




一、前言

SWE-BENCH: CAN LANGUAGE MODELS RESOLVE
REAL-WORLD GITHUB ISSUES?
几乎是现在软件工程领域最流行的项目工程级别评测集。发布在ICLR 2024.
- 官网: https://www.swebench.com/original.html
- paper:https://arxiv.org/pdf/2310.06770
- repo:https://github.com/SWE-bench/SWE-bench
- dataset:https://huggingface.co/datasets/SWE-bench/SWE-bench
二、SWE-Bench

很多数据集都只停留在简单的模型的一次输入推理,几行代码即可完成任务,通过ut来评测,实际工作中,这种场景非常少,大部分都是项目级别的工作,SWE即是如此。
2.1 数据构成方式

-
仓库选择和数据抓取:抓取12个流行的开源Python仓库的PR,总共产生了约90,000个PRs
-
基于属性的过滤:选择最终有以下两种特性merged的pr,(1)解决了问题 (2)对仓库测试文件进行修改,表明用测试来验证是否解决了问题
-
基于执行的过滤:对于每个任务进行执行,并记录应用PR前后的结果(PR之前的测试结果和应用了PR中代码后的测试结果), 过滤掉不存在fail->pass的任务,即保留了至少存在一个因为PR的merge,test从原本的failed到pass。
最终剩下2294的task,每个task就是一个样本。
2.2 数据仓库分布
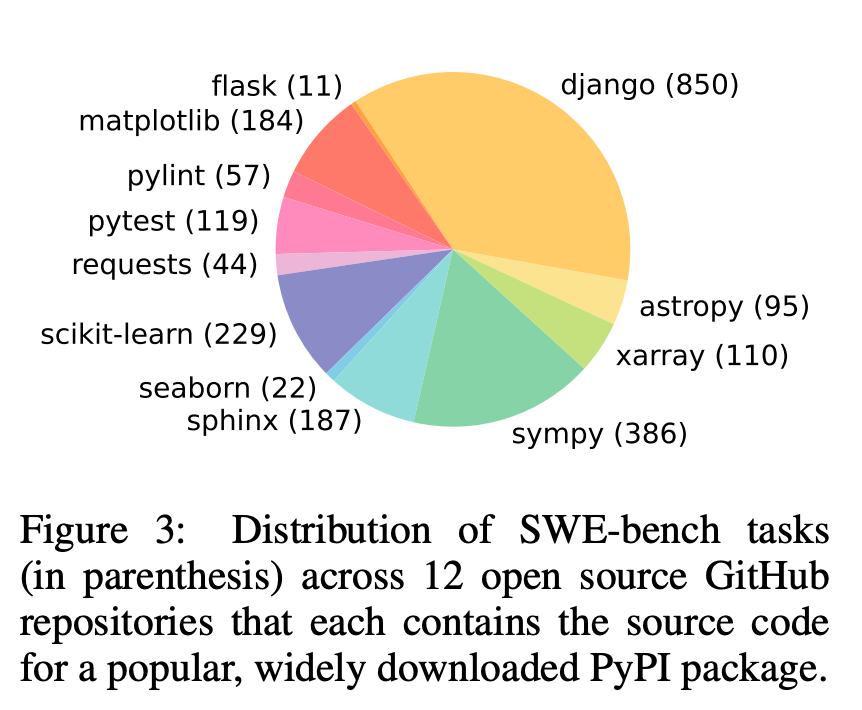
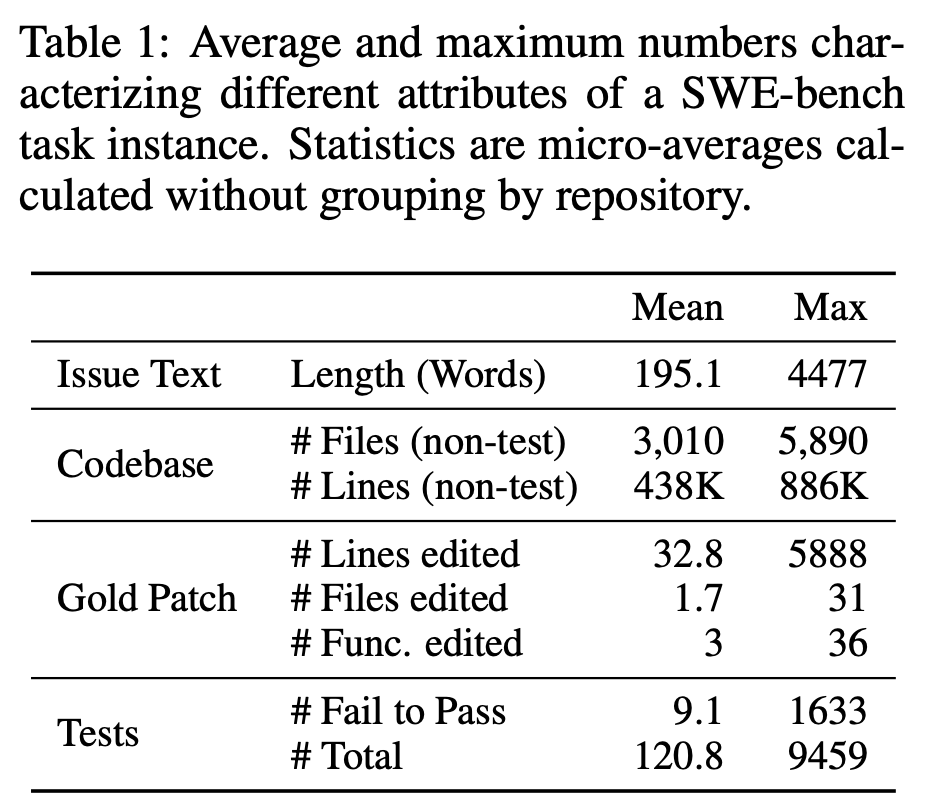
2.3 各维度的变化
文件、函数、行数变化
2.4 开源数据集
https://huggingface.co/datasets/SWE-bench/SWE-bench
{
"instance_id": "owner__repo-pr_number",
"repo": "owner/repo",
"issue_id": issue_number,
"base_commit": "commit_hash",
"problem_statement": "Issue description...",
"version": "Repository package version",
"issue_url": "GitHub issue URL",
"pr_url": "GitHub pull request URL",
"patch": "Gold solution patch (don't look at this if you're trying to solve the problem)",
"test_patch": "Test patch",
"created_at": "Date of creation",
"FAIL_TO_PASS": "Fail to pass test cases",
"PASS_TO_PASS": "Pass test cases"
}
- problem_statement为给模型的description
- patch为gold soluton diff patch, 即groundtruth
- test patch,为项目中ut程序的diff patch,通过这个来判断哪些是此次PR中更改的ut,哪些ut是FAIL_TO_PASS等
其中PASS_TO_PASS为PR前后都为pass的ut,FAIL_TO_PASS为PR前后从fail到pass的ut,前者check其他功能正常,后者check补丁是否正确。
三、SWE-Bench各个版本
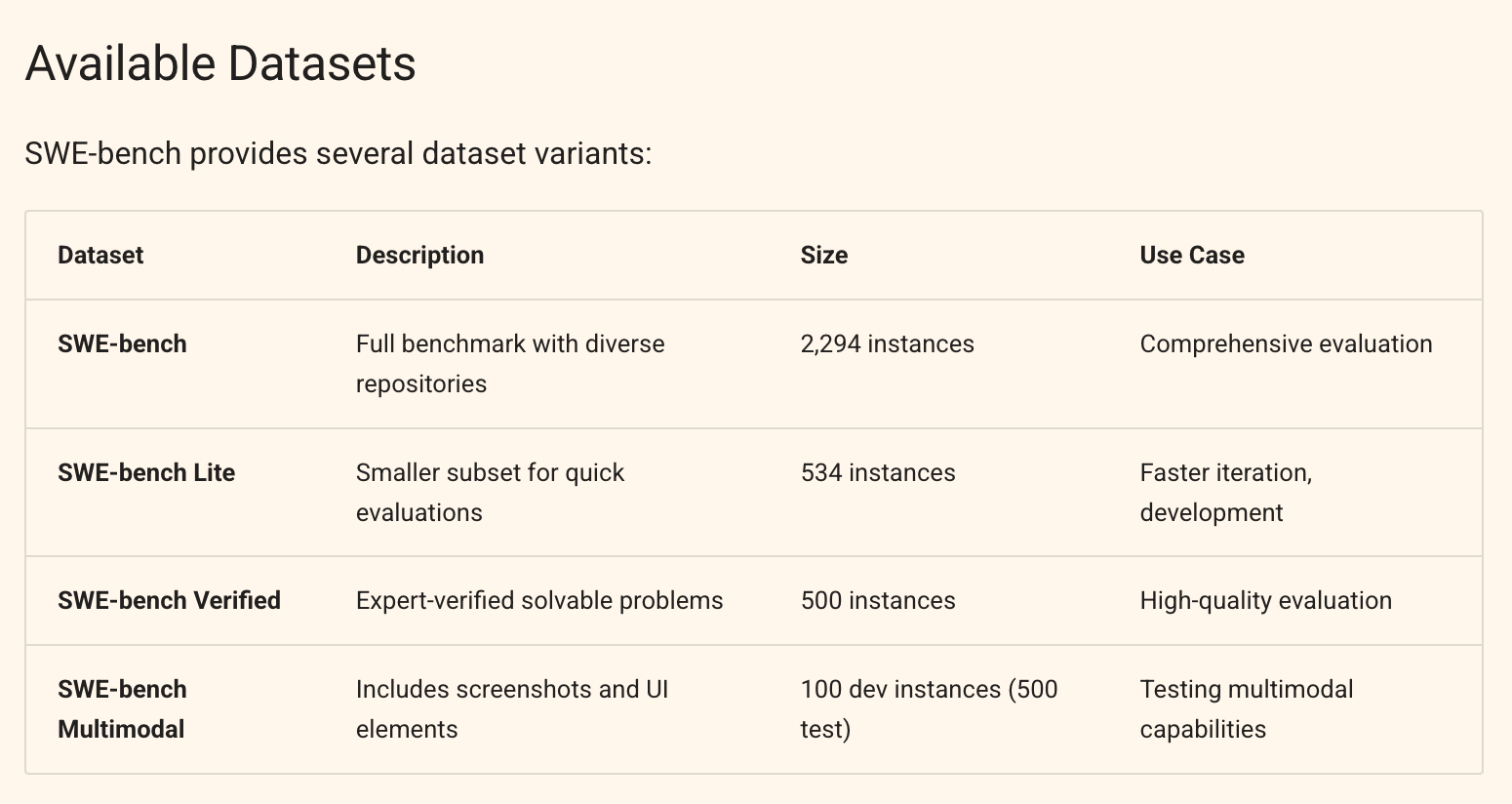
- 全部数据 2294条
- 轻量数据 其中采样534条
- 和OpenAI一同人工verified的高质量数据 500条 :https://openai.com/index/introducing-swe-bench-verified/
- 多模态评测数据

















 5162
5162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









