







整理一下思路,准备结束我们的小爬爬之路。
本来想用PowerDesigner画几张图 结果惨不忍睹 : )
所以就文字简述一下吧
我们要爬的这个网页有四级页面:
1级页面:目录列表
2级页面:书籍介绍页面
3级页面:书籍章节页面
4级页面:书籍信息
所以我们采用深度优先算法的思想,伪代码如下:
从传入的初始页面,将1级页面压入栈S1
while(S1!=null){
取S1栈顶页面x;
S1弹栈;
从x里正则获取2级页面;
将2级页面压入栈S2;
while(S2!=null){
取S1栈顶页面y;
S1弹栈;
从y里正则获取三级页面z 同时获取作者、书名等信息;
将三级页面从入队列Q(先进先出,写入本地时 不会产生倒序)
while(Q!=null){
取队头页面m;
Q出队;
从m里获取书籍文字内容;
}
}
}
在实际获取书籍信息的同时,我们也在访问数据库,跟新数据库的信息,并且在本地建立相应的文件目录结构。
本来想自己写栈和队列的,但Java里封装了Stack Queue两个类,很好用,也就作罢。
下面是处理URL的类,其中包含了深度优先算法:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author Mr.Dragon
*
*
*/
public class URLContent {
public static String getURLContent(String url,String charset) {
String urlContent = "";
BufferedReader in = null;
try {
URL realURL = new URL(url);
URLConnection connection = realURL.openConnection();
connection.connect();
in = new BufferedReader(new InputStreamReader(
connection.getInputStream(), charset),50000);
String line;
while(null != (line = in.readLine())) {
urlContent += line;
}
} catch (Exception e) {
O.p("Get URLContent failed!" + e);
e.printStackTrace();
}
return urlContent;
}
public static void processingAndWrite(String urlcontent)
throws IOException{
String author = null;
String bookname = null;
Pattern p = null;
Matcher m = null;
String href = null;
String content = getURLContent(urlcontent,"GBK");
int last = 0;
{
/**
* get count of catalog
*
*/
p = Pattern.compile("<em .+?pagestats.+?/(.+?)</em>");
m = p.matcher(content);
m.find();
last = Integer.parseInt(m.group(1));
}
{
/**
* search the URL of catalog
*/
p = Pattern.compile("class=\"first.+?href=\"(.+?)\\d+.html\"");
m = p.matcher(content);
m.find();
href = m.group(1);
}
//DFS(Depth-First-Search)
String url;
Stack<String> s1 = new Stack<String>();
Stack<String> s2 = new Stack<String>();
Queue<String> q = new LinkedList<String>();
for(int i = 1;i < last; i++){
url = href+i+".html";
s1.push(url);
}
while (!s1.empty()){
O.p("1st level catalog :"+s1.peek());
content = getURLContent(s1.pop(),"GBK");
p = Pattern.compile("class.+?l_pic.+?href=\"(.+?)\"");
m = p.matcher(content);
while(m.find())s2.push(m.group(1));
String last_url_start ;
while(!s2.empty()){
O.p("2nd level catalog :"+s2.peek());
last_url_start = s2.peek().substring
(0,s2.peek().lastIndexOf('/'));
content = getURLContent(s2.pop(),"GBK");
p = Pattern.compile("<dd><a href=\"(.+?)\" title=.+?</dd>");
m = p.matcher(content);
while(m.find()){
String last_url_end = m.group(1).substring
(m.group(1).lastIndexOf('/'));
q.offer(last_url_start + last_url_end);
}
p = Pattern.compile("<h1>(.+?)</h1>.+?");
m = p.matcher(content);
m.find();
bookname = m.group(1);
p = Pattern.compile("<meta name=\"author\" content=\"(.+?)\"");
m = p.matcher(content);
m.find();
author = m.group(1);
O.p("Book name:"+bookname+" Author:"+author);
while(null != q.peek()){
O.p("3rd level catalog :"+q.peek());
content = getURLContent(q.peek(),"GBK");
q.poll();
p = Pattern.compile("<title> (.+?)</title>");
m = p.matcher(content);
m.find();
O.p(m.group(1));
String bookcontent = replaceHTMLMarks(m.group(1));
BookWriter.writeIntoFile(bookname, author,bookcontent );
}
}
}
}
public static String replaceHTMLMarks(String content){
content = content.replaceAll("<p .*?>", "\r\n");
content = content.replaceAll("<br\\s*/?>", "\r\n");
content = content.replaceAll("\\<.*?>", "");
return content;
}
public static String getCharSet(String content){
Pattern p = Pattern.compile("script charset=\"(.+?)\"");
Matcher m = p.matcher(content);
m.find();
return m.group(1);
}
} getCharSet()这个方法在设计时考虑到了,因为有的网页字符集是UTF-8,有的是GBK。…..但最后没有用到这个方法。
replaceHTMLMarks()在html中有很多标记,我们写入本地时要用对应的字符替换掉,意图显示正常。
程序最终运行结果图:
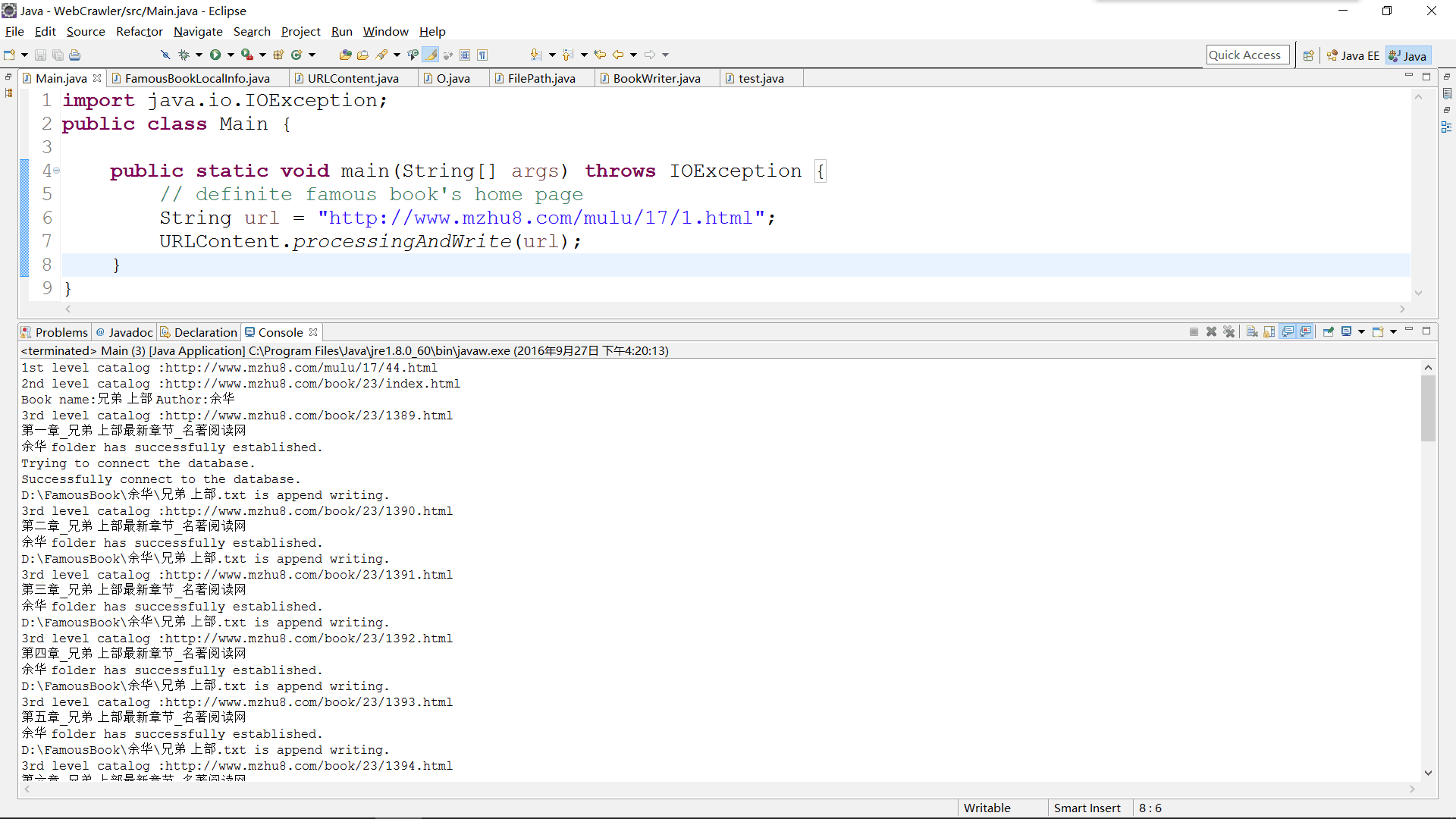
Ps:
没有开玩笑(严肃脸),我们最后放弃了,因为从四级页面获取文章详细信息的时候,正则表达式没有问题,但是读入的流里,就没有文章那一段。先开始博主以为是加密,但是这种网站也加密?舍友说可能是内嵌的PDF,Java的流读不进来。博主以为有可能,所以借了几本书JS的书,准备十一看。毕业设计如果也做大数据的话,这个爬虫会再加入并行计算和分布式吧,写成servlet,再租个服务器,或者免费的阿里云?
关于全部的源代码,可在评论里留下你的邮箱。
如有疑问、建议或指导,欢迎在评论区留言,或写邮件到我的邮箱:
keepslientiPhone@iCloud.com
后记(编辑于2016-10-19):
因为大数据的这个课程设计,组长要求必须是爬出来的,不能手动下载。
然后啊。。。。。。。。。。苦思冥想
最后发现这个文章是JS动态加载的 然后去了解了下AJAX

用FireBug看了下网页网络状态
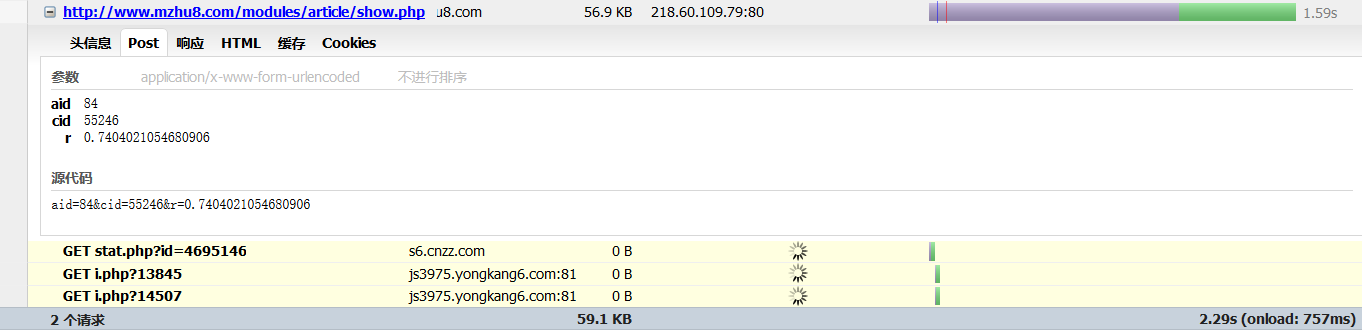
最后用模拟了这段代码 最终成功爬到了文章 哈哈 后面的词频分析 聚类 拟合就主要交给他们了 终于可以轻松一下了 -。-















 3859
3859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









