







1、下载spark安装包
下面我提供我使用的1.6.3版本的spark安装包。
链接:https://pan.baidu.com/s/14X12wjnvgX1o8v4qTFSccA
提取码:1432
2、解压、改名
把文件放置到CentOs上,使用命令tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz解压下载的压缩包,然后通过命令mv spark-1.6.3-bin-hadoop2.6 spark-1.6.3把刚刚解压出来的文件夹进行改名操作。操作成功后,如下图:

3、修改配置文件
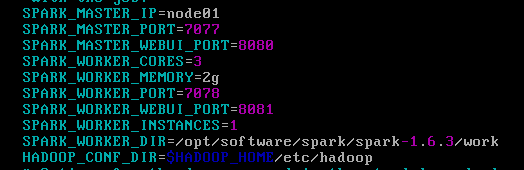
进入spark安装包的conf目录,使用mv命令将spark-env.sh.template改名为spark-env.sh。改名成功后进入spark-env.sh文件。配置如下:
SPARK_MASTER_IP=node01
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=3
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=1
SPARK_WORKER_DIR=/opt/software/spark/spark-1.6.3/work
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
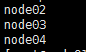
配置完spark-nev.sh之后,还需要配置一个slaves文件,在slaves里面配置spark的worker节点。
4、将配置好的安装包同步到其他节点
进入spark安装包外,直接使用scp命令将配置好的安装包直接推送到其他节点。
scp -r spark-1.6.3 node02:`pwd`
scp -r spark-1.6.3 node03:`pwd`
scp -r spark-1.6.3 node04:`pwd`
5、修改启动命令
为了避免命令冲突,我们在配置环境变量前应先进入sbin目录下,使用mv start-all.sh start-spark.sh将启动命令start-all.sh更改为start-spark.sh。
6、配置环境变量
通过vim ~/.bashrc命令可以在用户环境变量中设置spark的环境变量。如下图:

7、启动集群
在node01节点通过命令start-spark.sh启动spark集群。

启动之后可以通过node01:8080在web页面查看效果,如下图:

8、提交测试
把Application提交到集群中运行。这里运行求π的算子。这里运行命令spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi /opt/software/spark/spark-1.6.3/lib/spark-examples-1.6.3-hadoop2.6.0.jar运行结果如图:

9、高可用的Spark集群搭建
因为搭建的这个集群只有一个Master节点,万一这个节点由于某些原因意外死亡,那么整个集群就瘫痪了。这是我们不愿意看到的,所以我们可以搭建一个高可用的Spark集群,给Master找一个备用节点。搭建步骤请查阅《高可用的Spark集群搭建》。















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









