







文章目录
1 提交scala程序到Spark
1.1 使用shell
spark-shell --packages org.apache.hudi:hudi-spark-bundle_2.11:0.8.0,org.apache.spark:spark-avro_2.11:2.4.4,org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.8,com.googlecode.json-simple:json-simple:1.1,com.alibaba:fastjson:1.2.51,net.minidev:json-smart:2.4.7 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --jars $HUDI_SPARK_BUNDLE --master spark://10.20.3.72:7077 --driver-class-path $HADOOP_CONF_DIR:/usr/app/apache-hive-2.3.8-bin/conf/:/software/mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar --deploy-mode client --driver-memory 1G --executor-memory 1G --num-executors 3
1.2 打包成jar包,提交到submit
先把scala程序打包成jar包,
- 1, 选择项目结构:
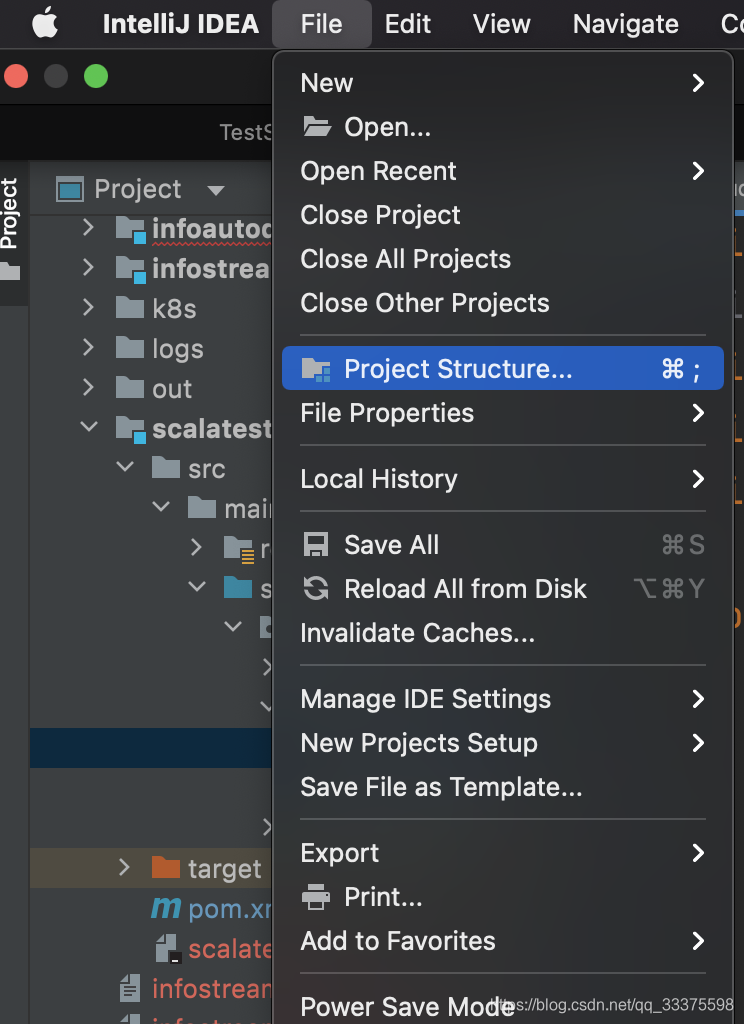 * 2,选择JAR包,
* 2,选择JAR包,
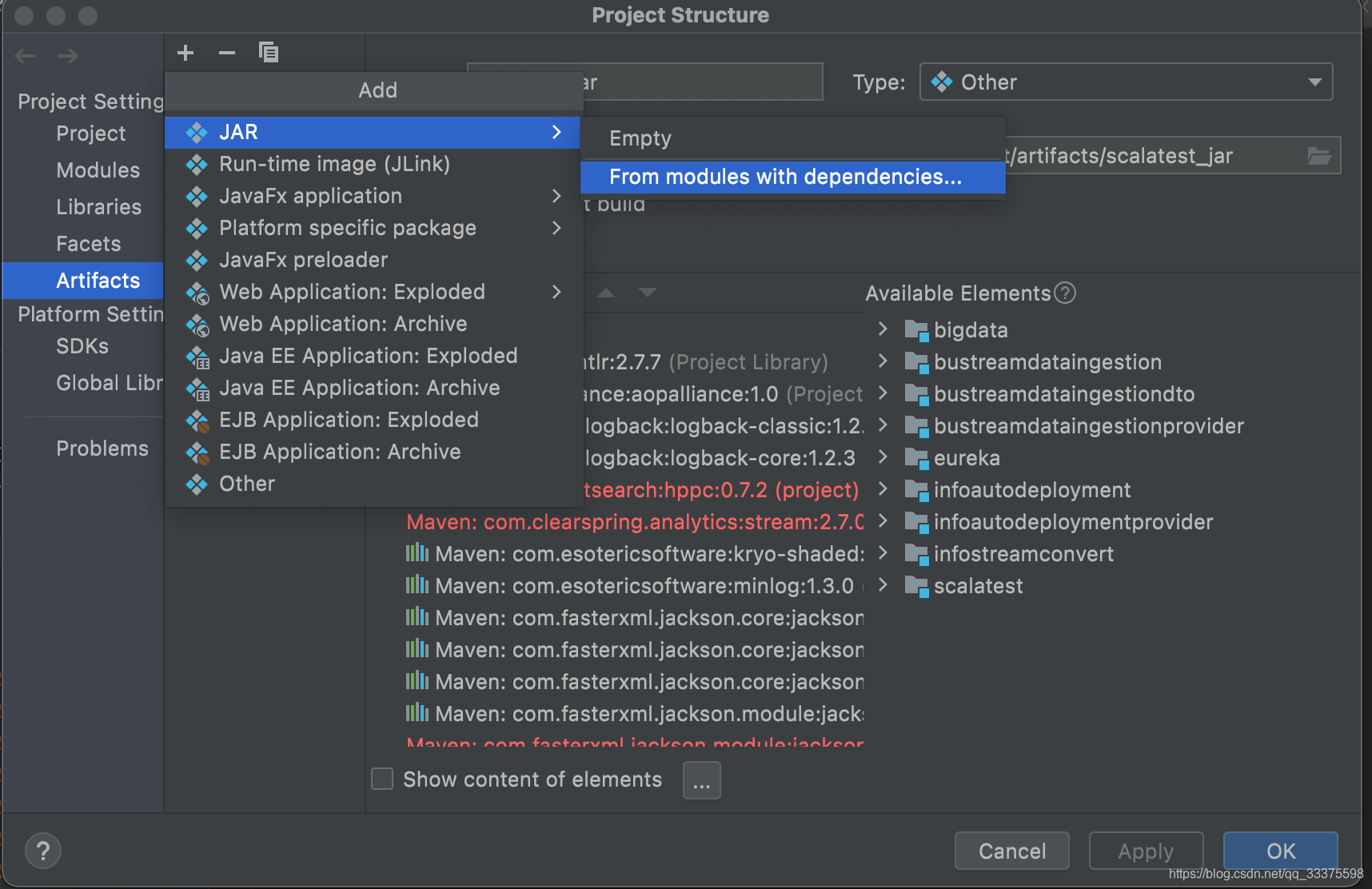
- 3,点击
Main Class,选择自己的scala主类,

- 4,选择是否打包依赖,如果是
extract to target JAR,就是打包依赖,如果是另一个,就是不打包以来
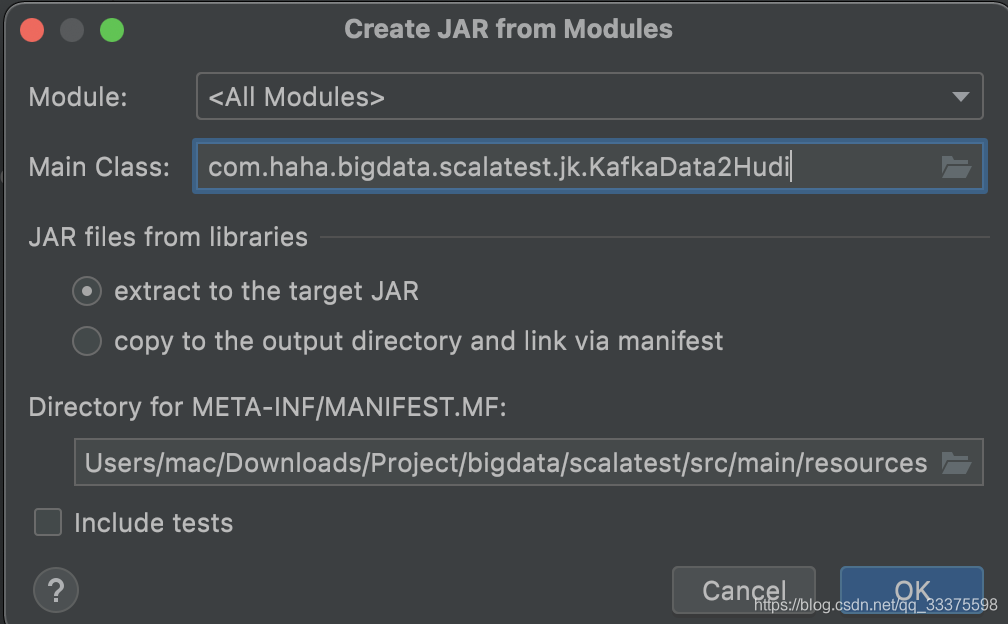
- 5,打包完成后,就是会形成一个jar包

下面就把文件使用scp上传到服务器,然后使用spark-submit提交运行。
不打包依赖时,使用下面的方式运行:
/usr/app/spark-2.4.7-bin-hadoop2.7/bin/spark-submit --jars $HUDI_SPARK_BUNDLE --master spark://10.20.3.72:7077 --driver-class-path $HADOOP_CONF_DIR:/usr/app/apache-hive-2.3.8-bin/conf/:/software/mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --deploy-mode client --driver-memory 1G --executor-memory 1G --num-executors 3 /usr/app/spark-2.4.7-bin-hadoop2.7/Script/scalatest.jar /software/member/config/kafkaHudi2.json
如果打包了依赖,就使用下面的方式运行【–master选项,可以选择不要】:
/usr/app/spark-2.4.7-bin-hadoop2.7/bin/spark-submit --class com.haha.bigdata.scalatest.jk.KafkaData2Hudi --master spark://localhost:7077 /usr/app/spark-2.4.7-bin-hadoop2.7/Script/scalatest.jar /software/member/config/kafkaHudi2.json
2 执行代码
package com.haha.bigdata.scalatest.jk
import scala.io.Source
import org.json4s.jackson.JsonMethods._
import org.json4s._
import scala.collection.mutable
import org.json4s.JsonDSL._
import org.json4s.jackson.JsonMethods._
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.sql.catalyst.dsl.expressions.{DslExpression, DslSymbol, StringToAttributeConversionHelper}
import org.apache.spark.sql.functions.{col, expr, from_json}
import org.apache.spark.sql.streaming.DataStreamReader
import org.apache.spark.sql.types._
object KafkaData2Hudi {
val typeMap = Map[String, DataType](
"string" -> org.apache.spark.sql.types.StringType,
"short" -> org.apache.spark.sql.types.ShortType,
"integer" -> org.apache.spark.sql.types.IntegerType,
"long" -> org.apache.spark.sql.types.LongType,
"float" -> org.apache.spark.sql.types.FloatType,
"double" -> org.apache.spark.sql.types.DoubleType,
"boolean" -> org.apache.spark.sql.types.BooleanType,
"byte" -> org.apache.spark.sql.types.ByteType,
"binary" -> org.apache.spark.sql.types.BinaryType,
"date" -> org.apache.spark.sql.types.DateType,
"timestamp" -> org.apache.spark.sql.types.TimestampType,
"calendarinterval" -> org.apache.spark.sql.types.CalendarIntervalType,
"null" -> org.apache.spark.sql.types.NullType)
def jvalue2datatype(jdt: JValue): DataType = {
jdt match {
case js: JString =>
val type_str = js.s
val res = typeMap.get(type_str)
if (res == None) {
require(type_str.startsWith("decimal"), s"Type ${type_str} unknow.")
val regex = """decimal\((\d+),(\d+)\)""".r
val regex(precision, scale) = type_str
org.apache.spark.sql.types.DecimalType(precision.toInt, scale.toInt)
} else {
res.get
}
case ja: JArray =>
if (ja.values.size == 1) {
ArrayType(jvalue2datatype(ja.arr(0)), true)
} else {
val keyType = jvalue2datatype(ja.arr(0))
val valueType = jvalue2datatype(ja.arr(1))
MapType(keyType, valueType, true)
}
case jo: JObject =>
val jf = jo.obj
val sfs = jf.map {
case (name: String, ctpye: JValue) =>
StructField(name, jvalue2datatype(ctpye))
}
StructType(sfs)
case other: Any =>
throw new RuntimeException(s"Not JObject/JArray/JString, type:${other.getClass}")
}
}
def str2schema(str: String) = {
val jvalue = parse(str)
require(jvalue.isInstanceOf[JObject], s"Type must be JObject, but ${jvalue} found.")
jvalue2datatype(jvalue).asInstanceOf[StructType]
}
def createKafkaStream(spark:SparkSession,
kafkaBootstrapServers:String,
topic:String,
startingOffsets:String,
maxOffsetsPerTrigger:String,
failOnDataLoss:Boolean,
enableAutoCommit:Boolean,
autoCommitIntervalMs:Int=50000):DataStreamReader = {
/*
enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。
auto.commit.interval.ms 的默认值是 5000,单位是毫秒。
默认5秒钟,一个 Consumer 将会提交它的 Offset 给 Kafka,或者每一次数据从指定的 Topic 取回时,将会提交最后一次的 Offset。
*/
import spark.implicits._
if (enableAutoCommit){
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaBootstrapServers)
.option("subscribe", topic)
.option("startingOffsets", startingOffsets)
.option("maxOffsetsPerTrigger", maxOffsetsPerTrigger)
.option("enable.auto.commit", enableAutoCommit)
.option("auto.commit.interval.ms", autoCommitIntervalMs)
.option("failOnDataLoss", failOnDataLoss)
df
}else{
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaBootstrapServers)
.option("subscribe", topic)
.option("startingOffsets", startingOffsets)
.option("maxOffsetsPerTrigger", maxOffsetsPerTrigger)
.option("enable.auto.commit", enableAutoCommit)
.option("failOnDataLoss", failOnDataLoss)
df
}
}
def main(args:Array[String]): Unit = {
println("开始初始化SparkSession环境。")
val paramKafakaHudiFilePath = args(0)
//val paramKafakaHudiFilePath = "/software/member/config/kafkaHudi2.json"
val kafakaHudiFileStr = Source.fromFile(paramKafakaHudiFilePath).getLines.toList.mkString("\n")
val jsonData = parse(kafakaHudiFileStr)
val JString(sparkSessionMaster) = (jsonData \ "spark.session.master")
val JString(sparkDefaultParallelism) = (jsonData \ "spark.default.parallelism")
val JString(sparkSerializer) = (jsonData \ "sparkSerializer")
val JString(sparkAppName) = (jsonData \ "spark.app.name")
val JString(kafkaBootstrapServers) = (jsonData \ "kafka.bootstrap.servers")
val JString(kafkaStartingOffsets) = (jsonData \ "kafka.starting.offsets")
val JString(kafkaMaxOffsetsPerTrigger) = (jsonData \ "kafka.max.offsets.perTrigger")
val JBool(kafkaFailOnDataLoss) = (jsonData \ "fail.on.data.loss")
val JBool(kafkaEnableAutoCommit) = (jsonData \ "kafka.enable.auto.commit")
val JInt(kafkaAutoCommitIntervalMs) = (jsonData\ "kafka.auto.commit.interval.ms")
val JString(hoodieCheckpointLocation) = (jsonData \ "hoodie.checkpoint.location")
val kafkaHudiMap = mutable.Map[Tuple2[String, String], String]()
val kafkaSchemaMap = mutable.Map[String, DataType]()
val kafkaTopicArray = new mutable.ArrayBuffer[String]();
val kafkaHudiList = for{
JObject(hoodieParam) <- jsonData
JField("hoodie.deltastreamer.source.kafka.topic", JString(topic)) <- hoodieParam
JField("hoodie.deltastreamer.write.file.path", JString(savePath)) <- hoodieParam
JField("hoodie.datasource.write.table.name", JString(tableName)) <- hoodieParam
JField("hoodie.datasource.write.recordkey.field", JString(recordkey)) <- hoodieParam
JField("hoodie.datasource.write.precombine.field", JString(precombine)) <- hoodieParam
JField("hoodie.datasource.write.partitionpath.field", JString(partitionpath)) <- hoodieParam
JField("hoodie.datasource.write.table.type", JString(writeTableType)) <- hoodieParam
JField("hoodie.datasource.write.operation", JString(writeOperation)) <- hoodieParam
JField("table.schema", JString(tableSchema)) <- hoodieParam
} yield (topic, savePath, tableName, recordkey, precombine, partitionpath, writeTableType, writeOperation,tableSchema)
for(data <- kafkaHudiList){
kafkaTopicArray += data._1
kafkaHudiMap += ((data._1,"savePath") -> data._2)
kafkaHudiMap += ((data._1,"tableName") -> data._3)
kafkaHudiMap += ((data._1,"recordkey") -> data._4)
kafkaHudiMap += ((data._1,"precombine") -> data._5)
kafkaHudiMap += ((data._1,"partitionpath") -> data._6)
kafkaHudiMap += ((data._1,"writeTableType") -> data._7)
kafkaHudiMap += ((data._1,"writeOperation") -> data._8)
kafkaSchemaMap += (data._1 -> str2schema(data._9))
// kafkaHudiMap("spjk21.test_hudi.test16.output", "precombine")
// val schema2 = str2schema(kafkaHudiMap("spjk21.test_hudi.test16.output", "tableSchema"))
}
val spark = SparkSession
.builder()
.master(sparkSessionMaster)
.config("spark.serializer", sparkSerializer)
.config("spark.default.parallelism", sparkDefaultParallelism)
.appName(sparkAppName)
.getOrCreate()
println("SparkSession环境初始化成功!开始读入kafka、Hudi配置参数。")
val kafkaTopicTotal = kafkaTopicArray.mkString(",")
val data=createKafkaStream(spark, kafkaBootstrapServers, kafkaTopicTotal, kafkaStartingOffsets, kafkaMaxOffsetsPerTrigger, kafkaFailOnDataLoss, kafkaEnableAutoCommit, Integer.valueOf(kafkaAutoCommitIntervalMs.toString())).load()
val queryName="query"+ kafkaTopicTotal
println("Kafka、Hudi配置参数读取成功,开始进行kafka数据流监听写入Hudi!")
val query = data.writeStream.queryName(queryName).foreachBatch { (batchDF: DataFrame, batchId: Long) => {
batchDF.persist();
for(topicName <- kafkaTopicArray){
val kafakaBatchDF = batchDF.filter(s"topic='$topicName'")
println(s"筛选数据:'$topicName'")
kafakaBatchDF.show()
if(!kafakaBatchDF.rdd.isEmpty()){
val writeDF = batchDF.withColumn("value", from_json(col("value").cast("string"), kafkaSchemaMap(topicName))).select("value.*")
//val writeDF = batchDF.select(from_json('value.cast("string"), kafkaSchemaMap(topicName)) as "value").select($"value.*")
println(s"写入数据:'$topicName'")
writeDF.show()
writeDF.write.format("org.apache.hudi").
option(TABLE_TYPE_OPT_KEY, kafkaHudiMap(topicName, "writeTableType")).
option(PRECOMBINE_FIELD_OPT_KEY, kafkaHudiMap(topicName, "precombine")).
option(RECORDKEY_FIELD_OPT_KEY, kafkaHudiMap(topicName, "recordkey")).
option(PARTITIONPATH_FIELD_OPT_KEY, kafkaHudiMap(topicName, "partitionpath")).
option(TABLE_NAME, kafkaHudiMap(topicName, "tableName")).
mode(SaveMode.Append).save( kafkaHudiMap(topicName, "savePath"))
}
batchDF.unpersist();
}
}}.option("checkpointLocation", hoodieCheckpointLocation).start()
query.awaitTermination()
}
}
对应的json文件:
{
"description": "把kafka多主题数据写入到hudi表中",
"spark.session.master": "local[*]",
"spark.default.parallelism": 4,
"spark.serializer": "org.apache.spark.serializer.KryoSerializer",
"spark.app.name": "kafka data to hudi",
"kafka.bootstrap.servers": "10.20.3.75:9092",
"kafka.starting.offsets": "latest",
"kafka.fail.on.data.loss": false,
"kafka.max.offsets.perTrigger": 10000,
"kafka.enable.auto.commit": false,
"kafka.auto.commit.interval.ms": 5000,
"hoodie.checkpoint.location": "/user/hive/warehouse/checkpoint/",
"hoodie.param": [
{
"hoodie.deltastreamer.source.kafka.topic": "spjk21.test_hudi.test16.output",
"hoodie.deltastreamer.write.file.path": "/user/hive/warehouse/test_hudi16",
"hoodie.datasource.write.table.name": "test_hudi16",
"hoodie.datasource.write.recordkey.field": "id",
"hoodie.datasource.write.precombine.field": "create_time",
"hoodie.datasource.write.partitionpath.field": "hudi_delta_streamer_ingest_date",
"table.schema":"{\"id\":\"string\",\"transaction_code\":\"string\",\"shop_id\":\"string\",\"transaction_time\":\"string\",\"transaction_mode\":\"string\",\"price\":\"double\",\"cost\":\"double\",\"hudi_delta_streamer_ingest_date\":\"string\",\"create_time\":\"string\"} ",
"hoodie.datasource.write.table.type": "MERGE_ON_READ",
"hoodie.datasource.write.operation": "upsert"
},
{
"hoodie.deltastreamer.source.kafka.topic": "spjk21.test_hudi.test17.output",
"hoodie.deltastreamer.write.file.path": "/user/hive/warehouse/test_hudi17",
"hoodie.datasource.write.table.name": "test_hudi17",
"hoodie.datasource.write.recordkey.field": "id",
"hoodie.datasource.write.precombine.field": "create_time",
"hoodie.datasource.write.partitionpath.field": "hudi_delta_streamer_ingest_date",
"table.schema":"{\"id\":\"string\",\"transaction_code\":\"string\",\"shop_id\":\"string\",\"transaction_time\":\"string\",\"transaction_mode\":\"string\",\"price\":\"double\",\"cost\":\"double\",\"hudi_delta_streamer_ingest_date\":\"string\",\"create_time\":\"string\"} ",
"hoodie.datasource.write.table.type": "MERGE_ON_READ",
"hoodie.datasource.write.operation": "upsert"
}
]
}
参数解析:
spark参数:
-
spark.session.master
- local 模式,就是单机模式,用于测试和实验
- local:只启动一个executor
- local[k]:启动k个executor
- local[*]:启动跟cpu数目相同的 executor
- cluster 模式,集群模式
- standalone Spark自带的一个资源调度框架
- yarn 模式
- yarn cluster: 这个就是生产环境常用的模式,所有的资源调度和计算都在集群环境上运行。
- yarn client: 这个是说Spark Driver和ApplicationMaster进程均在本机运行,而计算任务在cluster上。
- local 模式,就是单机模式,用于测试和实验
-
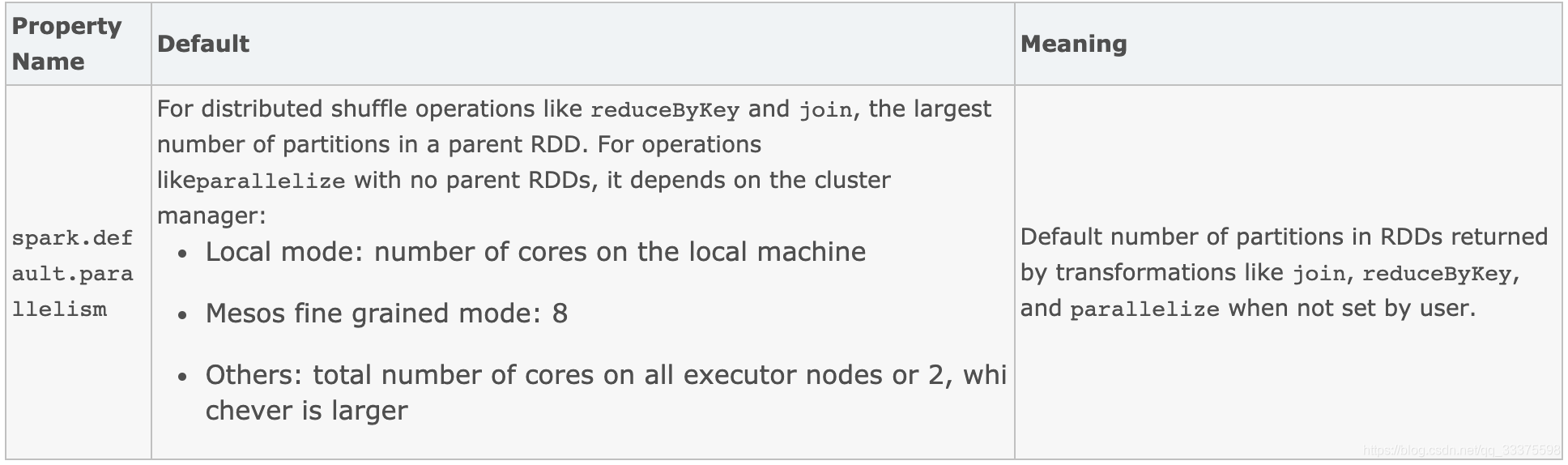
spark.default.parallelism
- 对于像reduceByKey和join这样的分布式shuffle操作,指父RDD中最大的分区数。对于没有父RDD的parallelize操作,它依赖于集群管理器: Local mode:本地机器的核数;Mesos fine grained mode:8 ;Others:所有执行器节点上的核数之和,或2个,以较大的为准r
级别的并行性:除非将每个操作的并行级别设置得足够高,否则集群将无法得到充分利用。Spark根据每个文件的大小自动设置“map”任务的数量(尽管你可以通过SparkContext的可选参数来控制它)。对于分布式的“reduce”操作,如groupByKey和reduceByKey,它使用最大的父RDD的分区数。您可以将并行级别作为第二个参数传递(请参阅spark)。PairRDDFunctions文档),或者设置配置propertyspark.default.parallelism。
- reduceByKey groupByKey join等,如果没有明确的标记出来分区,那么会调用defaultPartitioner方法生产一个分区器。逻辑如下:
- 1,如果父rdd有partitioner存在,那么找父rdd的分区数最大的rdd。如果不存在进入
2,如果存在进3, - 2,新建一个HashPartitioner,分区个数defaultNumPartitions(如果配置了spark.default.parallelism那么就是该值,否则,父rdd的分区数的最大值)。
- 3,如果合法或父rdd(第一步选出来的)的partitioner的分区数数大于defaultNumPartitions,那么就用父rdd的partitioner,否则2。
合法的判断:
父rdd(第一步选出来的)的partitioner的分区个数,不小于父rdd(第一步选出来的)分区的1/10。
- 1,如果父rdd有partitioner存在,那么找父rdd的分区数最大的rdd。如果不存在进入
- 对于像reduceByKey和join这样的分布式shuffle操作,指父RDD中最大的分区数。对于没有父RDD的parallelize操作,它依赖于集群管理器: Local mode:本地机器的核数;Mesos fine grained mode:8 ;Others:所有执行器节点上的核数之和,或2个,以较大的为准r
-
spark.default.parallelism:
-
Spark默认情况下,Spark内部是使用Java的序列化机制【
spark.serializer=org.apache.spark.serializer.JavaSerialization】,ObjectOutputStream / ObjectInputStream,对象输入输出流机制,来进行序列化。这种默认序列化机制的好处在于,处理起来比较方便;也不需要我们手动去做什么事情,只是,你在算子里面使用的变量,必须是实现Serializable接口的,可序列化即可。缺点在于,默认的序列化机制的效率不高,序列化的速度比较慢;序列化以后的数据,占用的内存空间相对还是比较大。可以手动进行序列化格式的优化。 -
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,速度要快,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
-
Kryo序列化机制,一旦启用以后,会生效的地方:
- 1、算子函数中使用到的外部变量
- 2、持久化RDD时进行序列化,StorageLevel.MEMORY_ONLY_SER
- 3、Shuffle (在进行stage间的task的shuffle操作时,节点与节点之间的task会互相大量通过网络拉取和传输文件,此时,这些数据既然通过网络传输,也是可能要序列化的,就会使用Kryo)
-
优化的地方:
- 1、算子函数中使用到的外部变量,使用Kryo以后:优化网络传输的性能,可以优化集群中内存的占用和消耗
- 2、持久化RDD,优化内存的占用和消耗;持久化RDD占用的内存越少,task执行的时候,创建的对象,就不至于频繁的占满内存,频繁发生GC。
- 3、shuffle:可以优化网络传输的性能
-
必要的参数:
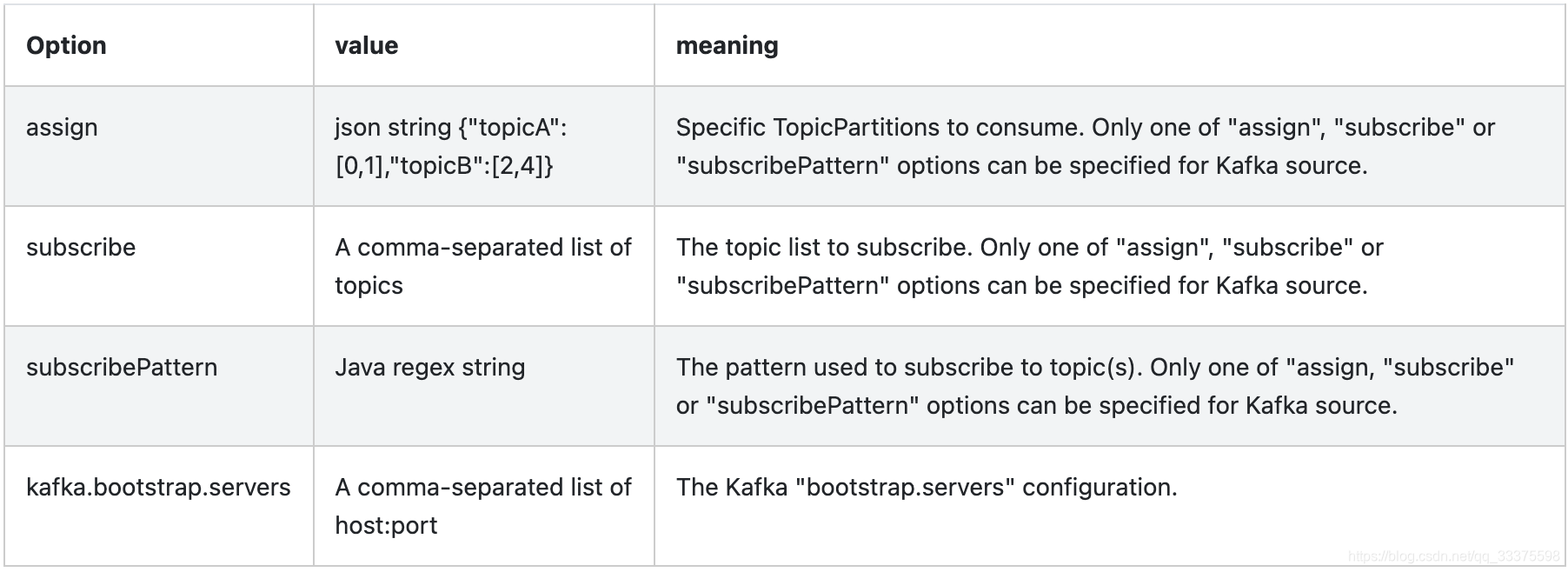
可选的参数:
- kafka.starting.offsets
- 查询开始时的起始点,可以是来自最早偏移量的“earliest”、仅来自最新偏移量的“latest”,或者是指定每个 TopicPartition 的起始偏移量的 json 字符串。在json中,-2作为偏移量可以用来指最早的,-1指的是最新的。注意:对于批量查询,latest(隐式或在 json 中使用 -1)是不允许的。对于流式查询,这仅适用于启动新查询时,并且恢复将始终从查询停止的位置开始。查询期间新发现的分区将最早开始。
- 参数:
"earliest", "latest" (streaming only), or json string """ {"topicA":{"0":23,"1":-1},"topicB":{"0":-2}} """ - 也可以使用
startingOffsetsByTimestamp,优先级高于kafka.starting.offsets,参数为时间戳【json string """ {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} """】。
- startingOffsets:
- 是否在数据可能丢失时(例如,删除主题或偏移超出范围)使查询失败。这可能是一场虚惊。当它不能像您期望的那样工作时,您可以禁用它。
- maxOffsetsPerTrigger:
- 对每个触发器间隔处理的最大偏移量的速率限制。指定的偏移量总数将按比例划分到不同卷的topicPartitions上。
- enable.auto.commit + auto.commit.interval.ms :
- enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。
- auto.commit.interval.ms 的默认值是 5000,单位是毫秒。
- 默认5秒钟,一个 Consumer 将会提交它的 Offset 给 Kafka,或者每一次数据从指定的 Topic 取回时,将会提交最后一次的 Offset。
- 但是在一些特殊场景下,我们的 Consumer 正在消费一个 Offset 是100的消息,同时这个 Consumer 取回了一些数据,这个 Offset 提交了,然后 Consumer 崩溃了。在我们回来的时候,我们会重新从最新提交的 Offset 去进行消息的消费,但是我们如何能安全地说,我们没有丢失消息,并且这个新消息的 Offset 不会比刚刚被处理的那个消息靠后呢?解决这个问题的方案就是我们手动地提交这个 Offset,在处理完这些消息之后。这给与了我们完全的控制,什么时候去处理一个消息,什么时候去让 Kafka 知道这个。
Hudi参数:
Hudi支持两种表类型:
| 写时复制(CoW) | 读时合并(MoR) |
|---|---|
| 写入CoW表时,将运行Ingest-Reconcile-Compact-Purge周期。每次写操作后,CoW表中的数据始终是最新记录,对于需要尽快读取最新数据的场景,可首选此模式。数据仅以列文件格式(parquet)存储在CoW表中,由于每个写操作都涉及压缩和覆盖,因此此模式产生的文件最少。 | MoR表专注于快速写操作。写入这些表将创建增量文件,随后将其压缩以生成读取时的最新数据,压缩操作可以同步或异步完成,数据以列文件格式(parquet)和基于行的文件格式(avro)组合存储。 |
Hudi文档中提到的两种表格格式之间的权衡取舍:
| Trade-off | CoW MoR | MoR |
|---|---|---|
| 数据延迟 | Higher Lower | Lower |
| 更新开销 | (I/O) Higher(重写整个parquet文件) | Lower (追加到delta log文件) |
| Parquet文件大小 | Smaller (高update(I/0) 开销) | Larger (低更新开销) |
| Write Amplification | Higher | Lower (由compaction策略决定) |
写入的选项:
- hoodie.table.name【必须】:这是必填字段,每个表都应具有唯一的名称。
- hoodie.datasource.write.table.name【必须】:Hive表名,用于将数据集注册到其中。
- hoodie.datasource.write.table.type,定义表的类型-默认值为COPY_ON_WRITE。对于MoR表,将此值设置为MERGE_ON_READ。
- hoodie.datasource.write.recordkey.field:将此视为表的主键。此属性的值是DataFrame中列的名称,该列是主键。
- hoodie.datasource.write.partitionpath.field:写入分区字段。
- hoodie.datasource.write.operation,定义写操作的类型。值可以为upsert,insert,bulk_insert和delete,默认值为upsert。
- 插入:
- upsert:插入更新
- insert:插入
- bulk_insert:批插入 - 删除:
- 硬删除
- 软删除
- 插入:
| UPSERT(插入更新) | INSERT(插入) | BULK_INSERT(批插入) |
|---|---|---|
| 这是默认操作,在该操作中,通过查找索引,首先将输入记录标记为插入或更新。 在运行启发式方法以确定如何最好地将这些记录放到存储上,如优化文件大小之类后,这些记录最终会被写入。 对于诸如数据库更改捕获之类的用例,建议该操作,因为输入几乎肯定包含更新。 | 就使用启发式方法确定文件大小而言,此操作与插入更新(UPSERT)非常相似,但此操作完全跳过了索引查找步骤。 因此,对于日志重复数据删除等用例(结合下面提到的过滤重复项的选项),它可以比插入更新快得多。 插入也适用于这种用例,这种情况数据集可以允许重复项,但只需要Hudi的事务写/增量提取/存储管理功能。 | 插入更新和插入操作都将输入记录保存在内存中,以加快存储优化启发式计算的速度(以及其它未提及的方面)。 所以对Hudi数据集进行初始加载/引导时这两种操作会很低效。批量插入提供与插入相同的语义,但同时实现了基于排序的数据写入算法, 该算法可以很好地扩展数百TB的初始负载。但是,相比于插入和插入更新能保证文件大小,批插入在调整文件大小上只能尽力而为。 |
| 删除 | |
| 软删除 | 硬删除 |
| 使用软删除时,用户希望保留键,但仅使所有其他字段的值都为空。通过确保适当的字段在数据集模式中可以为空,并在将这些字段设置为null之后直接向数据集插入更新这些记录,即可轻松实现这一点。 | 这种更强形式的删除是从数据集中彻底删除记录在存储上的任何痕迹。 这可以通过触发一个带有自定义负载实现的插入更新来实现,这种实现可以使用总是返回Optional.Empty作为组合值的DataSource或DeltaStreamer。 Hudi附带了一个内置的org.apache.hudi.EmptyHoodieRecordPayload类,它就是实现了这一功能。 |
- hoodie.datasource.write.precombine.field:更新数据时,如果存在两个具有相同主键的记录,则此列中的值将决定更新哪个记录。选择诸如时间戳记的列将确保选择具有最新时间戳记的记录。
- hoodie.upsert.shuffle.parallelism、hoodie.insert.shuffle.parallelism:最初导入数据后,此并行度将控制用于读取输入记录的初始并行度。 确保此值足够高,例如:1个分区用于1 GB的输入数据
3 库(json字符串和StructType相互转换)
import org.json4s.JsonDSL._
import org.json4s.jackson.JsonMethods._
import org.json4s._
import org.apache.spark.sql.types._
object SchemaUtil {
def main(args: Array[String]): Unit = {
val schema = StructType(
StructField("name", StringType) ::
StructField("age", IntegerType) ::
StructField("score", ArrayType(ShortType, true)) ::
StructField("params", StructType(Array(StructField("extra", StringType)))) ::
StructField("goal", MapType(StringType, DoubleType, true)) :: Nil)
val str = schema2str(schema)
val schema2 = str2schema(str)
println(str)
println(schema2)
//{"name":"string","age":"integer","score":["short"],"params":{"extra":"string"},"goal":["string","double"]}
//StructType(StructField(name,StringType,true), StructField(age,IntegerType,true), StructField(score,ArrayType(ShortType,true),true), StructField(params,StructType(StructField(extra,StringType,true)),true), StructField(goal,MapType(StringType,DoubleType,true),true))
}
/*
* 将schema转为json字符串,有利于保存
*/
def schema2str(schema: StructType) = {
val jobj = datatype2jvalue(schema)
compact(render(jobj))
}
/*
* 将json字符串转为schema
*/
def str2schema(str: String) = {
val jvalue = parse(str)
require(jvalue.isInstanceOf[JObject], s"Type must be JObject, but ${jvalue} found.")
jvalue2datatype(jvalue).asInstanceOf[StructType]
}
private[this] def datatype2jvalue(dt: DataType): JValue = {
dt match {
case st: StructType =>
val r = st.map {
case StructField(name, dataType, _, _) =>
val json: JObject = (name -> datatype2jvalue(dataType))
json
}
r.reduce(_ ~ _)
case at: ArrayType =>
JArray(List(datatype2jvalue(at.elementType)))
case mt: MapType =>
JArray(List(datatype2jvalue(mt.keyType), datatype2jvalue(mt.valueType)))
case _ => JString(dt.typeName)
}
}
private[this] val typeMap = Map[String, DataType](
"string" -> org.apache.spark.sql.types.StringType,
"short" -> org.apache.spark.sql.types.ShortType,
"integer" -> org.apache.spark.sql.types.IntegerType,
"long" -> org.apache.spark.sql.types.LongType,
"float" -> org.apache.spark.sql.types.FloatType,
"double" -> org.apache.spark.sql.types.DoubleType,
"boolean" -> org.apache.spark.sql.types.BooleanType,
"byte" -> org.apache.spark.sql.types.ByteType,
"binary" -> org.apache.spark.sql.types.BinaryType,
"date" -> org.apache.spark.sql.types.DateType,
"timestamp" -> org.apache.spark.sql.types.TimestampType,
"calendarinterval" -> org.apache.spark.sql.types.CalendarIntervalType,
"null" -> org.apache.spark.sql.types.NullType)
private[this] def jvalue2datatype(jdt: JValue): DataType = {
jdt match {
case js: JString =>
val type_str = js.s
val res = typeMap.get(type_str)
if (res == None) {
require(type_str.startsWith("decimal"), s"Type ${type_str} unknow.")
val regex = """decimal\((\d+),(\d+)\)""".r
val regex(precision, scale) = type_str
org.apache.spark.sql.types.DecimalType(precision.toInt, scale.toInt)
} else {
res.get
}
case ja: JArray =>
if (ja.values.size == 1) {
ArrayType(jvalue2datatype(ja.arr(0)), true)
} else {
val keyType = jvalue2datatype(ja.arr(0))
val valueType = jvalue2datatype(ja.arr(1))
MapType(keyType, valueType, true)
}
case jo: JObject =>
val jf = jo.obj
val sfs = jf.map {
case (name: String, ctpye: JValue) =>
StructField(name, jvalue2datatype(ctpye))
}
StructType(sfs)
case other: Any =>
throw new RuntimeException(s"Not JObject/JArray/JString, type:${other.getClass}")
}
}
}
利用json4s解析json的学习网站:
常用json4s数据类型:
sealed abstract class JValue
case object JNothing extends JValue // 'zero' for JValue
case object JNull extends JValue
case class JString(s: String) extends JValue
case class JDouble(num: Double) extends JValue
case class JDecimal(num: BigDecimal) extends JValue
case class JInt(num: BigInt) extends JValue
case class JLong(num: Long) extends JValue
case class JBool(value: Boolean) extends JValue
case class JObject(obj: List[JField]) extends JValue
case class JArray(arr: List[JValue]) extends JValue
type JField = (String, JValue)
4 附加
4.1 解析嵌套字典:
import scala.collection.mutable
val kafkaHudiMap = mutable.Map[String, AnyRef]()
for(data <- kafkaHudiList){
kafkaHudiMap += data._1 -> Map("savePath" -> data._2)
kafkaHudiMap += data._1 -> Map("tableName" -> data._3)
kafkaHudiMap += data._1 -> Map("recordkey" -> data._4)
kafkaHudiMap += data._1 -> Map("precombine" -> data._5)
kafkaHudiMap += data._1 -> Map("writeTableType" -> data._6)
kafkaHudiMap += data._1 -> Map("writeOperation" -> data._7)
}
val map1: Map[String, AnyRef] = kafkaHudiMap("spjk21.test_hudi.test16.output").asInstanceOf[Map[String, AnyRef]]
4.2 查询监控
交互式监控:使用streamingQuery.lastProgress和streamingQuery.status直接获取active查询的当前指标和状态,是用streamingQuery.recentProgress返回最后几个处理信息的数组。
非交互式监控:定义监听类继承SparkListener,并重写相关方法,将在查询启动和停止时以及在查询执行中获得回调。
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.{OutputMode, StreamingQueryListener}
import org.apache.spark.streaming.scheduler.StreamingListener
import spark.implicits._
spark.streams.addListener(new StreamingQueryListener {
override def onQueryStarted(event: StreamingQueryListener.QueryStartedEvent): Unit = {
println("Query started ! ")
}
override def onQueryProgress(event: StreamingQueryListener.QueryProgressEvent): Unit = {
println("event.progress.batchId ===========> "+event.progress.batchId)
println("event.progress.durationMs ===========> "+event.progress.durationMs)
println("event.progress.eventTime ===========> "+event.progress.eventTime)
println("event.progress.id ===========> "+event.progress.id)
println("event.progress.name ===========> "+event.progress.name)
println("event.progress.sink.json ===========> "+event.progress.sink.json)
println("event.progress.sources.length ===========> "+event.progress.sources.length)
println("event.progress.sources(0).description ===========> "+event.progress.sources(0).description)
println("event.progress.sources(0).inputRowsPerSecond ===========> "+event.progress.sources(0).inputRowsPerSecond)
println("event.progress.sources(0).numInputRows ===========> "+event.progress.sources(0).numInputRows)
println("event.progress.sources(0).startOffset ===========> "+event.progress.sources(0).startOffset)
println("event.progress.sources(0).processedRowsPerSecond ===========> "+event.progress.sources(0).processedRowsPerSecond)
println("event.progress.sources(0).endOffset ===========> "+event.progress.sources(0).endOffset)
println("event.progress.processedRowsPerSecond ===========> "+event.progress.processedRowsPerSecond)
println("event.progress.timestamp ===========> "+event.progress.timestamp)
println("event.progress.stateOperators.size ===========> "+event.progress.stateOperators.size)
println("event.progress.inputRowsPerSecond ===========> "+event.progress.inputRowsPerSecond)
}
override def onQueryTerminated(event: StreamingQueryListener.QueryTerminatedEvent): Unit = {
println("Query stopped ! ")
}
})
5 后续研究
- 1,解析schema.avsc生成DataType【可选,已用其他方式替代】
遗留代码
import java.io._
import org.apache.avro.Schema
import org.apache.spark.sql.types._
val schemaFilePath ="/software/member/config/schema.avsc"
val schemaAvro = new Schema.Parser().parse(new File(schemaFilePath))
val df = spark.read.format("avro").option("avroSchema", schemaAvro.toString).load("person.avro")
-
2,使用
spark.streams.addListener完善stream query的错误处理机制 -
3,spark和kafka参数调优
6 scala项目依赖
<properties>
<org.scala-lang.modules-version>1.3.0</org.scala-lang.modules-version>
<!-- <org.json4s-version>3.5.4</org.json4s-version>-->
<!-- <spark-version>2.4.7</spark-version>-->
<!-- <scala-version>2.11.12</scala-version>-->
<!-- <scala-compat-version>2.11</scala-compat-version>-->
<org.json4s-version>3.7.0-M2</org.json4s-version>
<spark-version>3.1.2</spark-version>
<scala-version>2.12.10</scala-version>
<scala-compat-version>2.12</scala-compat-version>
<hadoop-version>2.10.1</hadoop-version>
<hudi-version>0.8.0</hudi-version>
<mybatis.generator.configurationFile>${project.basedir}/src/main/resources/generatorConfig.xml
</mybatis.generator.configurationFile>
<mysql.version>8.0.13</mysql.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<codehaus-jackson.version>1.9.13</codehaus-jackson.version>
<jackson.version>2.9.7</jackson.version>
<minio.version>4.0.0</minio.version>
<spring.cloud.version>Greenwich.M3</spring.cloud.version>
<spring.boot.version>2.1.0.RELEASE</spring.boot.version>
<durid.version>1.1.16</durid.version>
<jjwt.version>0.7.0</jjwt.version>
</properties>
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata</artifactId>
<groupId>com.jiean</groupId>
<version>1.1.1</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>scalatest</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala-compat-version}</artifactId>
<version>${spark-version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala-compat-version}</artifactId>
<version>${spark-version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala-version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark-bundle_${scala-compat-version}</artifactId>
<version>${hudi-version}</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.11</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala-compat-version}</artifactId>
<version>${spark-version}</version>
</dependency>
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_${scala-compat-version}</artifactId>
<version>${org.json4s-version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-xml_${scala-compat-version}</artifactId>
<version>${org.scala-lang.modules-version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-scala_${scala-compat-version}</artifactId>
<version>2.10.3</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-parser-combinators_${scala-compat-version}</artifactId>
<version>1.1.2</version>
<exclusions>
<exclusion>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala-compat-version}</artifactId>
<version>${spark-version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
















 3101
3101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











