









1.概述
上文讲述了链路追踪的基础知识以及整合Sleuth+Zipkin+MySQL将链路追踪数据存储到了MySQL,但在实际的生产环境中,一般不会直接存储到MySQL,因为服务数量较多,链路调用较为复杂,会在短时间内产生大量日志,直接存入MySQL会存在性能问题。面对庞大的日志数量存储问题,现在比较成熟的处理方式是存储到数据库(mongoDB、ELK等)或文件中,且要与正在运行的系统环境分离。本文将演示将链路追踪数据利用消息中间件Kafka实现数据稳定输入到Logstash之中。
2.链路数据存储
本文展示的是将链路追踪数据存入到Kafka,进而转存到Logstash之中。主要的架构图如下所示:
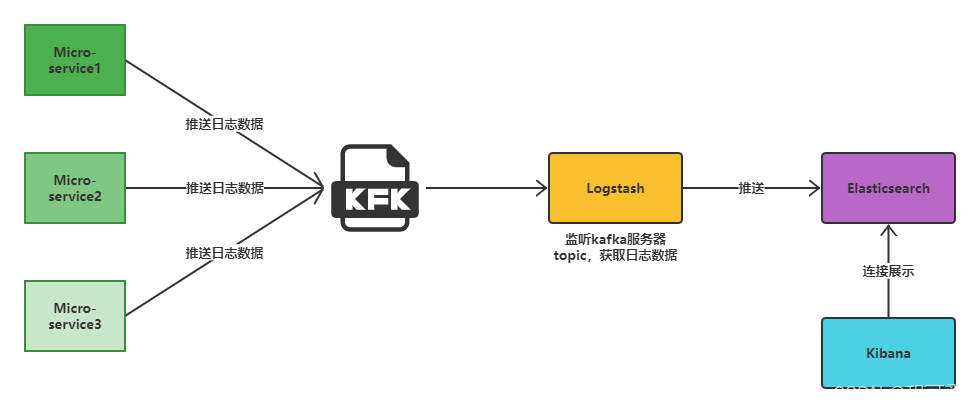
业务服务包括Micro-service1、Micro-service2和Micro-service3,这三个服务配置zipkin的地址以及发送链路追踪数据的方式为Kafka,配置成功且服务启动成功后,若服务内发生调用,则会推送链路追踪数据到Kafka。logstash配置文件中配置了监听指定服务器指定topic的数据(这个topic也就是我们存放链路数据的topic),logstash会获取topic内的日志信息,并按照指定格式过滤,然后推送到Elasticsearch,最后结合Kibana可以对Elasticsearch的链路数据进行可视化展示。
首先需要安装Kafka、Logstash,安装Logstash的同时建议安装Elasticsearch+Kibana,方便搜索查看日志信息。由于本文只做演示,因此安装了单机版的Kafka,安装教程可查看我之前的博客:Kafka从入门到放弃之CentOS中安装并配置Kafka。ELK(Elasticsearch+Logstash+Kibana)的安装可以查看下面的参考文献1,环境版本可根据自己需要进行选择,我这里安装的是6.8.19版本。
注意:Elasticsearch+Logstash+Kibana三个的版本需要一致,否则可能会出现异常。
2.1 配置变更
zipkin本身支持使用Kafka来收集链路追踪数据,因此在上文的环境中,只需修改部分配置文件即可,配置文件变更部分如下:
spring.zipkin.base-url=http://192.168.228.130:9411/
#链路数据发送方式(Kafka、RabbitMQ、Web、activeMQ)web表示采用http请求发送
spring.zipkin.sender.type=kafka
spring.zipkin.kafka.topic=zipkin
#数据采集样本率(1.0表示所有请求都采集)
spring.sleuth.sampler.probability=1.0
#kafka配置(你Kafka安装配置的地址)
spring.kafka.bootstrap-servers=192.168.228.130:9092
#消息发送失败重试次数
spring.kafka.producer.retries=3
#earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
#latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
#none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
spring.kafka.consumer.auto-offset-reset=latest
2.1 Kafka
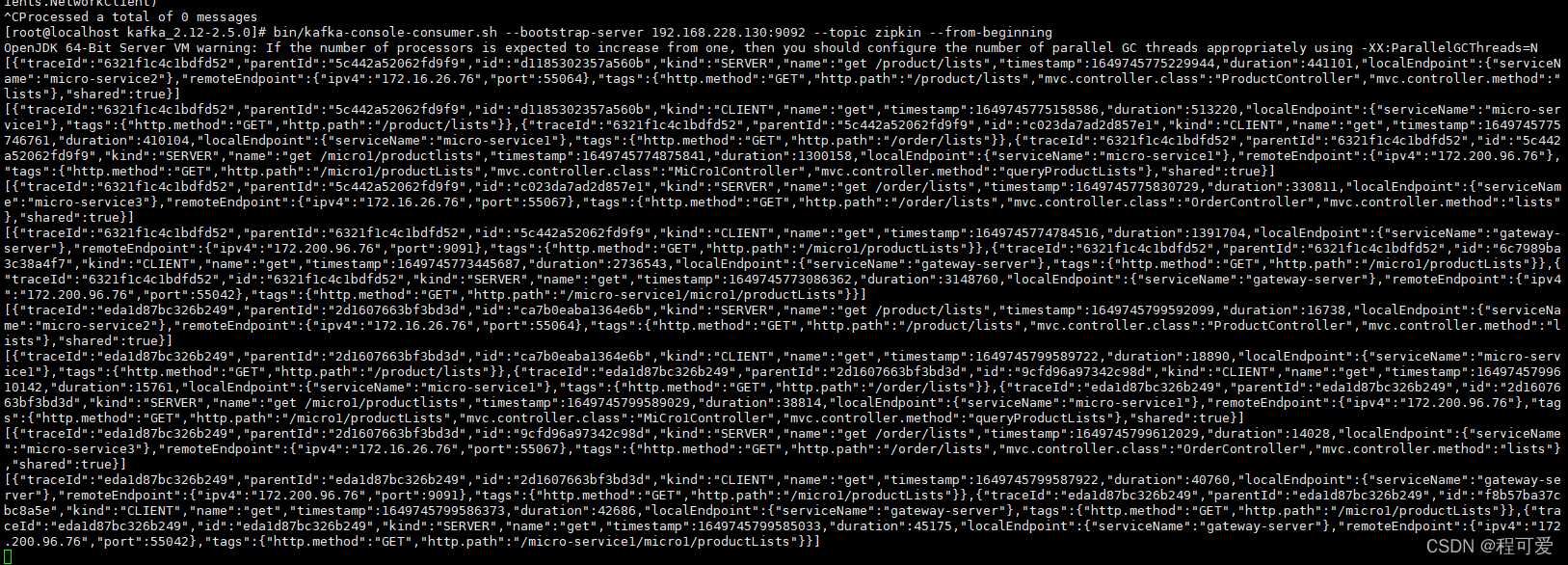
kafka和ELK的单机环境均安装成功之后,先启动Kafka,同时启动我们编写的测试服务,此时会有日志信息存储到Kafka中,可以利用如下指令查看Kafka指定topic下的实时消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic zipkin --from-beginning
执行成功之后可以看到下图内容:
2.2 Logstash
由于logstash需要从kafka中读取数据,因此需要进行配置。在logstash的安装目录下,找到config文件夹,新增配置文件logstash_from_kafka.conf,具体配置内容如下:
input {
kafka {
#kafka安装地址和端口
bootstrap_servers => "192.168.228.130:9092"
group_id => "zipkin"
#kafka链路追踪的topic
topics => ["zipkin"]
decorate_events => true
codec => json
}
}
filter {
ruby {
code => "event.set('timestamp',event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ['timestamp']
}
}
output {
elasticsearch {
hosts => ["192.168.228.130:9200"]
index => "kafkalog"
}
}
上述配置文件的主要作用是从kafka读取topic为zipkin的链路追踪数据,filter中配置是对日志内容进行了一个时间戳转换,转化为亚太地区时间,output中配置了日志输出路径,输出到elasticsearch,index为kafkalog。
logstash的启动命令如下:
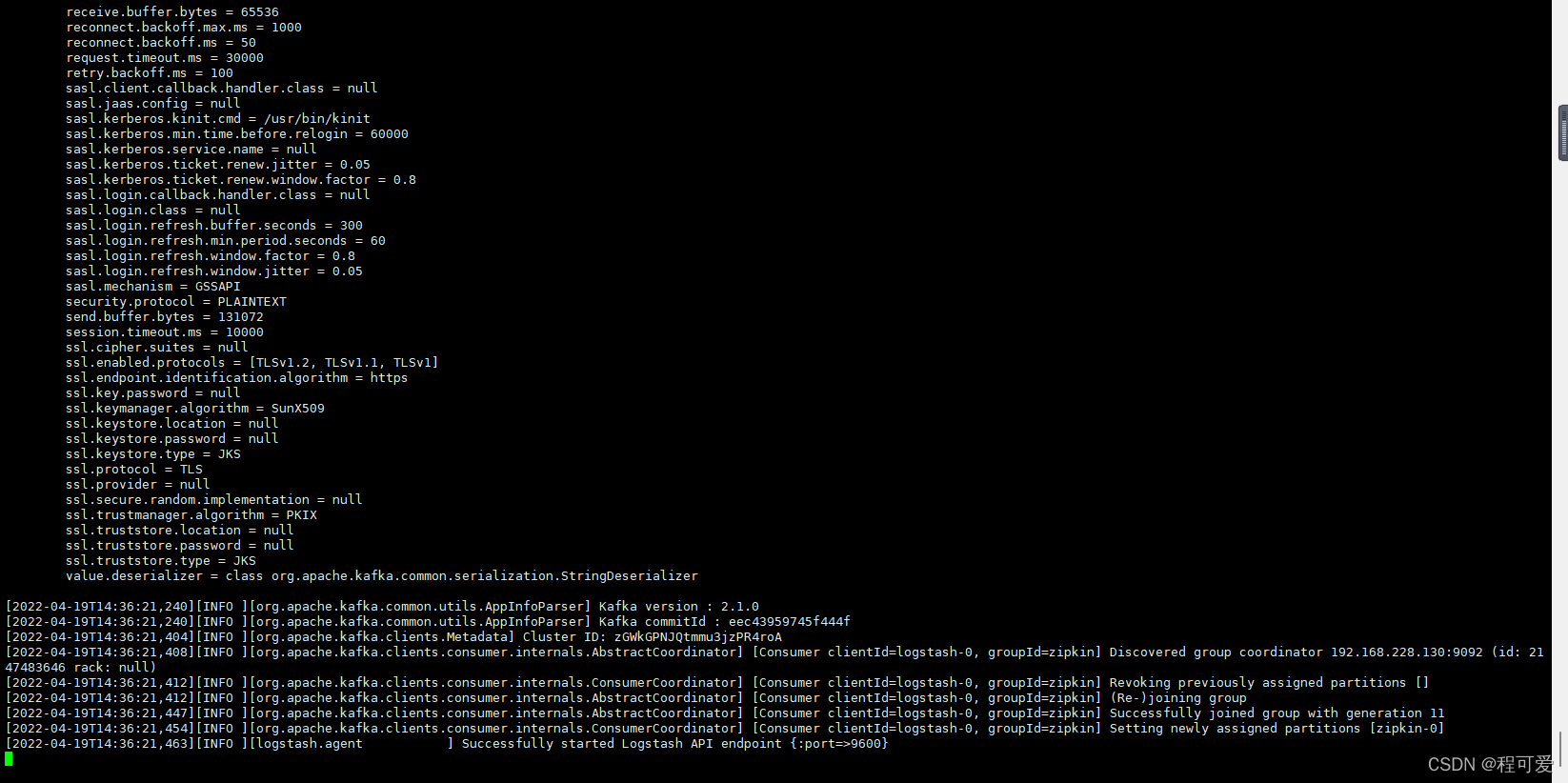
nohup ./bin/logstash -f ./config/logstash_from_kafka.conf &
logstash启动成功后如下图所示:
2.3 Kibana查看数据
利用上述查看实时消息的指令,可以看到链路追踪数据被不断写入Kafka,部分消息截图如下:
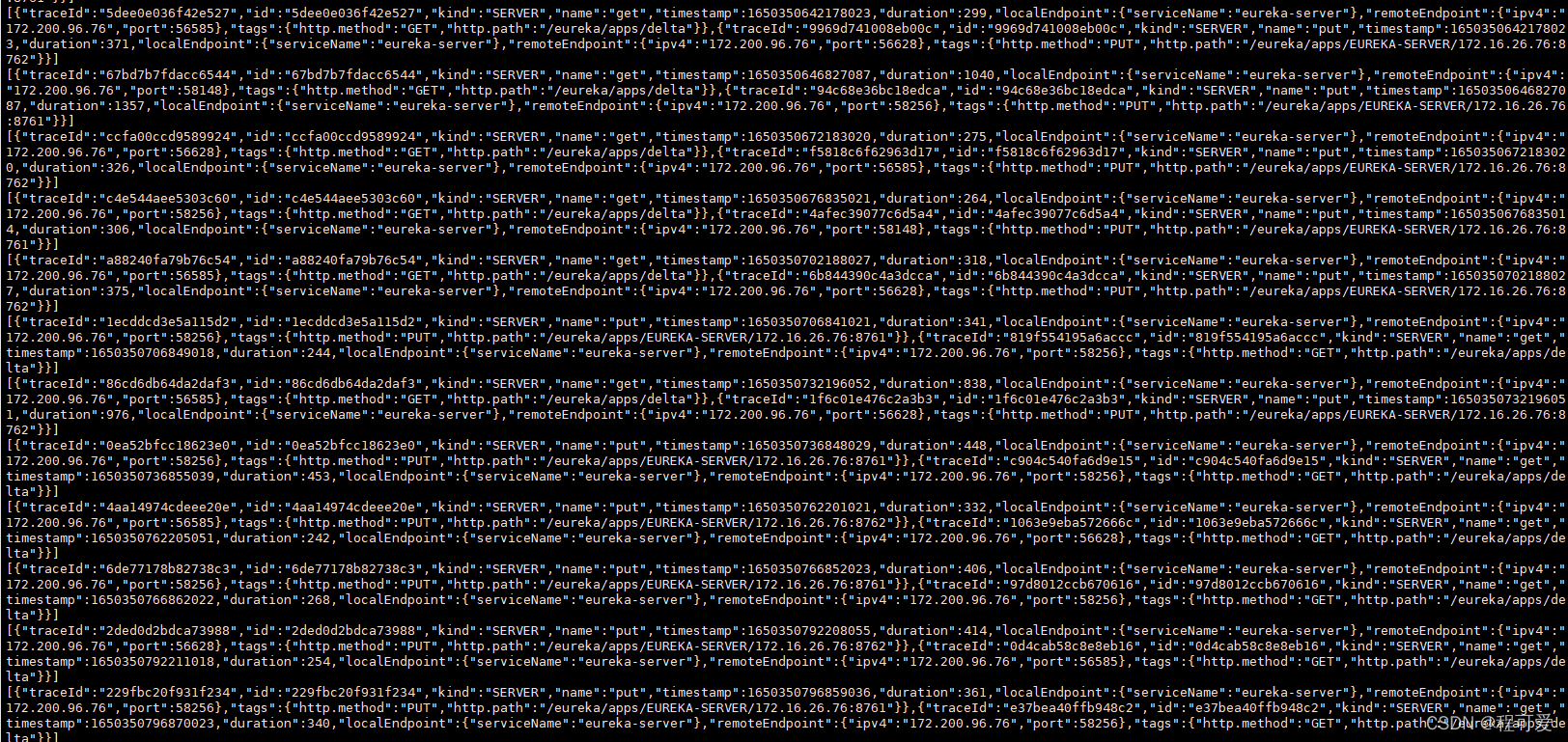
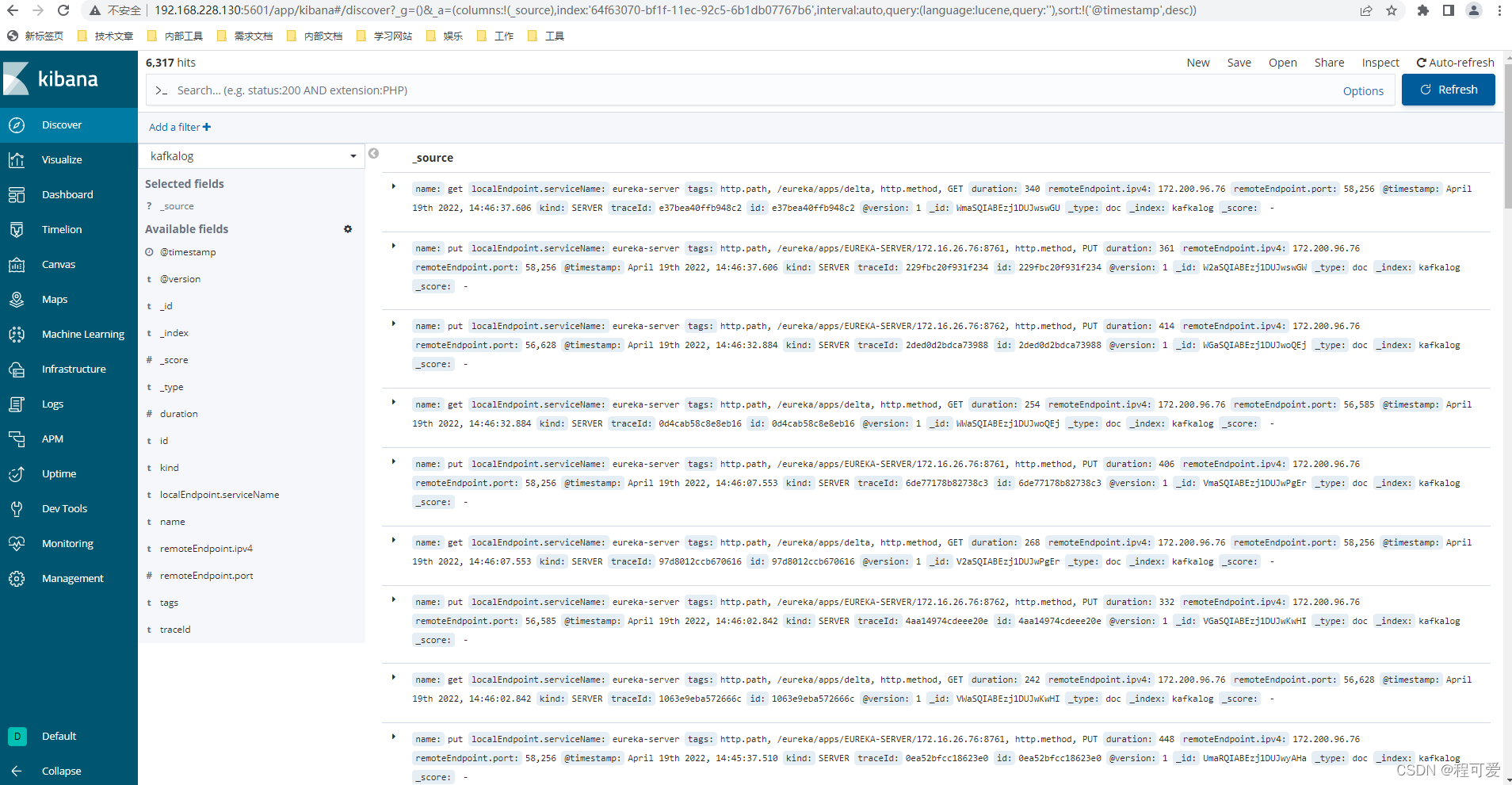
logstash从Kafka中读取数据,在kibana中的显示如下图所示:
3.小结
1.ELK安装时,版本需要保持一致;
2.在配置链路追踪数据输出到Kafka时,需要将配置Kafka地址及topic等信息,默认topic为zipkin;
3.kibana在关联Logstash时,需要先在management目录下进行index的关联;
4.本文测试代码见附录。
4.参考文献
1.https://www.jianshu.com/p/4304e60353f4
2.https://www.bilibili.com/video/BV1tB4y1A7iA
5.附录
1.https://gitee.com/Marinc/spring-boot-sleuth-zipkin.git














 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









