







目录
保留策略
创建存储策略
duration:保留策略的属性决定数据库中的数据保留期间。大于这个期间的数据将会被删除。
保留策略创建语法:
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
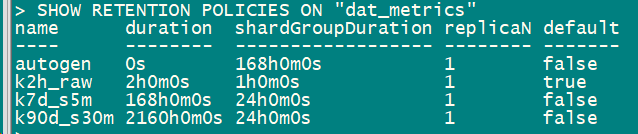
CREATE RETENTION POLICY "k2h_raw" ON "dat_metrics" DURATION 2h0m0s REPLICATION 1 DEFAULT;
CREATE RETENTION POLICY "k7d_s5m" ON "dat_metrics" DURATION 168h0m0s REPLICATION 1;
CREATE RETENTION POLICY "k90d_s30m" ON "dat_metrics" DURATION 2160h0m0s REPLICATION 1;创建连续查询
CREATE CONTINUOUS QUERY bc_query_stat_sample_by_30m ON dat_metrics BEGIN SELECT last(*), mean(*), max(*), min(*) INTO dat_metrics.k90d_s30m.bc_query_stat FROM dat_metrics.k2h_raw.bc_query_stat GROUP BY time(30m), cloud_app_id, cloud_node_id, service END;
修改保留策略语法
ALTER RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> SHARD DURATION <duration> DEFAUL
alter retention policy "k2h_raw" on "dat_metrics" DEFAULT查看数据库实例保留策略
SHOW RETENTION POLICIES ON "dat_metrics";
连续查询
介绍:
连续查询(Continuous Queries下文统一简称CQ)是InfluxQL对实时数据自动周期运行的查询,然后把查询结果写入到指定的measurement中。
基本语法:
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
BEGIN
<cq_query>
END语法描述:
cq_query
cq_query需要一个函数,一个INTO子句和一个GROUP BY time()子句:
SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
运行时间点以及覆盖的时间范围
CQ对实时数据进行操作。他们使用本地服务器的时间戳,GROUP BY time()间隔和InfluxDB的预设时间边界来确定何时执行以及查询中涵盖的时间范围。
CQs以与cq_query的GROUP BY time()间隔相同的间隔执行,并且它们在InfluxDB的预设时间边界开始时运行。如果GROUP BY time()间隔为1小时,则CQ每小时开始执行一次。
当CQ执行时,它对于now()和now()减去GROUP BY time()间隔的时间范围运行单个查询。 如果GROUP BY time()间隔为1小时,当前时间为17:00,查询的时间范围为16:00至16:59999999999。
案例需求
原始数据保留7天,5分钟采样数据保留一个月,30分钟采样数据保留一年。
以host_metrics数据库为例:
第一步 修改保留策略为数据保留7天
alter retention policy "k2h_raw" on "host_metrics" DEFAULT
第二步 创建连续查询
对host_metrics数据中的cpu measurement进行创建连续查询
CREATE CONTINUOUS QUERY cpu_sample_by_5m ON host_metrics
BEGIN
SELECT last(*), mean(*), max(*), min(*) INTO host_metrics.k7d_s5m.cpu FROM host_metrics.k2h_raw.cpu GROUP BY time(5m), host, core_id
END
CREATE CONTINUOUS QUERY cpu_sample_by_30m ON host_metrics
BEGIN
SELECT last(*), mean(*), max(*), min(*) INTO host_metrics.k90d_s30m.cpu FROM host_metrics.k2h_raw.cpu GROUP BY time(30m), host, core_id
END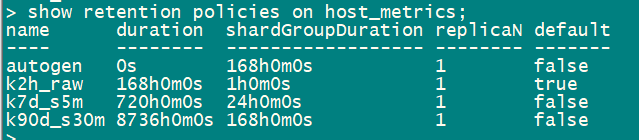
列出influxdb实例上的CQ,展示是以实例进行分组

参考1:https://jasper-zhang1.gitbooks.io/influxdb/content/Query_language/continuous_queries.html
参考2:https://docs.influxdata.com/influxdb/v1.3/query_language/data_download/
















 5580
5580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











