







一、概述
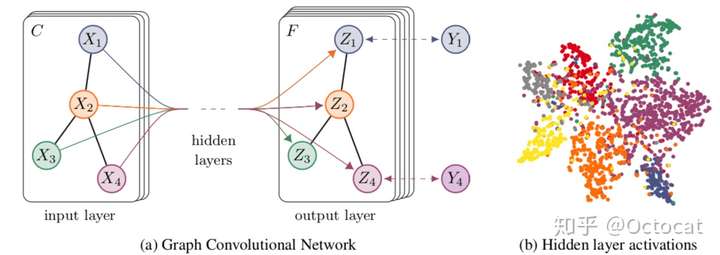
GCN是一类非常强大的用于图书局的神经网络架构,下图展示了一个两层 GCN 生成的每个节点的二维表征,即使没有经过任何训练,这些二维表征也能够保存图中节点的相对邻近性。对于CNN中的卷积,本质上是利用一个共享参数的过滤器,计算中心像素点以及相邻像素点的加权和来构成特征图实现空间特征的提取,卷积核的参数通过优化求出才能实现特征提取的作用,而GCN的理论很大一部分就是为了引入可以优化的卷积参数。

我们研究GCN的原因,主要有三点:
(1)CNN无法处理Non Euclidean Structure的数据,学术上的表达是传统的离散卷积,在Non Euclidean Structure的数据上无法保持平移不变性。通俗理解就是在拓扑图中每个顶点的相邻顶点数目都可能不同,那么当然无法用一个同样尺寸的卷积核来进行卷积运算。
(2)由于CNN无法处理Non Euclidean Structure的数据,又希望在这样的数据结构(拓扑图)上有效地提取空间特征来进行机器学习,所以GCN成为了研究的重点。
(3)读到这里大家可能会想,自己的研究问题中没有拓扑结构的网络,那是不是根本就不会用到GCN呢?其实不然,广义上来讲任何数据在赋范空间内都可以建立拓扑关联,谱聚类就是应用了这样的思想。所以说拓扑连接是一种广义的数据结构,GCN有很大的应用空间。
综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。
二、相关知识
提取拓扑图空间特征的两种方式:
(1)顶点领域
顶点领域(空间领域)是非常直观的一种方式。顾名思义:提取拓扑图上的空间特征,那么就把每个顶点相邻的邻居找出来。这里面蕴含的科学问题有二:
a.按照什么条件去找中心顶点的邻居,也就是如何确定感受野?
b.确定感受野,按照什么方式处理包含不同数目邻居的特征?
根据a,b两个问题设计算法,就可以实现目标了。推荐阅读这篇文章Learning Convolutional Neural Networks for Graphs(图4是其中一张图片,可以看出大致的思路)。

这种方法主要的缺点是:1.每个顶点取出来的邻居不同,是的计算处理必须针对每个顶点;2.提取特征的效果可能没有卷积好
(2)空间领域
空间领域就是GCN的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的convolution,最后与深度学习结合提出了Graph Convolutional Network。
这里有几个问题:
1.什么是图谱理论。简单来说就是借助于图的拉普拉斯矩阵特征值和特征向量来研究图的性质。
2.GCN为什么要利用图谱理论。这需要大量的数学定义及推导。
拉普拉斯矩阵以及在GCN中的使用:
拉普拉斯矩阵在之前的谱聚类算法简单理解一文中有过解释,这里就不再赘述。那么为什么GCN要用拉普拉斯矩阵?拉普拉斯矩阵有很多好的性质,这里总结和GCN有关的三点,当然这是个人的一些理解,对于拉普拉斯应用于GCN有严格的数学推导:
(1)拉普拉斯矩阵是对称矩阵,可以进行特征分解(谱分解),这就和GCN的光谱领域对应上了
(2)拉普拉斯矩阵只在中心顶点和一阶相连的顶点上(1-hop neighbor)有非0元素,其余之处均为0
(3)通过拉普拉斯算子与拉普拉斯矩阵进行类比
三、详解
图卷积网络(GCN)是一种在图上操作的神经网络,Graph Convolutional Network中的Graph是指数学(图论)中的用顶点和边建立相应关系的拓扑图。给定一个图 G=(E,V), 使用以下特征:
- 节点特征:每个节点
均有其特征
,可以用矩阵
表示。其中 N表示节点数, D表示每个节点的特征数。
- 图结构特征:图结构上的信息可以用邻接矩阵 A表示。
我们的目标是提取出这种广义图结构的特征,进而完成一些任务,如标签不全。
思路:
如果我们使用节点特征进行标签补全,那么完全就可以看作是一个标准的结构化特征分类问题,所以我们现在的挑战是如何使用图结构特征帮助训练。公式化的描述为:
其中.
首先,使用一种简单的解题思路:
这里W是上一层特征H的权重;是激活函数,如ReLU。这种思路是基于节点特征与其所有邻居节点有关的思想。邻接矩阵A与特征H相乘,等价于令某节点的邻居节点的特征相加。多层隐含层,表示相近似利用多层邻居的信息。但是,这样的思路存在两大问题:
- 如果节点不存在自连接(自身与自身有一条边),邻接矩阵A在对角线位置的值为0。但事实上在特征提取时,自身的信息非常重要。
- 邻接矩阵A没有被规范化,这在提取图特征时可能存在问题,比如邻居节点多的节点倾向于有更大的特征值。
针对上述两个问题,提出改进思路:
对于问题1:,让邻接矩阵A和单位矩阵I相加,引入节点自连接特征;
对于问题2:,让邻接矩阵规范化,矩阵D是对角矩阵,其对角线位置上的值就是相应节点的度,公式还可表示为
,其中
,
和
分别表示节点i和节点j的度。在这种思路下,使用多层隐含层进行训练,就可以使用多层邻居的信息。
四、训练
对于整个训练过程,我们只需要对各层的权重矩阵W进行梯度下降训练,而规范化后的邻接矩阵,在训练过程中实际上是个常量:
五、论文阅读
还有很多有关图神经网络的论文可供学习和阅读。在https://mp.weixin.qq.com/s/3CYkXj2dnehyJSPLBTVSDg和https://blog.csdn.net/u011537121/article/details/81542991中有讲解和罗列一些,可供参考。
参考:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









