






1.项目背景:
今年来母婴的消费逐渐增加,这是一份关于淘宝天猫的一份母婴的销售数据。分析该数据集有利于了解目前市场的销售情况,便于做出运营决策,提高销售额。
数据集来自天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=45
该数据集有两个表,(sample)sam_tianchi_mum_baby_trade_history.csv包含了:
user_id:用户ID
auction_id:
cat_id:类别ID
cat1:跟类别ID
property:相关属性(这里的数据比较多,直接忽略,不做分析)
buy_mount:购买数量
day:购买日期

表(sample)sam_tianchi_mum_baby.csv:
user_id:用户ID
birthday:出生日期
gender:性别 0:女 ,1:男 , 2:未知
2.分析目的:
2.1.销售数量前10的的类别ID
2.2.订单量前10的类别ID
2.3.跟类别的销售数量
2.4.跟类别的订单量
2.5.年的销售数量
2.6.年的订单量
2.7.月的销售数量
2.8.月的订单量
2.9.每年各跟类别的销售数量占比
2.10.每年各各跟类别的订单量占比
2.11.用户性别分布情况
2.12.各性别的销售数量
2.13.各性别的订单量
2.14.各性别销售数量中的跟类别占比
2.15.各性别订单量中的跟类别占比
2.16.各年龄层人数分布
2.17.各年龄层销售数量情况
3.数据清洗
3.1导入包和查看数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
%matplotlib inline
df = pd.read_csv('./(sample)sam_tianchi_mum_baby_trade_history.csv',
engine='python', parse_dates=['day'])
df.shape
3.2查看列的信息
# 这里只有property这列的数据有异常,只有29827条数据,其他的数据都没异常,
# property这列的数据不做处理,这列的数据较分散,难以分析
df.info()
输出:

3.3查看表平均值这些
# 查看数据的计数、平均值、标准差、最小值、最大值、1/4分位数,2/4分位数、3/4分位数
# 这里的buy_mount最大值为1000,是异常数据
df.describe()
输出:

3.4查出重复的user_id
# 查找出重复的数据,并查看数据的详细信息,再决定进一步要怎么清洗数据,
# 数据匹配的上,有27条重复的数据
df[df.duplicated('user_id')].shape
输出:
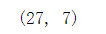
这里有27条重复的数据,进一步查看这些数据:
# 查看重复数据的ID,进一步将全部的重复数据找出来,对比下,重复数据是由于复购或者数据异常这样
df[df.duplicated('user_id')].user_id
输出:

进一步查看user_id重复的原始数据:
# 查找所有的重复数据,并按user_id排序
# 52条数据52-27
# 25个人重复购买
# 观察每个用户的下单日期day,可以看出这些用户,是重复购买的用户,数据没有异常
df[df.user_id.isin(df[df.duplicated('user_id'
)].user_id)].sort_values(by='user_id',
ascending=True)
输出:

3.5清洗buy_mount列
# 这里最大值是10000,有异常值,标准差是63.98,均值是2.54
# 这里直接将购买数量大于101的数据当做异常值,这些数据有41条,占了0.1%
df.drop(index=df[df.buy_mount>101].index, inplace=True)
4.针对目的进行分析
4.1.销售数量前10的的类别ID
sale_num_top = df.groupby("cat_id").sum()['buy_mount'].sort_values(ascending=False).head(10).reset_index()
# 这里将cat_id转换成str类型,并在前面+个_是为了画图的时候,x轴不是按cat_id大小来排序的,
# 这会导致画的数据标签错位的。
sale_num_top['cat_id'] = sale_num_top['cat_id'].apply(lambda x:'_' + str(x))
# 可视化
import seaborn as sns
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='cat_id', y='buy_mount', data=sale_num_top)
plt.xticks(rotation=70)
for a, b in enumerate(sale_num_top.buy_mount):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:
 2.2.订单量前10的类别ID
2.2.订单量前10的类别ID
order_num_top = df.groupby('cat_id').count()[
'user_id'].reset_index().rename(columns={'user_id':
'order_num'}).sort_values(
by='order_num', ascending=False).head(10)
order_num_top['cat_id'] = order_num_top['cat_id'].apply(lambda x:'_' + str(x))
#可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='cat_id', y='order_num', data=order_num_top)
plt.xticks(rotation=70)
for a, b in enumerate(order_num_top.order_num):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:
 2.3.跟类别的销售数量
2.3.跟类别的销售数量
cat1_sale_num = df.groupby('cat1').sum()['buy_mount'].reset_index()
cat1_sale_num['cat1'] = cat1_sale_num['cat1'].apply(lambda x:'_' + str(x))
#可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='buy_mount', y='cat1', data=cat1_sale_num)
plt.xticks(rotation=70)
for a, b in enumerate(cat1_sale_num.buy_mount):
plt.text(b, a, b, va='center', ha='center')
输出:

2.4.跟类别的订单量
cat1_order_num = df.groupby('cat1').count()['user_id'].reset_index().rename(
columns={'user_id': 'order_num'}).sort_values(by='order_num', ascending=False)
cat1_order_num['cat1'] = cat1_order_num['cat1'].apply(lambda x:'_' + str(x))
#可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='order_num', y='cat1', data=cat1_order_num)
plt.xticks(rotation=70)
for a, b in enumerate(cat1_order_num.order_num):
plt.text(b, a, b, va='center', ha='center')
输出:

4.5.年的销售数量
# 增加年这个辅助列
df['year'] = df['day'].dt.year
# 随机抽取10条数据看下辅助列是否正确添加
df.sample(10)
输出:

成功增加辅助列年。
year_sale_num = df.groupby('year').sum()['buy_mount'].reset_index()
#可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='year', y='buy_mount', data=year_sale_num)
plt.xticks(rotation=70)
for a, b in enumerate(year_sale_num.buy_mount):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:

4.6.年的订单量
year_order_num = df.groupby('year').count()['buy_mount'].reset_index()
# 可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='year', y='buy_mount', data=year_order_num)
plt.xticks(rotation=70)
for a, b in enumerate(year_order_num.buy_mount):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:

4.7.月的销售数量
增加付出列月:
df['month'] = df['day'].dt.month
df.sample(10)
输出:

成功添加辅助列月。
month_sale_num = df.groupby(['year', 'month']).sum()[
'buy_mount'].reset_index()
# 可视化
plt.figure(figsize=(6,4), dpi=128)
palette = sns.color_palette("mako_r", 4)
sns.lineplot(x='month', y='buy_mount', hue='year', data=month_sale_num,
palette=palette)
输出:

4.8.月的订单量
month_order_num = df.groupby(['year', 'month']).count()[
'user_id'].reset_index().rename(columns={'user_id': 'order_num'})
#可视化
plt.figure(figsize=(6,4), dpi=128)
palette = sns.color_palette("mako_r", 4)
sns.lineplot(x='month', y='order_num', hue='year', data=month_order_num,
palette=palette)
输出:

4.9.每年各跟类别的销售数量占比
year_cat1_sale_num = df.groupby(['year', 'cat1']).sum()['buy_mount'].reset_index()
#窗口函数,按年求年销售数量的总和
year_cat1_sale_num['sum'] = year_cat1_sale_num.groupby('year')['buy_mount'].transform('sum')
year_cat1_sale_num['rate'] = round((year_cat1_sale_num['buy_mount'] / year_cat1_sale_num['sum']) * 100,2)
# 传入绘图Y轴的参数
y1 = year_cat1_sale_num[year_cat1_sale_num.cat1==28].rate
y2 = year_cat1_sale_num[year_cat1_sale_num.cat1==38].rate
y3 = year_cat1_sale_num[year_cat1_sale_num.cat1==50008168].rate
y4 = year_cat1_sale_num[year_cat1_sale_num.cat1==50014815].rate
y5 = year_cat1_sale_num[year_cat1_sale_num.cat1==50022520].rate
y6 = year_cat1_sale_num[year_cat1_sale_num.cat1==122650008].rate
# 柱状堆叠图
import pyecharts.options as opts
from pyecharts.charts import Bar
years = ['2012', '2013', '2014', '2015']
bar = (
Bar()
.add_xaxis(years)
.add_yaxis('28', list(y1), stack='stack1')
.add_yaxis('38', list(y2), stack='stack1')
.add_yaxis('50008168', list(y3), stack='stack1')
.add_yaxis('50014815', list(y4), stack='stack1')
.add_yaxis('50022520', list(y5), stack='stack1')
.add_yaxis('122650008', list(y6), stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='center',
color='black',
font_size=18,
formatter="{c} %"))
.set_global_opts(title_opts=opts.TitleOpts(title='每年各跟类别的销售数量占比'),
xaxis_opts=opts.AxisOpts(name='年份'),
yaxis_opts=opts.AxisOpts(name='各跟类别的销售数量占比'))
)
bar.render('柱状堆叠图4.html')
输出:

4.10.每年各各跟类别的订单量占比
year_cat1_order_num = df.groupby(['year', 'cat1']).count()[
'user_id'].reset_index().rename(columns={'user_id': 'order_num'})
#窗口函数,按年求年订单量的总和
year_cat1_order_num['sum'] = year_cat1_order_num.groupby(
'year')['order_num'].transform('sum')
#将其转换成十位数,并保留两位小数
year_cat1_order_num['rate'] = round((year_cat1_order_num[
'order_num'] / year_cat1_order_num['sum'])*100, 2)
#柱状图的y值
y1 = year_cat1_order_num[year_cat1_order_num.cat1==28].rate
y2 = year_cat1_order_num[year_cat1_order_num.cat1==38].rate
y3 = year_cat1_order_num[year_cat1_order_num.cat1==50008168].rate
y4 = year_cat1_order_num[year_cat1_order_num.cat1==50014815].rate
y5 = year_cat1_order_num[year_cat1_order_num.cat1==50022520].rate
y6 = year_cat1_order_num[year_cat1_order_num.cat1==122650008].rate
#可视化
years = ['2012', '2013', '2014', '2015']
bar = (
Bar()
.add_xaxis(years)
.add_yaxis('28', list(y1), stack='stack1')
.add_yaxis('38', list(y2), stack='stack1')
.add_yaxis('50008168', list(y3), stack='stack1')
.add_yaxis('50014815', list(y4), stack='stack1')
.add_yaxis('50022520', list(y5), stack='stack1')
.add_yaxis('122650008', list(y6), stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='center',
color='black',
font_size=18,
formatter="{c} %"))
.set_global_opts(title_opts=opts.TitleOpts(title='每年各跟类别的订单量占比'),
xaxis_opts=opts.AxisOpts(name='年份'),
yaxis_opts=opts.AxisOpts(name='各跟类别的订单量占比'))
)
bar.render('订单量1.html')
输出:

4.11.用户性别分布情况
a:读取(sample)sam_tianchi_mum_baby.csv表,并清洗数据
baby_df = pd.read_csv('(sample)sam_tianchi_mum_baby.csv', engine='python',
parse_dates=['birthday'])
baby_df.shape
输出:

b:查看列的信息:
baby_df.info()
输出:
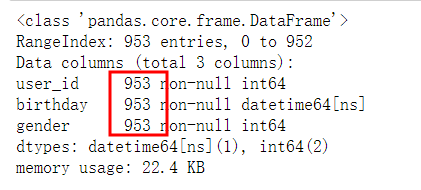
没有缺失值。
c:查看有没有重复的user_id:
baby_df.user_id.unique().size
输出:

d:性别这里有3个值:0女性,1男性,2未知,查看未知的有多少。
# 性别未知的有26人,占了总数的2.7%,直接删除处理
baby_df[baby_df.gender==2].shape
输出:

直接将性别未知的删除:
baby_df.drop(index=baby_df[baby_df.gender==2].index, inplace=True)
e:将表sam_tianchi_mum_baby_trade_history.csv和(sample)sam_tianchi_mum_baby.csv内连接作为样本来分析。
sample_df = pd.merge(df, baby_df, on='user_id', how='inner')
sample_df.shape
输出:

f:查看user_id重复的数据:
sample_df[sample_df.duplicated('user_id')]
输出:

进一步查看所有重复数据:
sample_df[sample_df.user_id.isin(['116466705', '213455117', '69889555'])]
输出:

可以看出这些事重复购买的数据,没有异常。
g:将0转换成女性,1转换成男性:
def parse_gender(x):
if x== 0:
return "女"
else:
return "男"
sample_df['gender'] = sample_df['gender'].apply(parse_gender)
sample_df
输出:

用户性别分布情况:
plt.figure(figsize=(6, 4), dpi=128)
sample_df.groupby('gender').count()['user_id'].plot(kind='pie',
autopct='%.2f%%')
输出:

4.12.各性别的销售数量
gender_sale_num = sample_df.groupby('gender').sum()['buy_mount'].reset_index()
# 可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='gender', y='buy_mount', data=gender_sale_num)
plt.xticks(rotation=70)
for a, b in enumerate(gender_sale_num.buy_mount):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:

4.13.各性别的订单量
gender_order_num = sample_df.groupby('gender').count()[
'user_id'].reset_index().rename(columns={'user_id': 'order_num'})
#可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='gender', y='order_num', data=gender_order_num)
plt.xticks(rotation=70)
for a, b in enumerate(gender_order_num.order_num):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:

4.14.各性别销售数量中的跟类别占比
gender_cat1_sale_num = sample_df.groupby(['gender', 'cat1']).sum()[
'buy_mount'].reset_index()
gender_cat1_sale_num['sum'] = gender_cat1_sale_num.groupby(
'gender')['buy_mount'].transform('sum')
gender_cat1_sale_num['rate'] = round((gender_cat1_sale_num['buy_mount'] /
gender_cat1_sale_num['sum'])*100, 2)
y1 = gender_cat1_sale_num[gender_cat1_sale_num.cat1==28].rate
y2 = gender_cat1_sale_num[gender_cat1_sale_num.cat1==38].rate
y3 = gender_cat1_sale_num[gender_cat1_sale_num.cat1==50008168].rate
y4 = gender_cat1_sale_num[gender_cat1_sale_num.cat1==50014815].rate
y5 = gender_cat1_sale_num[gender_cat1_sale_num.cat1==50022520].rate
y6 = gender_cat1_sale_num[gender_cat1_sale_num.cat1==122650008].rate
years = ['女', '男']
bar = (
Bar()
.add_xaxis(years)
.add_yaxis('28', list(y1), stack='stack1')
.add_yaxis('38', list(y2), stack='stack1')
.add_yaxis('50008168', list(y3), stack='stack1')
.add_yaxis('50014815', list(y4), stack='stack1')
.add_yaxis('50022520', list(y5), stack='stack1')
.add_yaxis('122650008', list(y6), stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='center',
color='black',
font_size=18,
formatter="{c} %"))
.set_global_opts(title_opts=opts.TitleOpts(title='各性别销售数量中的跟类别占比'),
xaxis_opts=opts.AxisOpts(name='年份'),
yaxis_opts=opts.AxisOpts(name='各跟类别的销售数量占比'))
)
bar.render('各性别销售数量中的跟类别占比1.html')
输出:

4.15.各性别订单量中的跟类别占比
gender_cat1_order_num = sample_df.groupby(['gender', 'cat1']).count()[
'user_id'].reset_index().rename(columns={'user_id': 'order_num'})
gender_cat1_order_num['sum'] = gender_cat1_order_num.groupby(
'gender')['order_num'].transform('sum')
gender_cat1_order_num['rate'] = round((gender_cat1_order_num['order_num'] /
gender_cat1_order_num['sum'])*100, 2)
y1 = gender_cat1_order_num[gender_cat1_order_num.cat1==28].rate
y2 = gender_cat1_order_num[gender_cat1_order_num.cat1==38].rate
y3 = gender_cat1_order_num[gender_cat1_order_num.cat1==50008168].rate
y4 = gender_cat1_order_num[gender_cat1_order_num.cat1==50014815].rate
y5 = gender_cat1_order_num[gender_cat1_order_num.cat1==50022520].rate
y6 = gender_cat1_order_num[gender_cat1_order_num.cat1==122650008].rate
years = ['女', '男']
bar = (
Bar()
.add_xaxis(years)
.add_yaxis('28', list(y1), stack='stack1')
.add_yaxis('38', list(y2), stack='stack1')
.add_yaxis('50008168', list(y3), stack='stack1')
.add_yaxis('50014815', list(y4), stack='stack1')
.add_yaxis('50022520', list(y5), stack='stack1')
.add_yaxis('122650008', list(y6), stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='center',
color='black',
font_size=18,
formatter="{c} %"))
.set_global_opts(title_opts=opts.TitleOpts(title='各性别订单量中的跟类别占比'),
xaxis_opts=opts.AxisOpts(name='年份'),
yaxis_opts=opts.AxisOpts(name='各跟类别的订单量占比'))
)
bar.render('各性别订单量中的跟类别占比1.html')
输出:

4.16.各年龄层人数分布
a:增加age辅助列
sample_df['age'] = sample_df['birthday'].apply(
lambda x: 2020 - int(x.year))
sample_df.sample(5)
输出:

b:增加age_type辅助列:
def parse_age_to(age):
if age <3:
return "3岁以下"
elif age<6:
return "3-5岁"
elif age<9:
return "6-8岁"
elif age<12:
return "9-11岁"
elif age<15:
return "12-14岁"
else:
return "15岁以上"
sample_df['age_type'] = sample_df['age'].apply(parse_age_to)
sample_df.sample(5)
输出:

c:各年龄层人数分布
age_type_user_num = sample_df.groupby('age_type').count()[
'user_id'].reset_index().rename(columns={'user_id': 'order_num'})
sns.scatterplot(x='age_type', y='order_num',
size='order_num', data=age_type_user_num)
输出:

4.17.各年龄层销售数量情况
age_type_sale_num = sample_df.groupby('age_type').sum()[
'buy_mount'].reset_index()
#可视化
plt.figure(figsize=(6,4), dpi=128)
sns.barplot(x='age_type', y='buy_mount', data=age_type_sale_num)
plt.xticks(rotation=70)
for a, b in enumerate(age_type_sale_num.buy_mount):
plt.text(a, b, b, va='center', ha='center', rotation=45)
输出:
















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









