优化以提高缓存性能,因此,我们将六种缓存优化分为三类:
■ 降低未命中率——更大的块大小、更大的缓存大小和更高的关联性
■ 减少未命中惩罚——多级缓存并给予读优先于写
■ 减少命中缓存的时间——在索引缓存时避免地址转换B-40 页上的图 B.18 总结了这六种技术的实现复杂性和性能优势。

改进缓存行为的经典方法是降低未命中率,我们提出了三种技术来做到这一点。 为了更好地了解失误的原因,我们首先从一个模型开始,该模型将所有失误分为三个简单的类别:
■ 强制——对块的第一次访问不能在高速缓存中,因此必须将该块带入高速缓存。 这些也称为冷启动未命中或首次引用未命中。
■ 容量——如果高速缓存不能包含程序执行期间所需的所有块,由于块被丢弃并随后被检索,将发生容量缺失(除了强制缺失)。
■ 冲突——如果块放置策略设置为关联或直接映射,则会发生冲突未命中(除了强制和容量未命中之外),因为如果有太多块映射到其集合,则块可能会被丢弃并随后被检索。
这些未命中也称为碰撞未命中。 这个想法是,完全关联缓存中的命中在 n 路集合关联缓存中变为未命中是由于某些流行集合上的请求超过 n 次。
(第 5 章添加了第四个 C,用于由于缓存刷新导致的一致性缺失,以保持多处理器中多个缓存的一致性;我们不会在这里考虑这些。)
图 B.8 显示了缓存未命中的相对频率,按三个 C 细分。 强制未命中是发生在无限高速缓存中的那些。 容量未命中是在完全关联的缓存中发生的那些。 冲突未命中是从完全关联到八向关联、四向关联等发生的那些。 图 B.9 以图形方式显示了相同的数据。 上图显示绝对未命中率; 底部图表按未命中类型绘制了所有未命中百分比作为缓存大小的函数。

为了显示关联性的好处,冲突未命中被划分为由每次关联性降低引起的未命中。 以下是冲突未命中的四个部分及其计算方法:
■ 八路——由于从完全关联(无冲突)到八路关联而导致的冲突未命中
■ 四路——由于从八路关联到四路关联而导致的冲突未命中
■ 双向——由于从四向关联变为双向关联而导致的冲突未命中
■ 单向——由于从双向关联到单向关联(直接映射)而导致的冲突未命中从图中我们可以看出,SPEC2000 程序的强制未命中率非常小,就像许多长时间运行的程序一样。
确定了三个 C 之后,计算机设计师可以对它们做些什么呢?从概念上讲,冲突是最简单的:完全关联的放置避免了所有冲突未命中。 但是,完全关联在硬件中很昂贵,并且可能会降低处理器时钟速率(请参见第 B-29 页上的示例),从而导致整体性能降低。
除了扩大缓存之外,几乎没有什么可做的容量。 如果上层内存比程序所需的内存小得多,并且很大一部分时间用于在层次结构中的两个级别之间移动数据,则可以说内存层次结构颠簸。 由于需要进行如此多的替换,抖动意味着计算机的运行速度接近于较低级别内存的速度,或者由于未命中开销而可能更慢。
改进三个 C 的另一种方法是使块更大以减少强制未命中的数量,但是,正如我们很快将看到的,大块会增加其他类型的未命中。
三个 C 可以深入了解未命中的原因,但这个简单的模型有其局限性; 它可以让您深入了解平均行为,但可能无法解释个别失误。 例如,更改缓存大小会更改冲突未命中和容量未命中,因为更大的缓存会将引用分散到更多块。 因此,随着缓存大小的变化,未命中可能会从容量未命中转变为冲突未命中。 类似地,改变块大小有时可以减少容量缺失(除了预期的强制缺失减少),如 Gupta 等人。 (2013) 显示。
还要注意,三个 C 也忽略了替换策略,因为它很难建模,而且一般来说它不太重要。 在特定情况下,替换策略实际上会导致异常行为,例如较大关联性的错误率较低,这与三个 C 的模型相矛盾。 (有些人建议使用地址跟踪来确定内存中的最佳位置,以避免三个 C 模型中的位置错误;我们在这里没有遵循该建议。)
唉,许多降低未命中率的技术也会增加命中时间或未命中惩罚。 使用三种优化来降低未命中率的愿望必须与使整个系统快速的目标相平衡。 第一个例子显示了平衡视角的重要性。
First Optimization: Larger Block Size to Reduce Miss Rate
降低未命中率的最简单方法是增加块大小。 图 B.10 显示了一组程序和缓存大小的块大小与未命中率的权衡。 更大的块大小也将减少强制未命中。 这种减少的发生是因为局部性原则有两个组成部分:时间局部性和空间局部性。 较大的块利用空间局部性。
同时,较大的块会增加未命中惩罚。 因为它们减少了缓存中的块数,如果缓存很小,较大的块可能会增加冲突未命中甚至容量未命中。 显然,几乎没有理由将块大小增加到会增加未命中率的大小。 如果增加平均内存访问时间,那么降低未命中率也没有任何好处。 未命中惩罚的增加可能超过未命中率的降低。



与所有这些技术一样,缓存设计者试图将未命中率和未命中惩罚都降至最低。 块大小的选择取决于底层内存的延迟和带宽。 高延迟和高带宽鼓励大块尺寸,因为缓存每次未命中获得更多字节,而未命中惩罚的小幅增加。 相反,低延迟和低带宽鼓励较小的块大小,因为从较大的块中节省的时间很少。 例如,一个小块两倍的未命中惩罚可能接近于一个两倍大小的块的惩罚。 大量的小块也可以减少冲突失误。 请注意,图 B.10 和 B.12 显示了基于最小化未命中率选择块大小与最小化平均内存访问时间之间的差异。
在看到较大块大小对强制和容量未命中的正面和负面影响后,接下来的两个小节将着眼于更高容量和更高关联性的潜力。(块大,强制未命中率小;但是在缓存比较小的情况下,块大,容量未命中率和冲突未命中率大。)(高带宽高延迟,用大块;低延迟低贷款,用小块。)
Second Optimization: Larger Caches to Reduce Miss Rate
在图 B.8 和 B.9 中减少容量未命中的明显方法是增加缓存的容量。 明显的缺点可能是更长的命中时间以及更高的成本和功率。 这种技术在片外高速缓存中特别流行。
Third Optimization: Higher Associativity to Reduce Miss Rate
图 B.8 和 B.9 显示了缺失率如何随着关联性的提高而提高。 从这些数字中可以得出两个一般的经验法则。 第一个是八路组关联实际上在减少这些大小缓存的未命中方面与完全关联一样有效。 通过将八路条目与图 B.8 中的容量未命中列进行比较,您可以看到差异,因为容量未命中是使用完全关联的缓存计算的。
第二个观察结果称为 2:1 缓存经验法则,即大小为 N 的直接映射缓存与大小为 N/2 的双向组关联缓存具有大致相同的未命中率。 对于小于 128 KiB 的缓存大小,这在三个 C 的数字中保持不变。
像许多这样的例子一样,改善平均内存访问时间的一个方面是以牺牲另一个方面为代价的。 增加块大小会降低未命中率,同时增加未命中惩罚,更大的关联性可能以增加命中时间为代价。 因此,快速处理器时钟周期的压力鼓励了简单的缓存设计,但增加的未命中惩罚会奖励关联性,如以下示例所示。


Fourth Optimization: Multilevel Caches to Reduce Miss Penalty
减少缓存未命中一直是缓存研究的传统重点,但缓存性能公式向我们保证,未命中惩罚的改进与未命中率的改进一样有益。 此外,第 80 页的图 2.2 显示,技术趋势使处理器的速度比 DRAM 更快,从而导致未命中惩罚的相对成本随着时间的推移而增加。
处理器和内存之间的这种性能差距导致架构师提出这个问题:我应该让缓存更快以跟上处理器的速度,还是让缓存更大以克服处理器和主内存之间不断扩大的差距?
一个答案是,两者都做。 在原始缓存和内存之间添加另一级缓存可以简化决策。 一级缓存可以足够小以匹配快速处理器的时钟周期时间。 然而,二级缓存可以足够大以捕获许多将进入主存储器的访问,从而减少有效的未命中惩罚。
尽管在层次结构中添加另一个级别的概念很简单,但它会使性能分析复杂化。 二级缓存的定义并不总是直截了当的。 让我们从两级缓存的平均内存访问时间的定义开始。 使用下标L1和L2分别指代一级缓存和二级缓存,原公式为

在这个公式中,二级未命中率是根据一级缓存的剩余部分来衡量的。 为避免歧义,这里对两级缓存系统采用以下术语:
■ 本地未命中率——该比率只是缓存中的未命中数除以对该缓存的内存访问总数。 如您所料,对于一级缓存,它等于 Miss rateL1,对于二级缓存,它等于 Miss rateL2。
■ 全局未命中率——缓存中的未命中数除以处理器生成的内存访问总数。 使用上面的术语,一级缓存的全局未命中率仍然只是 Miss rateL1,但对于二级缓存,它是 Miss rateL1*Miss rateL2。
对于二级缓存,这种本地未命中率很大,因为一级缓存略去了内存访问的精华。 这就是为什么全局未命中率是更有用的衡量标准:它表明离开处理器的内存访问有多少一直访问到内存。
这是每条指令未命中指标的亮点。 我们不会混淆本地或全局未命中率,而是扩展每条指令的内存停顿以增加二级缓存的影响。


请注意,这些公式适用于组合读取和写入,假设是写回一级缓存。 显然,直写一级缓存会将所有写入发送到二级缓存,而不仅仅是未命中,并且可能会使用写缓冲区。


图 B.14 和 B.15 显示了一种设计的未命中率和相对执行时间如何随着二级缓存的大小而变化。 从这些数字中,我们可以得到两个见解。 第一个是全局缓存未命中率与二级缓存的单个缓存未命中率非常相似,前提是二级缓存远大于一级缓存。 因此,我们对一级缓存的直觉和知识适用。 第二个见解是本地缓存未命中率不是衡量二级缓存的好方法; 它是一级缓存未命中率的函数,因此可以通过更改一级缓存而有所不同。 因此,在评估二级缓存时应使用全局缓存未命中率。
有了这些定义,我们就可以考虑二级缓存的参数了。 两个级别最重要的区别是一级缓存的速度影响处理器的时钟频率,而二级缓存的速度只影响一级缓存的未命中惩罚。 因此,我们可以考虑二级缓存中的许多替代方案,这些替代方案会被错误地用于一级缓存。 二级缓存的设计主要有两个问题:会不会降低CPI的平均内存访问时间部分,成本是多少?
最初的决定是二级缓存的大小。 由于一级缓存中的所有内容都可能在二级缓存中,因此二级缓存应该比一级缓存大得多。 如果二级缓存稍微大一点,本地未命中率就会很高。 这一观察激发了巨大的二级缓存的设计——旧计算机中主内存的大小!
一个问题是设置关联性对于二级缓存是否更有意义。


现在我们可以通过降低二级缓存的未命中率来减少未命中惩罚。
另一个考虑是一级缓存中的数据是否在二级缓存中。 多级包含是内存层次结构的自然策略:L1 数据始终存在于 L2 中。 包含是可取的,因为 I/O 和缓存之间(或多处理器中的缓存之间)的一致性可以通过检查二级缓存来确定。
包含的一个缺点是,测量可以建议较小的一级缓存使用较小的块,而较大的二级缓存建议使用较大的块。 例如,奔腾 4 在其 L1 缓存中有 64 字节的块,在其 L2 缓存中有 128 字节的块。 通过对二级未命中进行更多工作,仍然可以保持包含。 二级缓存必须使映射到要替换的二级块的所有一级块无效,从而导致一级丢失率略高。 为了避免此类问题,许多缓存设计者在所有级别的缓存中都保持块大小相同。
但是,如果设计者只能负担比 L1 缓存稍大的 L2 缓存呢? 是否应该将其很大一部分空间用作 L1 缓存的冗余副本? 在这种情况下,一个明智的相反策略是多级排除:L1 数据永远不会在 L2 缓存中找到。 通常,排除 L1 中的高速缓存未命中会导致 L1 和 L2 之间的块交换,而不是用 L2 块替换 L1 块。 此策略可防止浪费 L2 缓存中的空间。 例如,AMD Opteron 芯片使用两个 64 KiB L1 缓存和 1 MiB L2 缓存遵守排除属性。
正如这些问题所说明的,虽然新手可能会独立设计一级和二级缓存,但如果二级缓存兼容,一级缓存的设计者的工作就更简单了。 例如,如果下一级有一个回写缓存作为重复写入的后备,并且它使用多级包含,那么使用直写就不是一场赌博。
所有缓存设计的本质是平衡快速命中和很少未命中。 对于二级缓存,命中率远低于一级缓存,因此重点转移到更少的未命中率上。 这种洞察导致更大的缓存和降低未命中率的技术,例如更高的关联性和更大的块。
Fifth Optimization: Giving Priority to Read Misses over Writes to Reduce Miss Penalty
此优化在写入完成之前提供读取服务。 我们从查看写入缓冲区的复杂性开始。
对于直写缓存,最重要的改进是适当大小的写缓冲区。 然而,写缓冲区确实使内存访问变得复杂,因为它们可能保存读取未命中所需位置的更新值。


摆脱这种困境的最简单方法是让读未命中等到写缓冲区为空。 另一种方法是在读未命中时检查写缓冲区的内容,如果没有冲突且内存系统可用,则让读未命中继续。 几乎所有台式机和服务器处理器都使用后一种方法,读取优先于写入。
还可以降低处理器在回写缓存中写入的成本。假设读取未命中将替换脏内存块。 我们可以将脏块复制到缓冲区,然后读取内存,然后写入内存,而不是将脏块写入内存,然后读取内存。 这样,处理器可能正在等待的处理器读取将更快完成。 与前面的情况类似,如果发生读未命中,处理器可以暂停直到缓冲区为空,或者检查缓冲区中字的地址是否存在冲突。
现在我们有五个优化可以减少缓存未命中惩罚或未命中率,是时候考虑减少平均内存访问时间的最终组成部分了。 命中时间很关键,因为它会影响处理器的时钟频率; 在当今的许多处理器中,高速缓存访问时间限制了时钟周期速率,即使对于需要多个时钟周期才能访问高速缓存的处理器也是如此。 因此,快速命中时间比平均内存访问时间公式的重要性成倍增加,因为它有助于一切。
Sixth Optimization: Avoiding Address Translation During Indexing of the Cache to Reduce Hit Time
即使是小而简单的高速缓存也必须处理从处理器到物理地址以访问内存的虚拟地址的转换。 如第 B.4 节所述,处理器将主内存视为内存层次结构的另一个级别,因此磁盘上存在的虚拟内存的地址必须映射到主内存。
快速处理常见情况的指南建议我们为缓存使用虚拟地址,因为命中比未命中更常见。 此类缓存称为虚拟缓存,物理缓存用于标识使用物理地址的传统缓存。 我们很快就会看到,区分两个任务很重要:索引缓存和比较地址。 因此,问题在于是使用虚拟地址还是物理地址来索引缓存,以及在标签比较中使用虚拟地址还是物理地址。 索引和标签的完全虚拟寻址消除了缓存命中的地址转换时间。 那么为什么不是每个人都构建虚拟寻址的缓存呢?
原因之一是保护。 页级保护作为虚拟到物理地址转换的一部分进行检查,无论如何都必须强制执行。 一种解决方案是在未命中时从 TLB 复制保护信息,添加一个字段来保存它,并在每次访问虚拟寻址缓存时检查它。
另一个原因是每次进程切换时,虚拟地址。指的是不同的物理地址,需要刷新缓存。 图 B.16 显示了这种冲洗对未命中率的影响。 一种解决方案是使用进程标识符标签 (PID) 增加缓存地址标签的宽度。 如果操作系统将这些标签分配给进程,它只需要在一个PID被回收时刷新缓存; 即PID区分缓存中的数据是否为该程序。 图 B.16 显示了通过使用 PID 避免缓存刷新来提高未命中率。

虚拟高速缓存不受欢迎的第三个原因是操作系统和用户程序可能对同一个物理地址使用两个不同的虚拟地址。 这些重复的地址,称为同义词或别名,可能会导致虚拟缓存中相同数据的两个副本; 如果修改了一个,另一个将具有错误的值。 使用物理缓存不会发生这种情况,因为访问将首先转换为相同的物理缓存块。
同义词问题的硬件解决方案称为抗锯齿,保证每个缓存块都有一个唯一的物理地址。 例如,AMD Opteron 使用 64 KiB 指令缓存,具有 4 KiB 页和双向集关联性; 因此,硬件必须处理与集合索引中的三个虚拟地址位相关的别名。 它通过简单地检查未命中时的所有八个可能位置(四组中的每组两个块)来避免别名,以确保没有一个与正在获取的数据的物理地址匹配。 如果找到,则无效,因此当新数据加载到缓存中时,它们的物理地址保证是唯一的。
通过强制别名共享一些地址位,软件可以使这个问题变得更容易。 例如,来自 Sun Microsystems 的旧版 UNIX,要求所有别名在其地址的最后 18 位中都相同; 这种限制称为页面着色。 请注意,页面着色只是应用于虚拟内存的设置关联映射:4 KiB (212) 页面使用 64 (26) 个集进行映射,以确保物理地址和虚拟地址在最后 18 位匹配。 此限制意味着 218 (256 K) 字节或更小的直接映射缓存永远不能有重复的块物理地址。 从缓存的角度来看,页面着色有效地增加了页面偏移量,因为软件保证虚拟和物理页面地址的最后几位是相同的。
与虚拟地址相关的最后一个领域是 I/O。 I/O 通常使用物理地址,因此需要映射到虚拟地址以与虚拟缓存交互。 (I/O 对缓存的影响在附录 D 中进一步讨论。)
充分利用虚拟和物理缓存的一种替代方法是使用部分页面偏移量(虚拟地址和物理地址中相同的部分)来索引缓存。 在使用该索引读取缓存的同时,地址的虚拟部分被转换,标签匹配使用物理地址。
这种替代方法允许立即开始缓存读取,但标签比较仍然是物理地址。 这种虚拟索引、物理标记替代方案的限制是直接映射缓存不能大于页面大小。 例如,在第 B-13 页图 B.5 中的数据缓存中,索引为 9 位,缓存块偏移量为 6 位。 要使用此技巧,虚拟页面大小必须至少为 2(9+6) 字节或 32 KiB。 如果不是,则索引的一部分必须从虚拟地址转换为物理地址。 图 B.17 显示了使用此技术时缓存、转换后备缓冲区 (TLB) 和虚拟内存的组织。

关联性可以将索引保留在地址的物理部分,但仍然支持大缓存。 回想一下,索引的大小是由这个公式控制的:
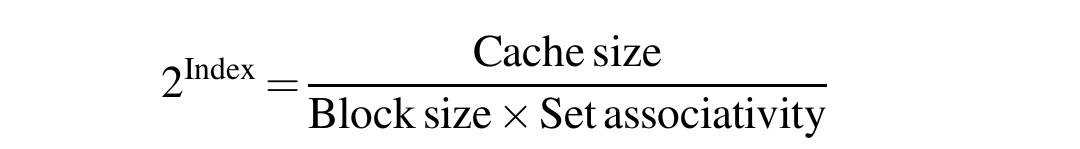
例如,加倍关联性和加倍缓存大小不会改变索引的大小。 作为一个极端的例子,IBM 3033 缓存是 16 路集关联,尽管研究表明高于 8 路集关联的未命中率几乎没有好处。 这种高关联性允许使用物理索引寻址 64 KiB 缓存,尽管 IBM 架构中存在 4 KiB 页面的缺陷。
Summary of Basic Cache Optimization
本节中用于提高未命中率、未命中惩罚和命中时间的技术通常会影响平均存储器访问方程的其他组件以及存储器层次结构的复杂性。 图 B.18 总结了这些技术并估计了对复杂性的影响,+ 表示该技术改进了该因素,- 表示它损害了该因素,空白表示它没有影响。 此图中没有任何优化可以帮助多个类别。
















 1923
1923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









