







中文期刊分类
- 1.选题意义
- 2.项目目标
- 3.reference
- 4.模型
- 5.整体方案
选题意义
- 期刊论文本数量增长迅速,人工分类耗费精力
- 某个实验表明,相同的人在不同时间段对同一批文献分类;不同的人对同一批文献分类,得到的结果发现相差较大,是因为人的主观性和知识结构的变迁会影响分类结果。机器分类不会存在此问题。
项目目标
reference
对于中文期刊分类这一特定应用场景,往往采用以下方案。
- 1.采用向量空间模型(VSM),用一个向量表示一个文本。《机器学习在中文期刊分类应用》,文章 D=(k1,k2,k3,k4,k5…..kn),这是一个多维的向量,如果维数很多,将来计算起来很麻烦,则需要降维。VSM是一种古老的方法,得到文本向量后送到LR/SVM/NN中即可。文章的数据集选的不是很科学,只选了8×4000(8个大类,每大类4000篇作为数据集)。
- 2.采用n-gram向量代表文本向量,得到文本向量后用kmeans聚类。如《一种基于N-Gram技术的中文文献自动分类方法》,数据库采用台湾中文儿童读物。
模型
- 在算法层面没有创新,因为简单的说,这是一个组合模型:把word embedding训练出的词向量按一定方式合成文本向量后扔给SVM等分类器就行了。当然写毕业论文时,在后期完全可以在应用逻辑层面加以改进。就这么简单。
- 但是,Convolutional Neural Networks for Sentence Classification这篇论文提出了一种新策略:卷积网络训练深层分类器。我想尝试一下,是将word embedding的vectors像图片一样堆砌成矩阵,用patches对这样的“像素”多层卷积。而且有作者demo在theano平台下运行。这是在tensorflow平台下训练的Convolutional Neural Network for Text Classification in Tensorflow,这是tensorflow cnn word代码的作者笔记,正在试,不过训练比较慢
- 目前的目标是实现几种分类器在同一数据集下的测评(期刊一级/二级分类正确率)。
整体方案及进展
- CNKI数据集
- raw data -> practicable data
- 训练词向量
- 用词向量表示文本
- 训练分类器
- cross validation
CNKI数据集
按照中国图书馆分类法文献可分为5个基本部类,22个大类,176个二级类,若干个三级类。本项目采集数据方法,拟使用对检索的“按图书分类”检索爬取二级类的数据(标题,关键词,摘要),如输入“A1”检索的到马克思主义相关文献。每个类的检索控制为1000篇。
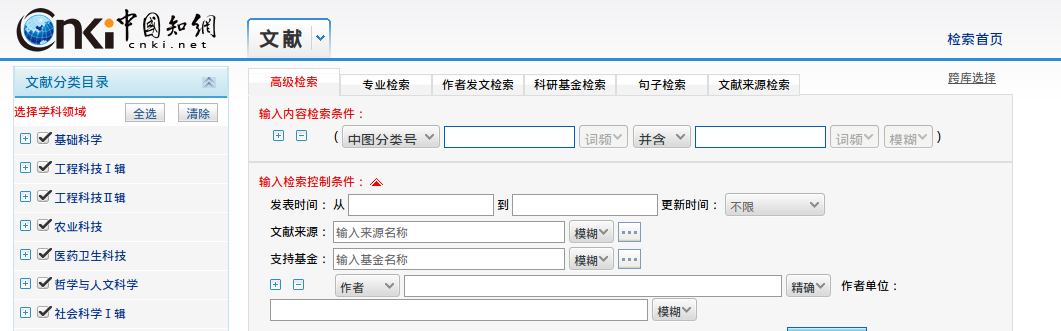
这里存在几个问题,有待探讨。
有的小类爬光了所有论文,总共不到60篇,如A1,这种情况适当考虑合并A类所有论文,为一类,即把A0/A1/A2/A3/A4/A5/A6/A7/A8合并为单独一类A类进行分类。出于这样考虑的物理行为是,文献常年投稿少,没有必要让机器做深入分类。
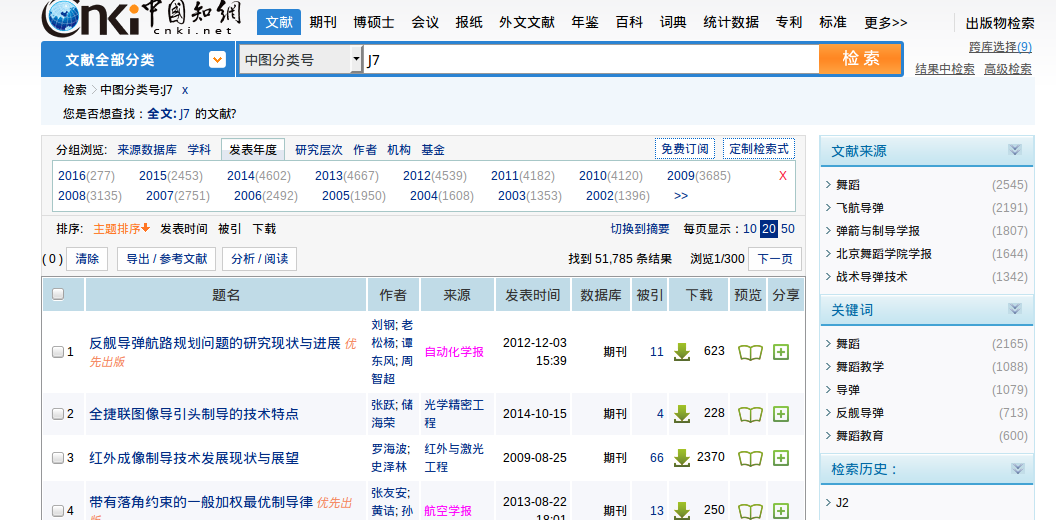
光是按照上述检索方法并不能得到很好的数据,因为中图法的分类系统里存在TN/TP/TJ等这样的类别。当输入J7检索时,爬虫难以识别所检索到的文章到底是TJ7还是J7,于是出现了下图的情况。
在这里,J7是舞蹈类文献,可是CNKI检索系统却出现了导弹类文献(TJ7),这个问题导致之前爬出的数据几乎全部作废。解决办法是,原爬虫的url为http://epub.cnki.net/kns/brief/default_result.aspx (正常检索)换为http://epub.cnki.net/kns/brief/result.aspx (高级检索),由于html结构也变了,爬虫的相关参数也需要调整。使用高级检索可以避免上述灾难性问题。
爬虫稳定性不够好,偶尔会丢失摘要,导致文本数据库不全,当然作为程序训练暂时无妨。正在修改代码,增强其稳定性。(今天发现,很多论文发表时并没有写摘要,甚至有的没有关键词。160309)
搜索时只筛选期刊作为数据。因为会议论文一般过于专业,有专业人士分类,常常无需机器分类;而硕士博士论文的摘要动辄八百一千字,果断抛弃。
最终我们得到的是:22个大类的文件夹,每个大类里存放相应小类的csv文件,每个csv文件里保存1000行文本数据。
raw data -> practicable data
对与每一篇文献的标题/关键词/摘要,需要剔除无用的信息,如标点符号,数字,英文,非utf-8字符等,需要使用正则表达式进行基本数据清洗。
虽然只提取了标题/关键词/摘要,文本量仍然很大,且不适合向量表示。需要进行关键词提取,这里采用最常用的tf-idf算法。tf-idf算法是一种统计方法,一个词在文本的重要程度由两个参数决定,tf(term frequency)和idf(inverse document frequency),前者代表一个词在文本中出现的次数多少,后者表示这个词普适度如何(如“我”,“你”,“可以”,这样的词出现再多也没用,赋给它很高的idf值)。最后用tf/idf表示最终的重要程度。对于每一篇论文来说,取排前10的关键词即可理解全文大意,总而言之,用10个词的词向量代表一篇论文。
经过上述两个步骤,即可为每篇文章得到10个关键词,就用他们来训练最终的分类器。
训练词向量
现在面临的一个关键问题是如何用向量合理表示一个词(word embedding),@南大周志华翻译为“词嵌入”。学术界常用的模型为bengio的NNLM模型,构造的三层神经网络的目的是训练一个预言模型,计算句子完整表达的概率,副作用是获得了单个词的词向量。
(抱歉,现在还不会用latex写公式,描述不方便,我就简述一下)
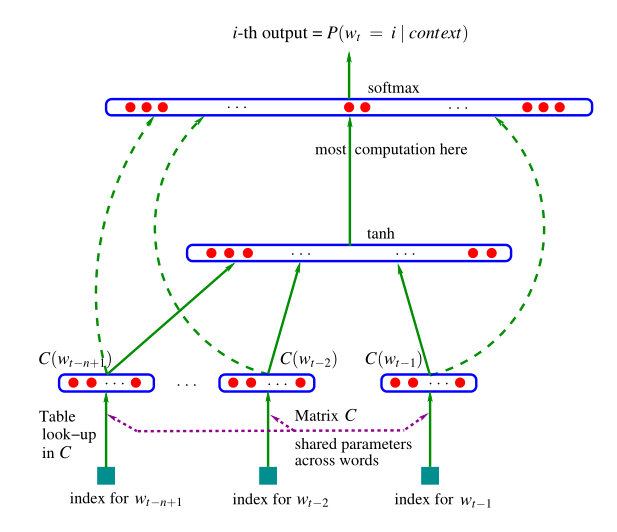
最下方的 wt−n+1,…,wt−2,wt−1 代表前 n−1 个词。现在的目的是根据这已知的 n−1 个词预测下一个词 wt。C(w) 表示词 w 所对应的词向量,我们使用一套唯一的词向量,放置于矩阵 C(一个 |V|×m 的矩阵)中。其中 |V| 表示词表中词的总数,m 表示词向量的维度。w 到 C(w) 的转化就是从矩阵中取出一行。网络第一层(输入层)是将 C(wt−n+1),…,C(wt−2),C(wt−1) 这 n−1 个向量首尾相接拼起来,形成一个 (n−1)m 维的向量。网络第二层(隐藏层)就如同普通的神经网络,直接使用偏置加权重表达神经元输出。在此之后,使用 tanh 作为激活函数。网络第三层(输出层)一共有 |V| 个节点,每个节点 表示 下一个词为 i 的未归一化 log 概率。最后使用 softmax 激活函数将输出值 y 归一化成概率。训练采用普通的前反馈+梯度下降的方法就能成功。
Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
这样的训练方式是用完整句子来训练,所以可以说它是无监督的
当然我们项目里要用的,是这个语言模型的的副作用——词向量。google的word2vec使用的CBOW模型对NNLM进行了很多优化(如用树的编码表示单词),作为工具完全可以work了。
对中文文献分类来说,需要一个类别广,知识面宽的语料库来训练词向量,这很难找。比如用搜狗新闻就难以将一些化学名词囊括,而论文里常常会出现这种稀有专业名词,人名日报则更不合理。如果用下载好的中文期刊作为语料库也不合适,主要原因是丰富度不够。我这里暂且使用中文维基百科(1.1G)作为词向量训练语料库。
使用开源项目gensim的word2vec模块可以很方便的训练出词向量模型和词向量表示(150MB),博客里暂不做展示。
训练分类器
训练方法有很多种,大抵是LR/SVM/NN等,这个作为word2vec的输出层,例如在最后一层加上softmax试试(这几天试试)。由于在爬取数据过程中产生了上述的问题(不稳定,检索模糊),很多数据正在重新收集,所以暂时无法实际操作。
160323数据集基本收集完成,爬虫还是不够robust,要命的是找不到原因,csdn并没有反爬虫,不过宿舍的网已经打不开http://www.cnki.net了,隔壁的还能打开,图书馆的也能打开,不知怎么回事。
好在经过近两星期的断断续续爬虫,终于把19个类收集齐了(一共是22个类,其中Z类非投稿内容不采集,VU两类还未采集好)















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









