







无监督学习
无监督学习的输入数据没有被标记,也没有确定的结果,需要让计算机根据样本间的相似性对样本集进行分类。
K-means聚类算法是无监督的算法
聚类
聚类是无监督的算法
聚类是不知道该数据集包含多少类,将数据集中相似的数据归纳在一起
聚类算法中,待分析的数据同时处理,来一堆数据过来,同时给分成几小堆
K-means算法
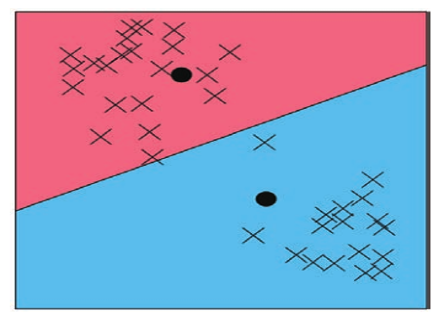
在聚类问题中,“簇”(Cluster)是一个处于核心位置的概念,只要涉及聚类问题,“簇”就一定会出现。聚类问题就是把一个个离散的样本数据点汇聚成一个个的簇,核心思想就是“合并同类项”。
K-means聚类算法的聚类过程,可以看成是不断寻找簇的质心的过程,这个过程从随机设定K个质心开始,直到找到K个真正质心为止。
K-means算法的步骤:
随机选取K个对象,以它们为质心
计算数据集到质心的距离
将对象划归(根据距离哪个质心最近)
以本类内所有对象的均值重新计算质心,完成后进行第二步
类不再变化后停止
质心计算过程:
假设一个簇中有三个数据点,分别为[2,2]、[3,3]和[3,2],在坐标轴上的图像大致呈直角三角形的三个顶点排列
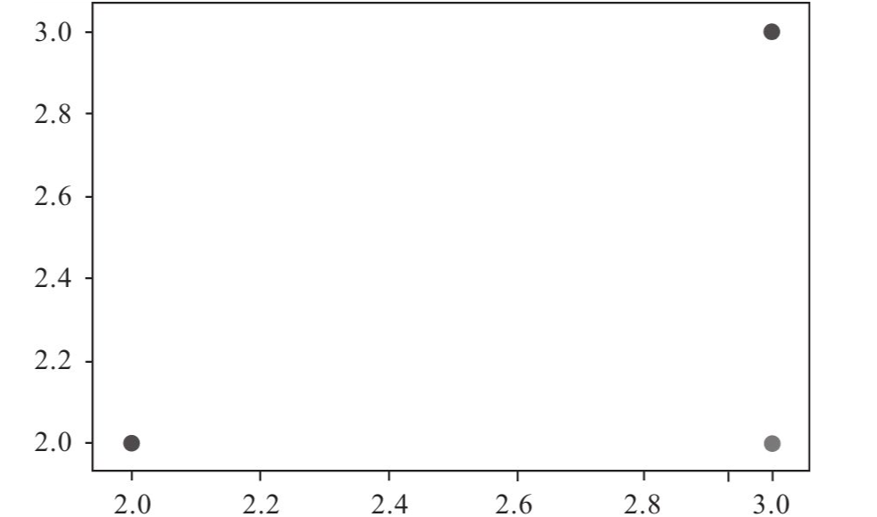
质心的坐标需要包括X轴和Y轴两项坐标值,X轴的坐标值为3个样本点X轴的均值,也就是(2+3+3)/3≈2.667,Y轴的坐标为3个样本点Y轴均值(2+3+2)/3≈2.333 ,质心的坐标为[2.667,2.333],通过均值方法计算出来的质心,大概处于该簇的中心位置

K-means算法步骤
1. 随机选取K个样本数据点,以它们为质心(K=2)
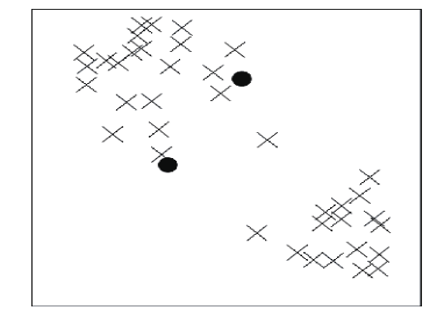
2. 计算数据集到质心的距离,将对象划归(根据距离哪个质心最近)
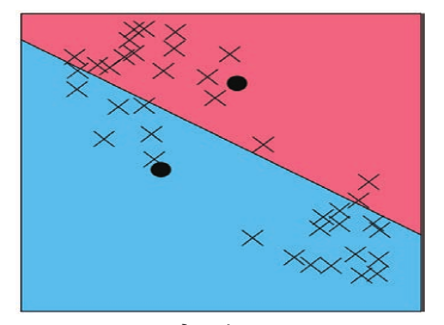
3. 以本类内所有对象的均值重新计算质心

4. 重复步骤 2 和步骤 3,直至群组成员不再发生变化
K-means算法实现
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
#导入pandas库、划分训练集和测试集方法、K-means聚类算法
df=pd.read_excel("data.xlsx")
#读取数据表
#聚类算法不需要标签,也不用划分训练集和测试集
kms = KMeans(n_clusters=4)
#数据分为4类,y对应有4个值
kms.fit(df)
#训练数据
label = kms.labels_
print(label)
#输出聚类生成的标签data数据集部分截图
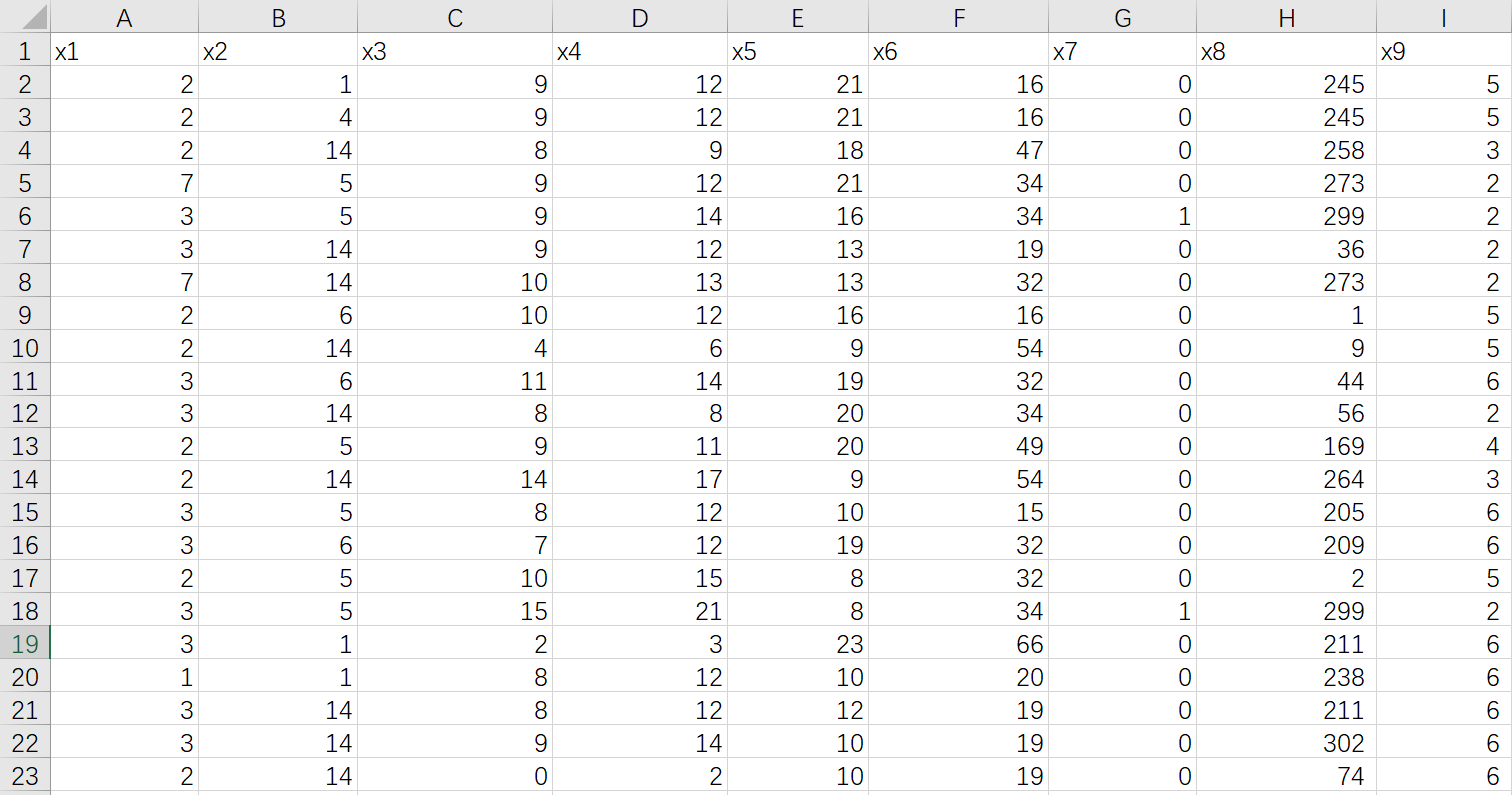
data数据集中有9个特征,2万多条数据,最后的输出结果为
[1 1 2 ... 2 0 3]















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









