






一、数字视频压缩的必要性和可能性
视频信号数字化后的庞大数据量给存储和传输带来了巨大的压力,单纯用扩大存储容量、增加通信带宽是高成本且不现实的,而数据压缩是个行之有效的办法。
数据压缩的理论基础是信息论,压缩就是去掉数据中的冗余,保留不确定的信息,去掉确定的(可推知的)信息。数字图像和视频数据中存在大量数据冗余和主观视觉冗余,因此,数字视频压缩是非常有必要且有可能的。一般情况存在以下几种形式的冗余:
(1)空间冗余
空间冗余是一种与像素间相关性直接联系的冗余。相邻像素的亮度和色度信号值接近,有强相关性,若直接利用采样数据来表示亮度和色度信号,则会存在较多的空间冗余。一般可以用帧内编码来使表示每个像素的平均比特数下降,减少空间冗余进行数据压缩。
(2)时间冗余
视频序列图像相邻帧时间间隔小,且运动物体具有运动一致性,使得视频序列图像间存在很强的相关性。通常采用运动估值和运动补偿预测技术来消除时间冗余。
(3)统计冗余
统计冗余也可称为编码表示冗余或符号冗余。由于实际图像数据很难得到其信息熵,若用相同比特数表示每个像素则会产生冗余,因此如果采用可变长熵编码技术,对出现概率大的符号用短码表示,对出现概率小的用长码表示,则可以节约码字,去除符号冗余。
(4)视觉冗余
人眼对亮度信号比色度信号敏感,对低频信号比高频信号敏感(即对边沿或突变附近的细节不敏感),对静止图像比对运动图像敏感,对图像水平线条或垂直线条比对斜线敏感。这些就是视觉冗余,压缩视觉冗余的核心思想就是去掉人眼看不到的或可有可无的图像数据,如DCT变换和高压缩比预测帧和双向预测帧的采用。
(5)其他冗余
包括图像区域相似纹理结构或存在某种关系的结果冗余和包含先验知识信息编码对象的知识冗余。
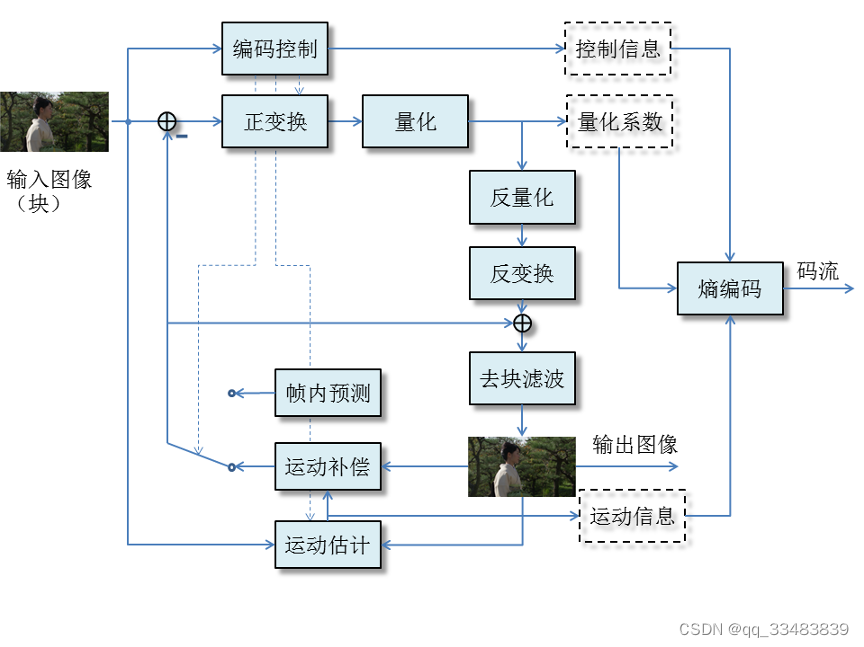
二、数字视频压缩的混合编码框架
视频压缩的混合编码框架如下图所示,其中,基于运动估计/运动补偿的帧间预测用于去除视频序列的时间冗余,基于方向插值的帧内预测用于去除帧内空间冗余,去块滤波用于进一步去除预测编码后残差中保留的空间冗余,最后熵编码模块用于去除前面步骤生成数据的统计冗余。这篇博客重点介绍包括帧内预测和帧间预测的预测编码。
1、关键帧,I帧(帧内压缩技术)
举个例子,如果你用摄像头对着一棵树来拍摄,1秒钟之内实际很少有大幅度的变化。而摄像机一般一秒钟会抓取几十帧的数据。I帧一般都是一组帧的第一帧,I帧需要完整的保存下来,如果没有I帧,完成不了后面解码数据,所以完整的I帧至关重要。
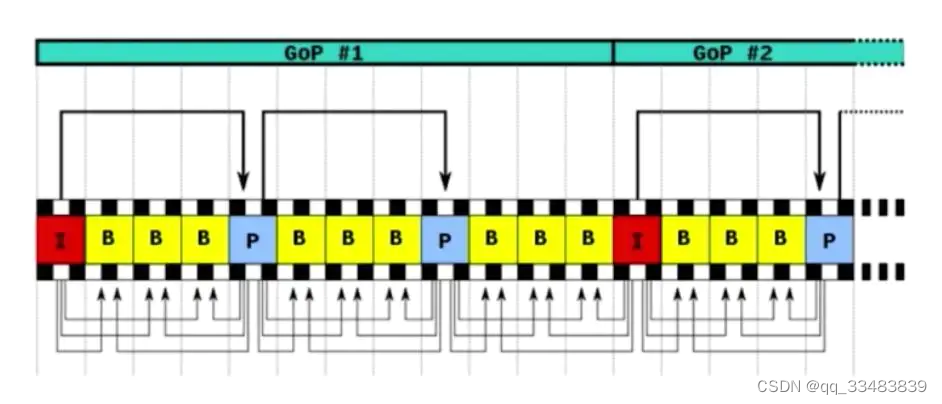
2、向前参考帧,P帧(只参考前一个帧,帧间压缩技术)
视频的第一帧会被作为关键帧I帧完整保存下来,而第二帧依赖于第一个帧,后面的帧也都会依赖前一帧,后面所有的帧只存储于前一帧的差异,大大减少了数据量,提高了压缩率。
3、双向参考帧,B帧(同时参考前一帧和后一帧,帧间压缩技术)
B帧,即参考前一帧,也参考后一帧。B帧的数量越多,压缩率就越高。但是如果是实时互动的直播,一般不会使用B帧,因为B帧参考后一帧需要等待,影响解码速度,且容易丢包。如果我们对实时性的要求不高,就可以使用更多数量的B帧。
4、一组帧,GOF(Group of Frame)
一组帧是从一个I帧到下一个I帧。这一组的数据也包括B帧/P帧,也称为GOF,如下图所示。如果在一秒钟内,有60帧画面,这60帧可以成一组。如果镜头在一分钟之内都没有发生大的变化,那也可以把这一分钟内所有的帧画做一组。
三、预测编码
(一)帧内预测编码
帧内预测技术利用当前帧中已经编码的像素的线性组合来作为当前像素的预测值。目前主流的基于方向的帧内预测技术,主要利用当前块与周围块纹理方向上的相关性(当前编码图像的各个像素值从左上位置到右下位置存在某种内在连续性),根据预测方向上已重建的空间相邻块边界像素值来获取当前编码块的预测像素值,即基于某个方向插值出当前块的预测块。不同视频帧的纹理和内容也不一致,因此需要根据编码块的图像内容自适应获取不同的预测方式,选择出其预测像素值的参考方向的像素,从而获取编码块的最佳压缩性能。
(二)帧间预测编码
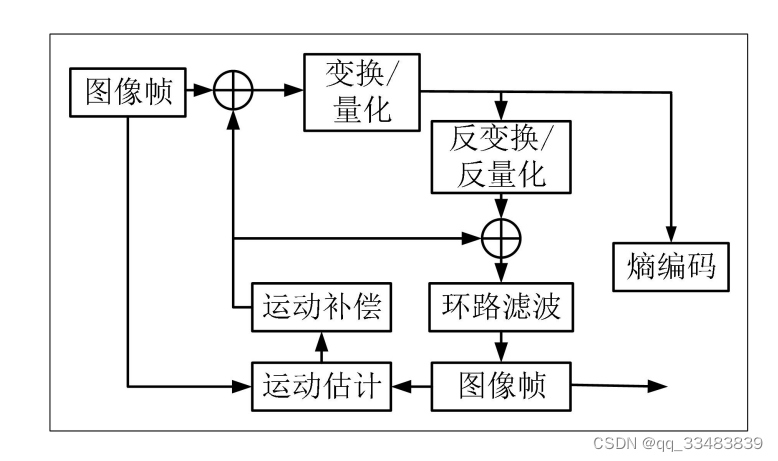
帧间预测是压缩图像的常用方法,根据帧图像与邻域之间的相关性,来消除自身的冗余信息。编码器发送端在传输具有较强时域关系的视频序列时,无需传输所有视频图像信息,仅向解码器接收端传送数据的运动矢量即可,它能通过物体运动数据和参考帧数据,还原当前图像。帧间预测的编码流程如下图所示。
1、运动补偿
一个视频序列包含一定数量的图片,通常称为帧。相邻的图片通常很相似,也就是说,包含了很多冗余。使用运动补偿的目的是通过消除冗余,提高压缩比。运动补偿包括全局运动补偿和分块运动补偿,它利用前面帧的局部区域图像来预测和补偿当前帧的局部区域图像,可以有效减少帧序列的冗余信息。
运动补偿通过描述前面帧(表示在编码关系上的前帧,在播放顺序上不一定在当前帧前)的区域块移动到当前帧中的某位置的方式和差别,可以减少视频序列中的空域冗余,也可以用来进行去交织(deinterlacing)操作。
最早的运动补偿的设计只是简单的从当前帧中减去参考帧,从而得到通常含有较少能量(或者成为信息)的"残差",从而可以用较低的码率进行编码。后来稍微复杂一点的设计是估计一下整帧场景的移动和场景中物体的移动,并将这些运动通过一定的参数编码到码流中去。这样预测帧上的像素值就是由参考帧上具有一定位移的相应像素值而生成的。这样的方法比简单的相减可以获得能量更小的残差,从而获得更好的压缩比。
运动补偿的基本原理是,当编码器对图像序列中的第N帧进行处理时,利用运动估值ME(Motion Estimation)方法,得到第N帧得预测帧N´。在实际编码传输时,传输第N帧和其预测帧N´差值△。如果运动估计十分有效,△中得概率基本上分布在零附近,△比原始图像第N帧的能量小得多,编码传输△所需得比特数也就大大减少。
运动补偿的步骤如下:
- 将图像分割为静止和运动的两部分,估计出物体的位移矢量(平行位移值)。
- 按照估计得到的位移矢量获取得到前一帧的图像数据。
- 通过使用预测滤波器,得到前一帧图像数据的预测像素。
(1)I帧、P帧、B帧的运动补偿
通常,图像帧每组的第一帧在编码的时候不使用运动估计的办法,这种帧称为帧内编码帧(Intra frame)或者I帧。该组中的其它帧使用帧间编码帧(Inter frame),通常是P帧。这种编码方式通常被称为IPPPP,表示编码的时候第一帧是I帧,其它帧是P帧。
在进行预测的时候,不仅可以从过去的帧来预测当前帧,还可以使用未来的帧来预测当前帧。当然在编码的时候,未来的帧必须比当前帧更早的编码,也就是说,编码的顺序和播放的顺序是不同的。通常这样的当前帧是使用过去和未来的I帧或者P帧同时进行预测,被称为双向预测帧,即B帧。这种编码方式的编码顺序的一个例子为 IBBPBBPBBPBB。
(2) 全局运动补偿
在全局运动补偿中,运动模型基本上就是反映相机的平移,旋转,变焦运动等。该模型适合没有运动物体的静止场景的编码。全局运动补偿的优点如下:
- 使用少数参数描述全局运动,参数所占用的码率基本上可以忽略不计。
- 对帧进行分区编码,避免了分区造成的块效应。
- 在时间方向具有连续性,在时间方向的一条直线的点如果在空间方向具有相等的间隔,就对应了在实际空间中连续移动的点。而其它的运动估计算法通常会在时间方向引入非连续性。
但缺点是,如果场景中存在运动物体,全局运动补偿就不适用了。
(3)分块运动补偿
在分块运动补偿中,每帧图像被分为若干像素块 。根据参考帧某个固定位置同等大小的像素块对当前像素块进行预测,预测过程中只有平移的运动矢量。对分块运动补偿来说,运动矢量必须加入码流中一起编码。由于运动矢量之间具有相关性,(例如同一个物体相邻两个像素块运动的相关性很大),通常使用差分编码在相邻的运动矢量编码之前对其作差,只对差分的部分进行编码。
运动矢量的值可以是非整数的,此时的运动补偿被称为亚像素精度的运动补偿。这是通过对参考帧像素值进行亚像素级插值,而后进行运动补偿做到的。最简单的亚像素精度运动补偿使用半像素精度,也有使用1/4像素和1/8像素精度的运动补偿算法。更高的亚像素精度可以提高运动补偿的精确度,但是大量的插值操作会大大增加了计算复杂度。
分块运动补偿的一个大缺点在于在块之间引入的非连续性,通常称为块效应。当块效应严重时,解码图像看起来会有像马赛克一样的效果,严重影响视觉质量。另外一个缺点是,当高频分量较大时,会引起振铃效应。
2、运动估值
运动估值的基本思想是将图像序列的每一帧分成许多互不重叠的宏块,并认为宏块内所有像素的位移量都相同,然后对每个宏块到参考帧某一给定特定搜索范围内根据一定的匹配准则找出与当前块最相似的块,即匹配块,匹配块与当前块的相对位移即为运动矢量。视频压缩的时候,只需保存运动矢量和残差数据就可以完全恢复出当前块。得到运动矢量的过程被称为运动估计。
运动估值技术主要分为两大类:像素递归法和块匹配算法(BMA)。
像素递归法根据像素间亮度的变化和梯度,通过递归修正的方法来估计每个像素的运动矢量。每个像素都有一个运动失量与之对应。为了提高压缩比,不可能将所有的运动矢量都进行编码传输到接收端,但为了进行帧间运动补偿,在接收端解码每个像素时又必须有这些运动矢量。解决这个矛盾的办法是让接收端在与发送端同样的条件下,用与发送端相同的方法进行运动估值。由于此时只利用已解码的信息,因此,无须传送运动矢量。该方法的代价是接收端较复杂,不利于一发多收(如数字电视广播等)的应用。但这种方法估计精度高,可以满足运动补偿帧内插的要求。
考虑到计算复杂度和实时实现的要求,块匹配算法已成为目前最常用的运动估值算法。在块匹配算法中,先将当前帧图像分割成 MxN的图像子块,并假设位于同一图像子块内的所有像素都作相同的运动,且只做平移运动。虽然实际上块内各像素的运动不一定相同,也不一定只做平移运动,但当MxN较小时,上述假设可近似成立。这样做的目只是为了简化运算。块匹配算法对当前帧图像的每一子块,在前一帧(参考帧)的一定范围内搜索最优匹配,并认为本图像子块就是从前一帧最优匹配块位置处平移过来的。设可能的最大位移矢量为(dx max ,dy max ),则搜索范围为(M+2dx max) × (M+2dy max),如下图所示。
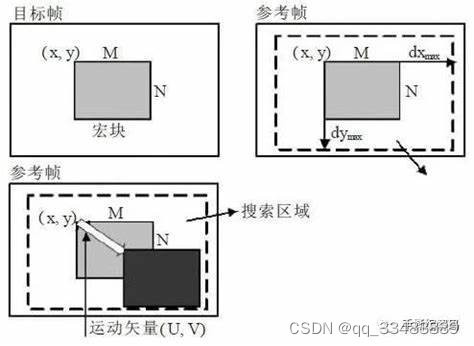
从运动估计的定义中我们可以捕获到3点信息:①图像序列基于块的分割②需要一个匹配准则③如何去搜索最相似的块。也就是说,块匹配运动估计算法的性能取决于:块尺寸的大小,匹配准则以及搜索策略。
在实际应用中,方块大小的选取受到两个矛盾的约束。块大时,一个方块可能包含多个做不同运动的物体,块内各像素做相同平移运动的假设难以成立,影响估计精度;但若块大小,则估计精度容易受噪声干扰的影响,不够可靠,而且传送运动矢量所需的附加比特数过多,不利于数据压缩。因此,必须恰到好处地选择方块的大小,以做到两者兼顾。日前的图像压缩编码标准,如MPEG-1、MPEG-2等,一般都用16x16大小块作为匹配单元,这是一个已被实践所证明了的较好的折中结果。但后来的H.264、H.265和H.266都是利用更高压缩率的块大小可变的运动补偿和估计。
衡量匹配的好坏有不同的准则,常用的有绝对差均值(Mean Absolute Difference, MAD)最小准则、均方误差(Mean Squared Error, MSE)最小准则和归一化互相关函数最大准则等。各种准则性能差别不显著,而MAD 最小准则不需做乘法运算,实现简单、方便,所以应用最广。
有了匹配原则,剩下的问题就是寻找最优匹配点的搜索方法,最简单可靠的就是穷尽搜索的全搜索方法,虽然该方法简单可靠,找到的匹配点肯定是全局最优点,但是计算量大,适合于ASIC芯片的实现。
为了减少软件实现环境中运动估值的计算量,如二维对数法、三步搜索法、菱形搜索算法、六边形搜索算法、交叉搜索法、共轭方向法等的快速搜索算法应运而生,这些快速搜索算法的共同之处在于它们把使准则函数(如MAD)趋于极小的方向视为最小失真方向,并认为在该方向是单调递增的,有唯一的极小值,从任一起始点开始沿最小失真方法进行快速搜索,这些快速搜索方法实质上都是统一的梯度搜索法,所不同的是搜索路径和步长有所区别。
然而快速搜索法的性能稍差,因此又提出了分级搜索方法,在减少运算量的同时,力求接近全搜索的效果。在分级搜索方法中,先通过对原始图像滤波和亚采样得到一个图像序列的低分辨率表示,再对所得低分辨率图像进行全搜索。由于分辨率降低,使得搜索次数成倍减少,这一步称为粗搜索。然后,再以低分辨率图像搜索的结果作为下一步细搜索的起始点。经过粗、细两级搜索,便得到了最终的运动矢量估值。















 2352
2352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









