









老板扔给了我一个陈年语料,让我通过文章标题回原网址爬取一下对应的doi号,文章很好定位,但是在解析标题的时候遇到了问题,a标签中混合了i、sub、sup标签,在使用xpath时不能直接使用text方法获取,所以在这里记录一下自己的解决方案。
(想不到,做完这个任务,我顺便学会了希腊字母的读音:^)
1 xpath定位
本篇博客以抓取我的主页中的某条标题为例。鼠标右键要爬的内容,点击“检查”,然后继续右键定位到的内容,选择copy,然后Copy Xpath,就可以获得xpath表达式讲真,作为懒人,我喜欢这个定位,这样就不用像beautifulSoup中那样一点点的写定位的元素了。具体操作如下图所示。
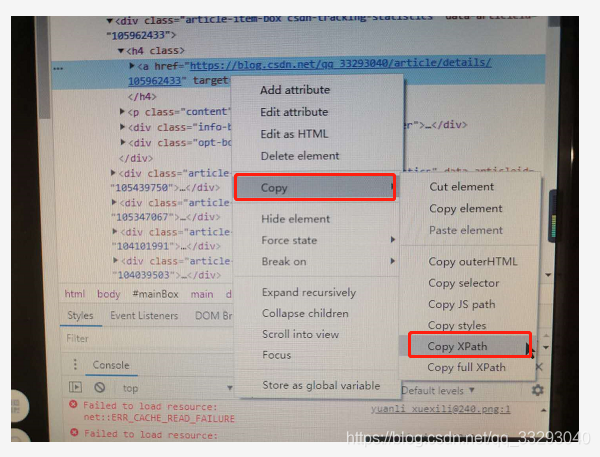
获得了XPath路径之后,就可以在直接使用lxml包进行解析。操作样例如下:
import requests
from lxml import html
etree = html.etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/537.36',
'Cookie': '写自己的',
}
url = "https://blog.csdn.net/qq_33293040" # 我的主页
html = requests.get(url, headers=headers, timeout=20)
xhtml = etree.HTML(html.content.decode("utf-8")) # 解析网页
node = xhtml.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a') # 填入刚才获得的xpath
print(node) # 输出结果:[<Element a at 0x2133a0b55c8>]2 获取子标签——我的小技巧
1)要爬取的内容。span中的内容+纯文本内容,源码形式如下:

2)解决代码:
def wash(node):
res = ''
for term in node.xpath("./node()[self::text() or self::span]"):
# 技巧1:使用node()方法获取其子标签,如我们这里是text()文本和span标签,
# 那么使用"./node()[self::text() or self::span]"即可获取;
# 如果是i标签就self::i,其他标签就不赘述了。
if str(term)[0] != '<':
res += term
# 技巧2: 这里卡了我好久,如何区分span和text,我这里用了一个强制类型转换,
# 使其变成字符型,如果一开始是'<'说明不是text,不过,如果标题开头
# 本来就是'<',这个方法就凉了。
elif term.tag == 'span': # 使用tag属性判断是不是span标签
res += term.text # 使用text属性获取文本内容
res = res.strip() # 只去掉首尾的空字符
return res # 返回拼好的文字
# 接上面第一节中的代码
print(wash(node[0]))
# 输出结果如下:
# 原创 动态规划理解——以4道力扣题为例3)如果我想获取子集的子集(孙子集)的内容呢?
解释如下:


3 结语
因为这次任务,我不再使用beautifulSoup,感觉Xpath太适合懒人使用了。他的优点是可以直接在浏览器中获取他的xpath定位,并且直接复制就好,缺点是在多层嵌套的html下会需要对xpath进行修改才能使用(比如在ul下一堆的il标签,返回的结果直接当list使用,但是习惯之后我还是觉得很方便)。
同时,我的任务中涉及文本清洗,需要大量的替换,为了节省replace的次数,我想了一招,和大家分享一下:
def term_replace_set(term):
# 用于清洗term 减少重复代码工作
replace_set = [
("’", "\'"),
("‘", "\'"),
('–', '-'),
('α', 'alpha'),
('β', 'beta'),
('κ', 'kappa'),
('ι', 'iota'),
('δ', 'delta'),
('λ', 'lambda'),
('γ', 'gamma'),
('η', 'eta'),
('≈', 'approximate'),
('Å', 'angstrom'),
(' ', ' '), # 替换奇怪的空字符
]
for rule in replace_set:
term = term.replace(rule[0], rule[1]) # 循环替代
return term(害 写完之后有种自己是艺术家的错觉,飘了飘了。另外,推荐一个学习希腊字母的网站,高中的时候都没念全,竟现在学会了。)
我们学科真是好,只要有电脑,干活少不了。告辞~















 5028
5028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









