







Coda: An End-to-End Neural Program Decompiler
Conference: NeurIPS 2019
这篇文章提出了一个新的反编译框架Coda,分为code sketch generation 和 error correction两部分。在第一部分使用了Tree-LSTM,AST generation 和 Attention机制,第二部分使用了迭代式的纠错方法改正第一部分可能出现的错误。因为包含了指令类型感知型的Encoder和AST生成,所以Coda也可以容易地推广到在不同的硬件指令集体系结构(ISA)或PL中。
进制可执行文件的逆向工程是计算机安全领域的一个关键问题。一方面,恶意方可以从软件产品中恢复可解释的源代码以获取商业利益。另一方面,二进制反编译可用于代码漏洞分析和恶意软件检测。然而,有效的二进制反编译具有挑战。
传统的反编译器有以下主要局限性:
(i)它们只适用于特定的源-目标语言对,因此对新的语言任务会产生额外的开发成本;
(ii)它们的输出高级代码不能有效地保持输入二进制的正确功能;
(iii)它们的输出程序不捕捉输入的语义,并且反编译后的程序很难解释。
为了解决上述问题,这篇文章提出了Coda,一个end-to-end的代码反编译框架。
Coda将反编译任务分解为两个关键阶段:
- 首先Coda采用一个指令类型感知编码器和一个树解码器来生成一个抽象语法树(AST),并在代码草图生成阶段使用注意力机制
- 然后,Coda使用一个由一个集成神经误差预测器引导的迭代纠错机更新代码草图。
通过找到一个好的近似候选,然后将其修正为完美的,Coda实现了优于基线方法的性能。评估结果表明,Coda对未知二进制样本的平均程序恢复准确率为82%,而最先进的反编译器的准确率为0%。此外,Coda的性能优于Attention-based的序列到序列模型的幅度为70%的程序精度。我们的工作揭示了二进制可执行文件的脆弱性,并对软件开发的知识产权保护提出了新的威胁
简介
反编译(Decompilation)是将二进制可以执行文件翻译成相应的高级编程语言的过程。恶意攻击者还可以使用反编译器对商用现货(COTS)软件产品进行逆向工程(RE),并复制该产品以供非法使用。反编译是一项具有挑战性的任务,因为高级编程语言(PL)中的语义在编译过程中被删除。现有的反编译器是特定于语言的,在扩展到新的PLs时会产生巨大的工程开销。此外,它们不能保存目标高级PL中的语义信息,因此输出很难解释。
可以把反编译的过程看作是机器翻译的任务。基于seq2seq的模型也被大量用于翻译任务。代码反编译中的三个主要子程序:
- (i)从底层代码中基本块之间的连接中学习控制依赖;
- (ii)从寄存器使用和内存访问中学习数据依赖;
- (iii)学习目标PL的语法。
一个最直观的想法就是将底层代码直接翻译成高级代码。但这种情况并不适用于反编译,原因如下:
- 反编译器的输入是具有不同构造格式(例如,操作数的数目和类型)的结构化低级语句。将程序作为序列输入处理会忽略语句边界,从而破坏输入程序的模块化特性。
- Seq2Seq模型的输出程序捕获目标PL语法的概率较低,因为输出是在没有明确边界的情况下顺序生成的。
- 上述三个子例程在Seq2Seq模型中纠缠在一起,使得学习过程变得困难。
使用单个自动编码器很难实现完美的程序恢复,尤其是对于长程序。因此,Coda将反编译分解为两个连续的阶段:代码草图生成(code sketch generation)和迭代纠错(error correction)。通过找到一个好的近似程序,然后使用动态信息迭代地更新它,使其接近完美的解,Coda产生了比单相反编译器更好的性能。
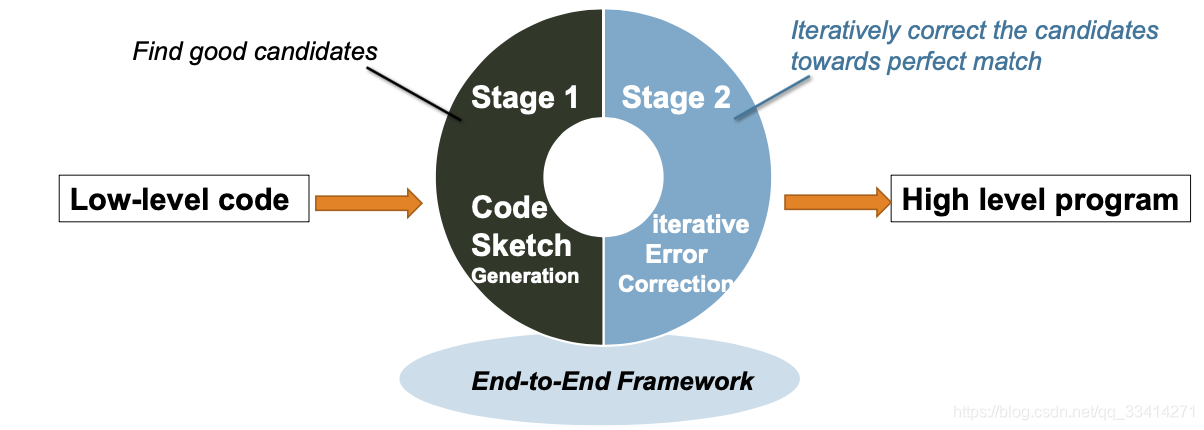
Contributions:
- 提出了第一个基于神经网络的反编译框架,该框架维护了目标高级代码的语义和功能
- 结合各种设计原则以促进反编译任务。更具体地说,Coda部署了指令类型感知编码器、AST树解码器、注意反馈、利用静态语法和动态信息的迭代纠错
- 实现高效的端到端反编译器设计。Coda可以很容易地推广到在不同的硬件指令集体系结构(ISA)或PL中重新执行,而工程开销可以忽略不计。
- 证实了Coda的普遍适用性和优越的性能在各种综合基准和现实世界的应用。
程序的反编译问题
背景及挑战
现代软件开发包括以下步骤:高级编程、代码编译、将获得的二进制文件部署到相关硬件。在执行期间,在硬件上执行一系列指令。有三种主要的指令类型,即内存、算术和分支操作。不同的指令类型具有不同的指令字段(instruction field),表示不同的操作数类型和数目。
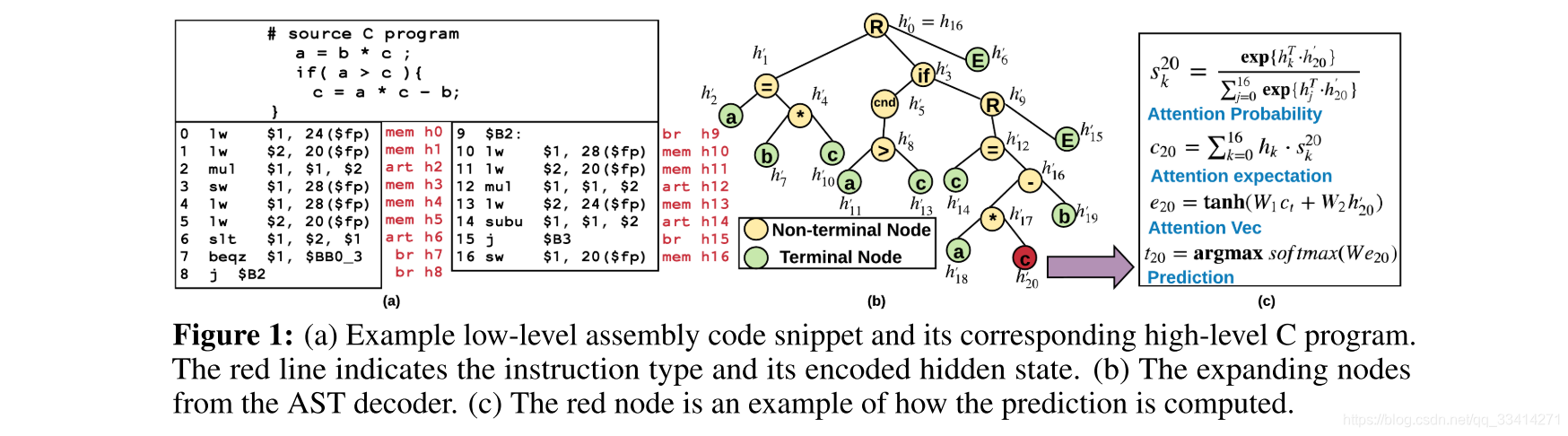
上图(a)显示了高级代码片段和相应的低级代码的示例。第0行是一条内存指令,它从寄存器$fp和24计算出的内存地址将一个字提取到寄存器$1中。第3行是一个算术运算,它将存储在$1和$2中的值相乘。第8行表示需要一个操作数而不是三个操作数的无条件分支。lw、mul、j是指令的操作码。程序反编译具有挑战性,因为在低级别程序中存在两种类型的依赖关系,反编译器应该保留这些依赖关系。
- Intra-statement dependency:根据低级ISA的语法要求,每条指令对操作数都有严格的结构限制。例如,在指令lw $2, 8$(fp)中,第一个和第三个操作数表示寄存器,而第二个操作数是瞬时值。
- Inter-statement dependency:除了单个指令中的约束之外,控制流和数据依赖性还存在于多个指令之间。例如,第2行和第3行具有数据依赖性,因为mul操作需要从加载目标寄存器中消耗该值。
问题定义
反编译的定义:设 P P P表示高级语言中的任意程序, Γ \Gamma Γ表示编译器。给出一个底层低级代码 ϕ = Γ ( P ) \phi = \Gamma (P) ϕ=Γ(P) ,反编译的任务是开发一个反编译器 Γ − 1 \Gamma^{-1} Γ−1,使其可以满足 Γ ( P ) = Γ ( P ′ ) \Gamma (P) = \Gamma (P^{'}) Γ(P)=Γ(P′),其中 P ′ = Γ − 1 ( ϕ ) P^{'}=\Gamma^{-1} (\phi) P′=Γ−1(ϕ)。
我们观察到,传统的反编译器(如RetDec或Hex-ray)只针对在反编译期间维护二进制代码的功能。
Coda通过恢复一个具有正确功能和语义的高级程序来解决上述限制。此外,我们确定了高级程序的两种类型的约束,可以用来验证反编译器输出的正确性
- Input-output Behavior Constraint: 给出一系列输入输出对 { ( I k , O k ) } k = 1 K \{(I^k,O^k)\}_{k=1}^K {(Ik,Ok)}k=1K,其中 O k = ϕ ( I k ) O^k=\phi (I^k) Ok=ϕ(Ik)是通过执行低级程序 ϕ \phi ϕ获得的。反编译器应输出程序 P ′ P^{'} P′以至于对于每个 k k k而言 ϕ ′ ( I k ) = O k \phi^{'}(I^k)=O^k ϕ′(Ik)=Ok,其中 ϕ ′ = Γ ( P ′ ) \phi^{'} = \Gamma (P^{'}) ϕ′=Γ(P′)。简而言之就是输出为执行低级程序而来的,那么反编译后再编译,然后再执行相应的低级程序应该能得到同样的输出。
- Compilation Matching Constraint: 在相同的编译器配置下,正确恢复的程序 ϕ ′ \phi^{'} ϕ′的编译结果与输入的低级代码 ϕ \phi ϕ之间的理想LD(Levenshtein edit distance)为零。
威胁模型
假设攻击者拥有以下信息:(i) 用于生成输入程序的编译器配置;(ii)高级代码中包含的静态/动态库接口;(iii)相关硬件的反汇编程序。使用二进制分析技术可以很容易地获得上述信息。本文的的目标是重新设计一个高级程序,作为源高级程序来描述正确的计算图(控制和数据依赖),并保留语义信息和功能。重构数据类型、寻找二进制函数入口点或重构有意义的变量名是前人研究的不同方向。
Coda

上图展示Coda的基本框架,根据虚线可以分为2部分,上面为草稿基本生成,下面是错误纠正。
Code Sketch Generation
Encoder以反汇编程序(disassembler)生成的汇编程序为输入,输出一个可等价转换为高级程序的AST。
- 指令类型感知程序编码: 使用N元Tree-LSTM作为输入编码器来处理不同的指令类型,即内存、算术和分支。
- 生成AST的树解码器
- attention 机制
Iterative Error Correction
代码草图生成阶段的输出AST可能包含预测错误。因此,这篇文章构造了一个误差预测器(EP)和一个迭代误差校正机(EC-machine)

在纠错过程的每一次迭代中,Coda首先纠正一个错误,并通过检查编译后的代码草图和上述基本事实之间的LD来验证生成的高级代码草图。
实验
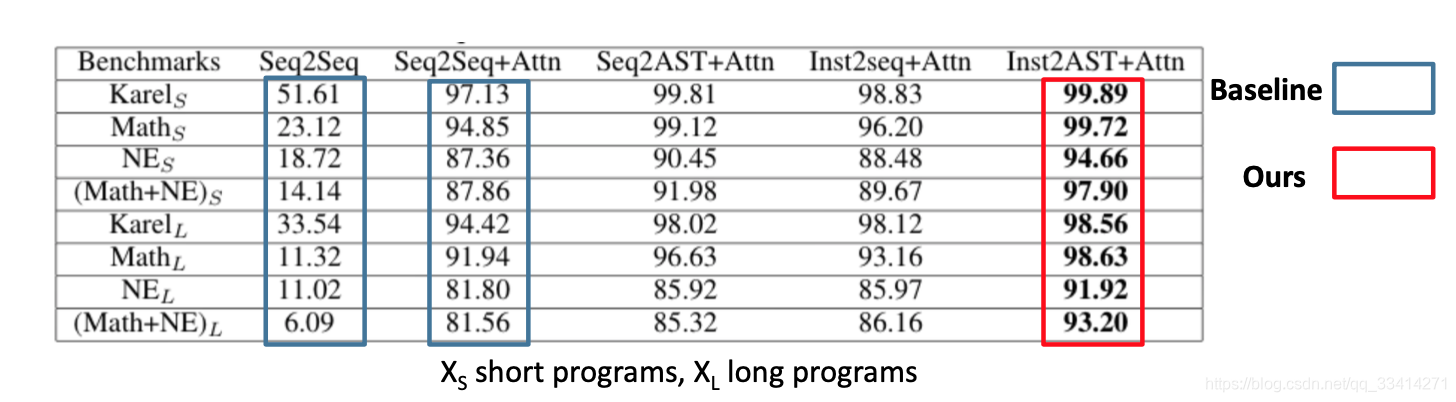
第一阶段代码草图生成的性能:
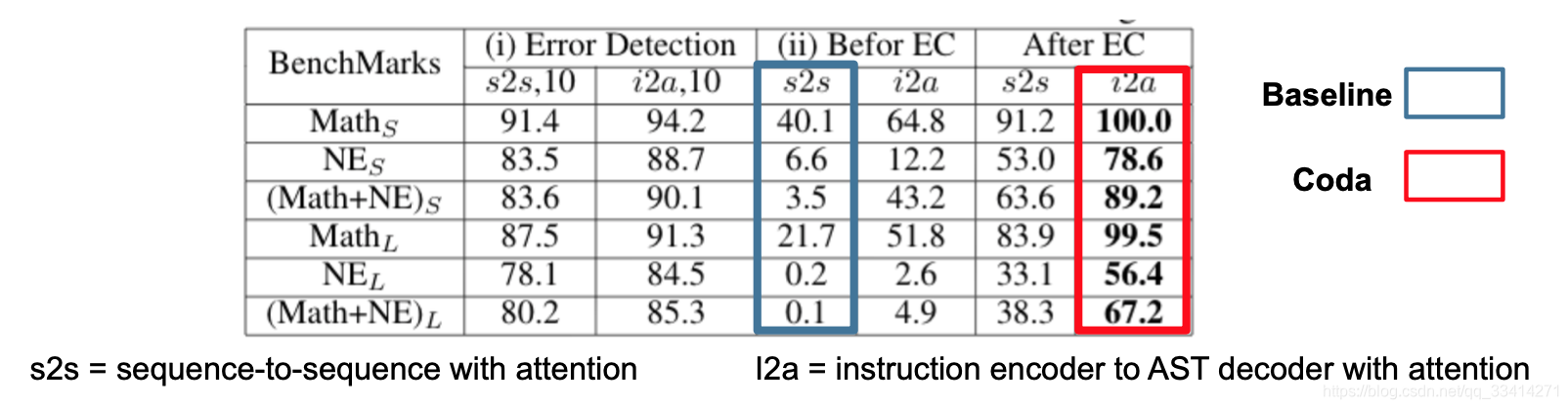
第二阶段纠错的性能:

















 2658
2658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









