






上一节我们了解了sychronized锁的原理以及锁升级,保证并发编程中的线程安全,但是sychronized的使用看起来简单,但是存在很多问题的:
(1)无法从代码层面判断,当前线程是否被锁住
(2)sychronized属于非公平锁,所有的线程都有相同的几率获取锁对象
(3)如果多个线程同时竞争一把锁,某个线程迟迟不肯释放锁资源,那么其他线程也会一直阻塞等待
(4)额外的资源消耗,当锁升级为重量级锁,需要切换到内核态由monitor分配锁资源
针对这些问题,自然会有应对策略,涉及到并发编程的3件套
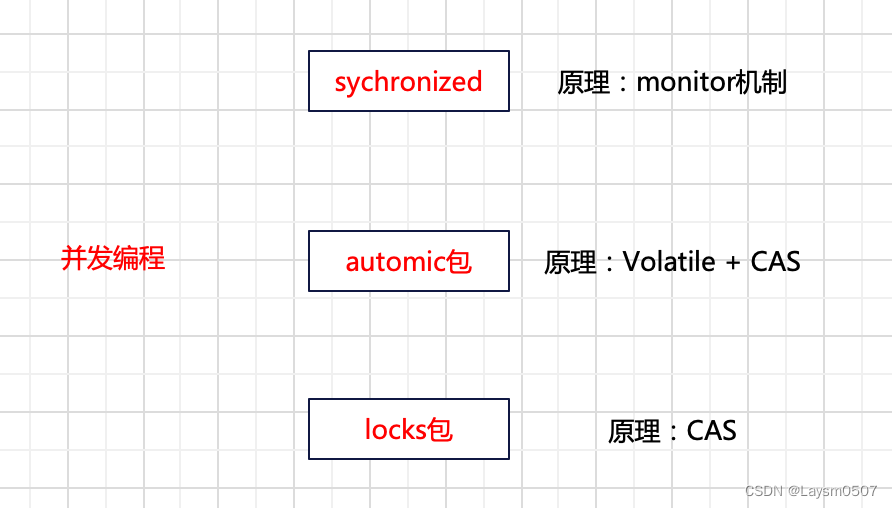
其中sychronized的原理已经了解,那么剩下的2个包,就能够针对sychronized存在的问题,做对应的解决方案
并发编程三件套
1 volatile关键字
在多线程并发中,我们经常能看到volatile的身影,线程安全满足三要素:原子性、可见性、有序性,volatile保证了可见性和有序性,在AtomicInteger中,我们看到value是被volatile修饰的
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
/**
* Creates a new AtomicInteger with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
AtomicInteger是一个原子类,同时又有volatile保证可见性和有序性,那么AtomicInteger就是一个线程安全的类
1.1 从单例模式了解volatile的原理
下面先看一个单例模式,我们最常使用的一个设计模式
class WorkManager{
private WorkManager(){}
private static WorkManager instance;
private static byte[] bytes = new byte[1];
public static WorkManager getInstance(){
if(instance == null){
synchronized (bytes){
if(instance == null){
instance = new WorkManager();
}
}
}
return instance;
}
public void get(){
}
}
有问题吗?看逻辑就是一个简单的双检锁单例模式,并没有什么问题,可在Java层面看不出问题,需要从字节码指令部分开始看
我们把.java文件反编译看下JVM字节码指令
javac WorkManager.java
javap -c -verbose WorkManager.class
public class WorkManager
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #6.#23 // java/lang/Object."<init>":()V
#2 = Fieldref #4.#24 // WorkManager.instance:LWorkManager;
#3 = Fieldref #4.#25 // WorkManager.bytes:[B
#4 = Class #26 // WorkManager
#5 = Methodref #4.#23 // WorkManager."<init>":()V
#6 = Class #27 // java/lang/Object
#7 = Utf8 instance
#8 = Utf8 LWorkManager;
#9 = Utf8 bytes
#10 = Utf8 [B
#11 = Utf8 <init>
#12 = Utf8 ()V
#13 = Utf8 Code
#14 = Utf8 LineNumberTable
#15 = Utf8 getInstance
#16 = Utf8 ()LWorkManager;
#17 = Utf8 StackMapTable
#18 = Class #27 // java/lang/Object
#19 = Class #28 // java/lang/Throwable
#20 = Utf8 <clinit>
#21 = Utf8 SourceFile
#22 = Utf8 WorkManager.java
#23 = NameAndType #11:#12 // "<init>":()V
#24 = NameAndType #7:#8 // instance:LWorkManager;
#25 = NameAndType #9:#10 // bytes:[B
#26 = Utf8 WorkManager
#27 = Utf8 java/lang/Object
#28 = Utf8 java/lang/Throwable
{
public static WorkManager getInstance();
descriptor: ()LWorkManager;
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=0
0: getstatic #2 // Field instance:LWorkManager;
3: ifnonnull 38
6: getstatic #3 // Field bytes:[B
9: dup
10: astore_0
11: monitorenter
12: getstatic #2 // Field instance:LWorkManager;
15: ifnonnull 28
18: new #4 // class WorkManager
21: dup
22: invokespecial #5 // Method "<init>":()V
25: putstatic #2 // Field instance:LWorkManager;
28: aload_0
29: monitorexit
30: goto 38
33: astore_1
34: aload_0
35: monitorexit
36: aload_1
37: athrow
38: getstatic #2 // Field instance:LWorkManager;
41: areturn
Exception table:
from to target type
12 30 33 any
33 36 33 any
LineNumberTable:
line 10: 0
line 11: 6
line 12: 12
line 13: 18
line 15: 28
line 17: 38
StackMapTable: number_of_entries = 3
frame_type = 252 /* append */
offset_delta = 28
locals = [ class java/lang/Object ]
frame_type = 68 /* same_locals_1_stack_item */
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
static {};
descriptor: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: iconst_1
1: newarray byte
3: putstatic #3 // Field bytes:[B
6: return
LineNumberTable:
line 7: 0
}
其他的地方不用看,就看这部分
0: getstatic #2 // Field instance:LWorkManager;
3: ifnonnull 38
6: getstatic #3 // Field bytes:[B
9: dup
10: astore_0
11: monitorenter
12: getstatic #2 // Field instance:LWorkManager;
15: ifnonnull 28
18: new #4 // class WorkManager
21: dup
22: invokespecial #5 // Method "<init>":()V
25: putstatic #2 // Field instance:LWorkManager;
28: aload_0
29: monitorexit
30: goto 38
33: astore_1
34: aload_0
35: monitorexit
36: aload_1
37: athrow
38: getstatic #2 // Field instance:LWorkManager;
41: areturn
我们拿单例这块做个对比
public static WorkManager getInstance(){
if(instance == null){
synchronized (bytes){
if(instance == null){
instance = new WorkManager();
}
}
}
return instance;
}
从第0行开始,执行这个静态方法,判断,如果不是空的,那么就跳到38行,直接return;
如果不为空,第11行monitorenter,代表进入同步代码块,会再次判断,是否为空,如果不为空,跳到28行,执行了monitorexit,退出同步代码块,再次跳到了38行,直接return;
关键的来了,如果还是为空,那么第18行,执行new指令,在堆内存开辟一块内存空间
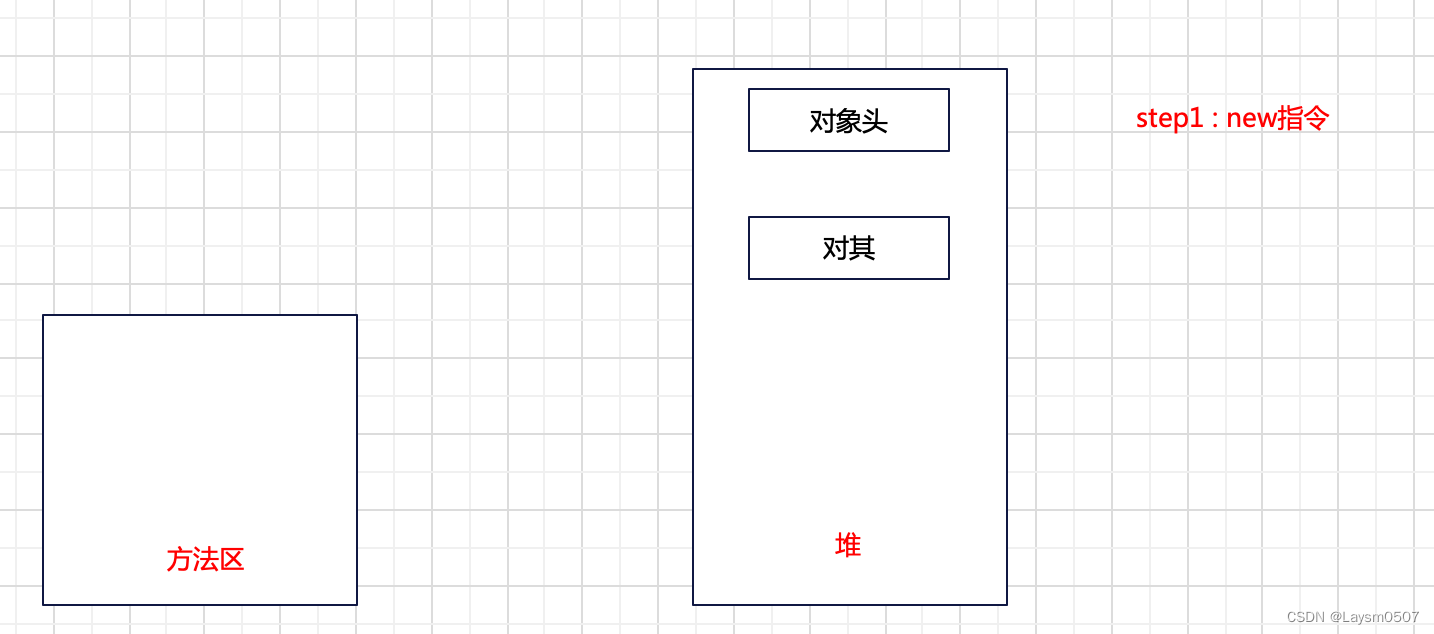
注意这里只是分配内存,创建对象头和对其,并没有将实例数据加载进来,接下来执行了invokespecial指令,这个指令是执行了WorkManager的构造方法,这个时候,将实例数据加载进来
Method "<init>":()V
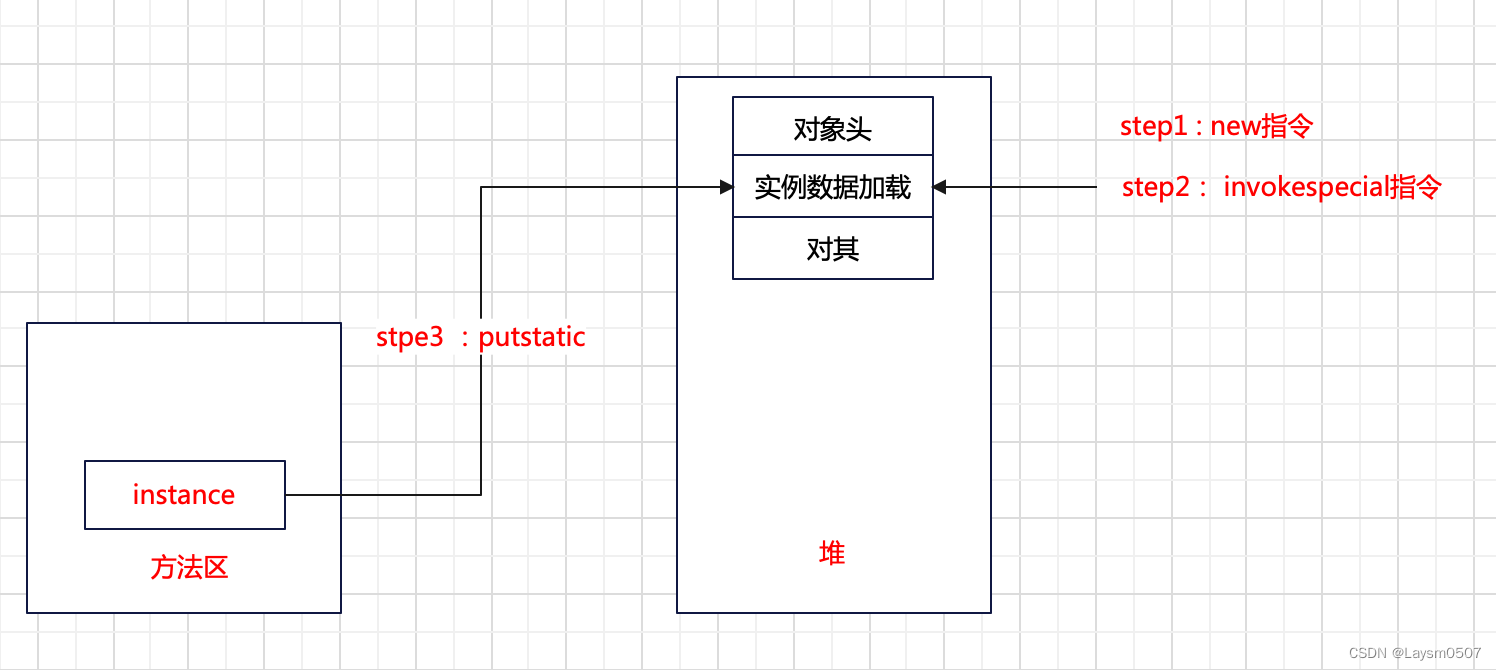
最后调用putstatic指令,为方法区的静态变量赋值,也就是声明了引用指向,同样最后执行了monitorexit,退出同步代码块,跳到38行,返回
我们可以看到,这个流程很正常,没有问题,但是实际中,真的会一直保持这个顺序执行吗?并不是,很有可能会发生变化,这就是指令重排序,那么指令重排序会导致什么问题呢?
1.1.1 指令重排序
按照正常的流程是这样的:
1 new
2 invokespecial
3 putstatic
那么为什么是会发生指令重排序?是因为指令优化带来的问题(具体的优化可以自行查找资料,了解一下),尤其是在多核执行的场景下进行。
那么什么时候会发生指令重排序?
如果改变指令的先后顺序导致运行的结果不一致,那么就不会发生指令重排序,反之就会发生指令重排序。例如:
int a = 12; // 1
int b = 10; // 2
int c = a + b; // 3
如果当前程序指令重排序,先执行3,那么结果就是 c = 0,a = 12,b = 10结果发生了变化,那么就不会发生指令重排序,3一定是最后执行;那么 1 和 2是可以指令重排序的,因此顺序的变化,不会影响c结果的输出
1 new
2 putstatic
3 invokespecial
如果在当前单例模式中,发生指令重排序,先给引用赋值,然后再调用构造方法加载实例数据,这个过程不会影响最后的结果,是没问题的,因为在new的时候,已经在堆内存中创建了这个对象,只不过为空的。
WorkManager workManager = WorkManager.getInstance();
new Thread(new Runnable() {
@Override
public void run() {
WorkManager instance = WorkManager.getInstance();
instance.get();
}
}).start();
假如在主线程中调用了getInstance方法,在子线程中同样调用,如果发生了指令重排序,在子线程中调用时,会得到当前instance不为空,其实这个时候实例数据还没有加载进来,那么调用get方法就会抛出空指针异常。
这种是非常低概率的问题,但是还是会有,怎么解决?加volatile
1.1.2 volatile禁止指令重排序
private volatile static WorkManager instance;
将instance加上volatile关键字修饰,就能禁止指令重排序(其实并不是能够直接改变指令的顺序)
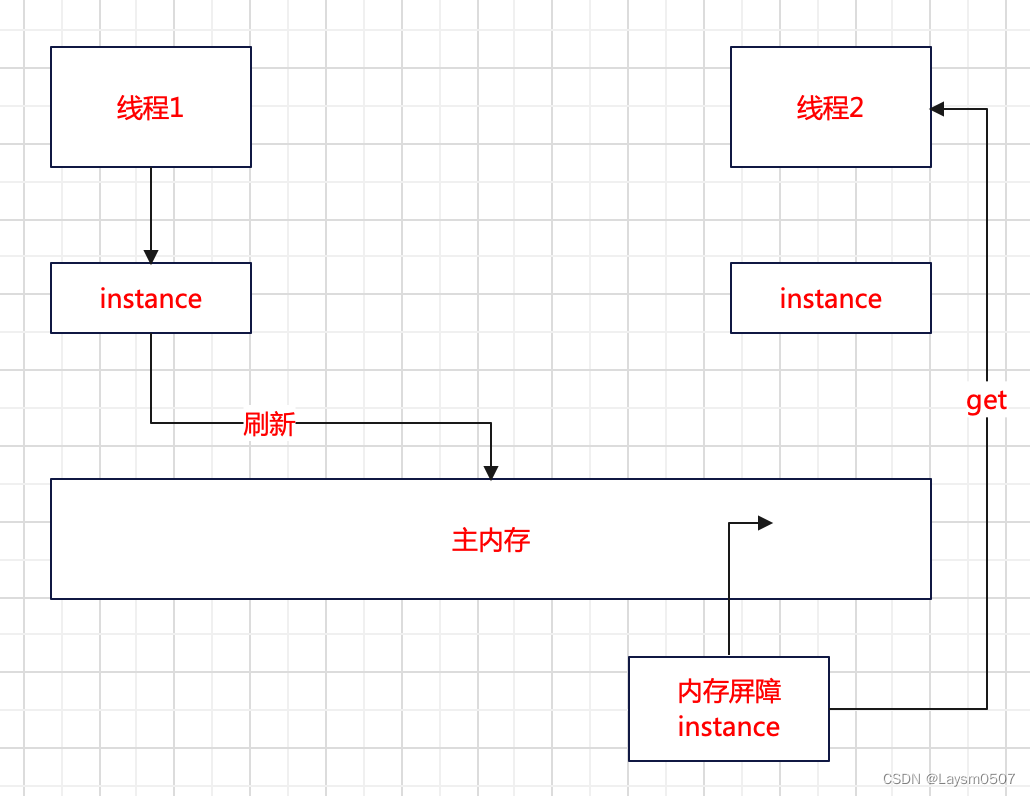
所有加volatile修饰的变量都是存在于内存屏障中的,内存屏障位于主内存,当有一个线程去修改这个变量的时候,其他线程也是可见的,当另外一个线程也去获取这个变量的时候,会等待当前线程指令执行完毕,刷新主内存,然后才能获取,这样就能避免实例数据没有加载就直接获取。
总结:
(1)修改volatile变量的值,会将修改后的值强制刷新到主内存中;
(2)当修改volatile变量的值之后,其他线程工作内存中的变量值就会失效,需要重新从主内存中读取最新的值
1.1.3 volatile的“原子性”
为什么加了引号,在上述的场景中,因为所有的线程都对变量可见,如果一个线程修改了变量,其他线程就能拿到最新的值
public class Main implements Runnable{
public volatile static int a = 0;
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
a++;
}
}
public static void main(String[] args) {
Main t1 = new Main();
Thread thread1 = new Thread(t1);
Thread thread2 = new Thread(t1);
thread1.start();
thread2.start();
try {
thread2.join();
thread1.join();
}catch (Exception e){
}
System.out.println("a==" + a);
}
}
看似是一个原子性的操作,为什么在多线程并发时并不是安全的操作,其实问题并不在于volatile,而在于 “++”,这个累加操作并不是原子性的
i++ 分为三步
step1:取值i
step2:i + 1
step3:刷新主存
volatile保证了第一步和第三步的原子性(读写操作),但是第二步并不是,那么如何能够使得i++变成一个原子性的操作?
2 CAS算法
前面我们提到,i++不是原子性操作,那么CAS就能够让i++实现原子性的操作,而且性能是超过sychronized的
private static AtomicInteger integer = new AtomicInteger(0);
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
integer.incrementAndGet();
}
}
如果使用过AtomicInteger的伙伴,知道AtomicInteger是原子类,而且incrementAndGet方法就是i++,这种方式就是原子性的操作,内部就是采用了CAS算法
2.1 CAS概念
什么是CAS,中文翻译就是比较并替换;比较什么?替换什么?
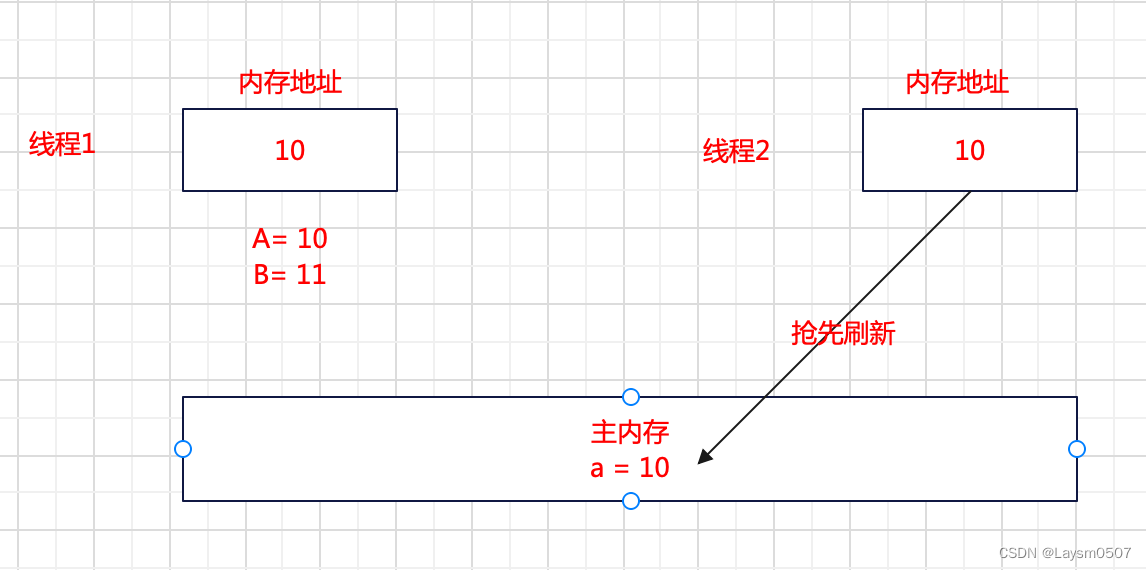
背景:假设当前主内存中有一个变量a = 10,要执行a++操作
操作:线程1将a变量加到工作内存,执行了a + 1操作,将a变成11(注意,此时还没有刷新到主内存);这个时候,线程2抢先一步,将a的值刷新到主内存变为11;
线程1怎么办?
因为我一开始从主内存中获取的值是10,但是在我提交的时候,发现(10 != 11),说明已经有线程改变了主存的值,那么我此次 + 1操作其实是无效的操作,不应该提交到主存中,就代表写失败了
线程1接下来怎么办?
既然我写失败了,那么我再去主存中,读取最新的值,再次执行 + 1操作,在写之前感知到主存的值(11 == 11)没有改变,那么这次就写成功了!
总结:
CAS算法其实就是在提交写操作的时候,判断内存地址中的值,跟我预期的值(A)是否一致,如果一致那么就写入成功
引申ABA问题:
如果一个变量被线程修改然后又修改成原来的值,那么其他线程并不能感知到修改的次数,无法做出准确的判断,这种通常采用引用计数的方式,来对外暴露接口让其他线程知道该变量被修改几次
2.2 ReentrantLock
ReentrantLock的出现,主要就是解决前文中提到的关于使用sychronized带来的问题,主要的实现原理也是CAS
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
在ReentrantLock的构造方法中,可以选择公平锁或者非公平锁;sychronized是非公平锁,所有的线程都是有同等的机会获取这把锁;而公平锁,遵循先来后到的规则
private ReentrantLock lock = new ReentrantLock(true);
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
lock.lock();
try {
a++;
}finally {
lock.unlock();
}
}
}
2.2.1 手写公平锁
public class CustomReentrantLock {
private AtomicBoolean status = new AtomicBoolean();
private Queue<Thread> queue = new ConcurrentLinkedQueue<>();
public void lock(){
Thread current = Thread.currentThread();
queue.add(current);
while (queue.peek() != current || !status.compareAndSet(false,true)){
LockSupport.park(this);
}
//同一线程再次进入,就会移除头部的对象,没有重复的线程
queue.remove();
}
public void unlock(){
//重置状态,没有被锁住
status.set(false);
LockSupport.unpark(queue.peek());
}
}
因为是公平锁,所以有一个先来后到的顺序,需要一个队列承接所有的线程;
(1)lock加锁
当一个线程进入lock方法后,队列中加入当前这个线程,然后在while循环中,会判断队列首位,也就是持有这把锁的线程是否是当前线程,第一次肯定是当前线程,而且status肯定为false,这个时候会进入while循环,并锁住;
这里有一个逻辑就是,当同一个线程再次进入之后,因为当前线程已经被锁住,而且头部就是它,那么就会从队列中头部移除这个线程;
(2)unlock解锁
解锁之后,会将status设置为false,并释放队列头部的线程,这样while循环就会跳出,同时头部的线程就会被移除;这样其他线程再次调用lock方法,就会重新锁住队列下个线程
















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











