







第一部分 支持向量机
1.使用SVM对线性可分样本进行分类
样本点:

这一部分让我们使用不同的参数C观察分类效果。C就是SVM中对误分类样本的惩罚程度(正值)。C越大对训练样本的分类就会越准确,但是泛化能力也会变差。
C=1时:

C=100时:

可以看到C=100时虽然没有了误分类样本,但这个决策边界却过拟合了,当样本点轻微波动时,可能就会分类错误。而C=1时虽然有一个误分类的样本,却能满足样本点波动的条件,也就是样本点到决策边界的间距较大。
2.高斯核函数SVM
2.1 非线性分类
这一部分使用SVM进行非线性的分类
高斯核函数公式:
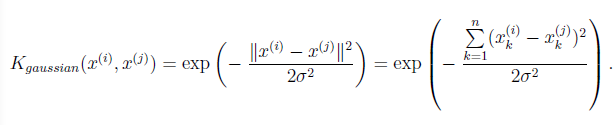
该函数的功能基本可以看作是测量两个样本点间的距离。参数σ表示宽度,这决定了随着示例之间的距离越来越远,相似性度量降低(到0)的速度有多快。
sim = exp(- sum((x1 - x2) .^ 2) / (2 * sigma^ 2));
样本点:

分类结果:

2.2 最优超参数
这一部分使用交叉验证集来找到超参数C和σ的最优值。思路就是给定一个集合,使用集合里的数值作为超参数在训练集中训练模型,在交叉验证集中计算误差,使得误差最小的参数就是最优的。
candidate = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30];
minC = 0;
minsigma = 0;
minError = size(yval, 1)
for i = 1:length(candidate),
for j = 1:length(candidate),
model = svmTrain(X, y, candidate(i), @(x1, x2) gaussianKernel(x1, x2, candidate(j)));
predictions = svmPredict(model, Xval);
error = mean(double(predictions ~= yval));
if minError > error
minError = error;
minC = candidate(i);
minsigma = candidate(j);
end
end
end
第二部分 垃圾邮件分类
1.处理邮件
这一部分使用SVM模型建立垃圾邮件分类器。邮件中的内容基本都是单词、文字、数字或其他一些符号,需要将这些内容先转化为特征向量。
样本:

该样本包含了URL,邮件地址,数字以及美元数额。许多垃圾邮件都差不多是这种形式。需要对这些内容做一种“归一化”处理,用固定的内容去替换。
1)无视大小写变换
2)移除HTML标签
3)使用‘httpaddr’替换URL
4)使用‘emailaddr’替换邮件地址
5)使用‘number’替换数字
6)使用‘dollar’替换美元符号$
7)去掉单词和后缀,ed,s,ing这些
8)移除所以非单词符号
经过处理后的样本:

2.词汇表映射
之后我们还需要一个词汇表,里面包含了在垃圾邮件中最常用的一些单词,下一步是选择我们想要在分类器中使用的单词和我们想要删除的单词。

给出词汇表后,就可以将处理后的邮件映射到词表中获得单词索引。思路就是将每个单词与词汇表进行对比,出现在词汇表中就将索引保存,没有出现的就跳过。
for i = 1:length(vocabList)
if (strcmp(vocabList{i},str))
word_indices = [word_indices;i];
end
end

3.特征提取
这一部分将上述获得的索引转化为一维向量。特征X_i∈{0,1},如果第i个单词出现在邮件中,就将X_i置1,否则为0。
x(word_indices) = 1;
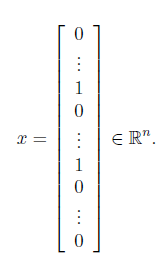
这里的n为1899。















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









