







第一部分 K-means聚类
这一部分实现K-means聚类方法并用于图像压缩。
1.实现K-means
K-mean算法是一种自动将相似数据聚类到一起的方法。该算法是一个迭代的过程,开始时随机设定一个质心,之后重复地将数据点分配到离其最近的质心,再重新计算质心。
算法过程就是重复以下两个步骤:
1)将每个样本点分配到最近的质心
2)重新计算每个类的均值作为新的质心
由于一开始选定的随机质心对结果有很大的影响,因此通常用随机化质心运行多次。最后选择代价函数最低的值作为解。
1.1 最近邻质心
代价函数(距离公式):
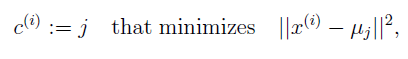
c(i)为质心的索引,μ(j)为第j个质心的坐标。
代码思路就是计算每个样本点到每个质心的距离,选择距离最小的作为最近邻质心。
for i = 1: size(X,1)
minError = sum((X(i,:) - centroids(1,:)) .^ 2);
minIdx = 1;
for j = 2: K
error = sum((X(i,:) - centroids(j,:)) .^ 2);
if error < minError
minError = error;
minIdx = j;
end
idx(i) = minIdx;
end
end
1.2 计算质心
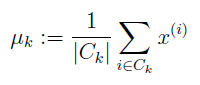
C(k)为属于第k类的数据集,如果x(3)和x(5)属于第2类,那么μ(2)=(x(3)+ x(5))/ 2
for i = 1: K
s = sum(idx == i);
if (s ~= 0)
centroids(i, :) = mean(X(find(idx == i), :))
else
centroids(i, :) = zeros(1, n);
end
end
2.图像压缩
这一部分使用使用K-means进行图像压缩。将数千种颜色的图像压缩为16种颜色。
对于一张128×128,使用RGB表示的图像,每个点用24位表示,需要存储的像素点为128×128×24 = 393216,压缩为16种颜色(4位表示)后只需要128 × 128 × 4 + 24 × 16 = 65920,基本为原图像的六分之一,我们需要使用K-means选出最适合的16种颜色。
第二部分 PCA降维
这一部分应用主成分分析降维。
1.实现PCA
计算步骤:
1)计算数据的协方差矩阵
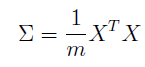
2)使用SVD计算本征矢量U1,U2,…,Un,对应于数据变换的主要成分。
在使用PCA之前,通常需要对数据进行归一化处理。
Sigma = (X' * X) / m;
[U, S, V] = svd(Sigma);
2.降维
计算出主成分之后就可以通过将数据映射到低纬度的方法,降低特征维度。
将数据集X映射到主成分U中的前K个成分。
Ureduce = U(:, 1:K);
Z = X * Ureduce;
3.重构数据的近似值
降维后可以将数据映射回原本维度
Ureduce = U(:, 1:K);
X_rec = Z * Ureduce';
结果:
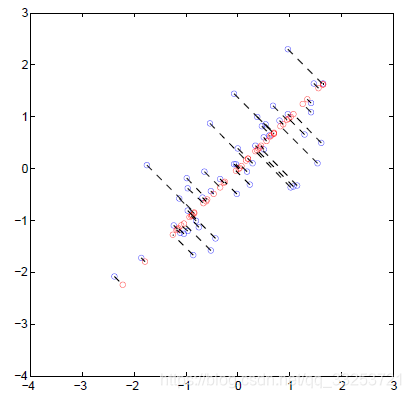
图中蓝色点表示原始数据,红色圆圈表示映射后的数据。















 7195
7195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









