







目录
1、将bmp文件转换为yuv文件(使用之前做的bmptoyuv代码)
实验要求
1、掌握DPCM编解码系统的基本原理。
2、初步掌握实验用C/C++/Python等语言编程实现DPCM编码器,并分析其压缩效率。
实验原理
DPCM(差分预测编码):利用信源相邻符号之间的相关性。早在电视原理和通信原理课上我们便已经接触了DPCM算法。在电视原理在传输视频数据时,经常将预测编码运用到帧内预测和帧间预测,由于视频两帧之间有大量相同内容,利用预测编码,先传输第一个采样点数值,再传输相邻采样点之间的差值,每次传输直接传输差值,第二个采样点=第一个采样点+差值...以此类推。由于视频之间相同内容较多,差值较小,每次传输时可用小比特表示图像,降低了对传输带宽的要求;在通信原理中,在对模拟信号进行编码传输时,也用到了DPCM算法。
(本质:建立一个新信源,将原始信源变为预测误差的信源)
简单总结DPCM算法思想为:根据模型利用以往的样本值对新样本进行预测,每次传输时,只需要传输预测值和实际值之间的差值。
DPCM算法逻辑图:(重点观察两个地方:上半部分量化、下半部分预测)
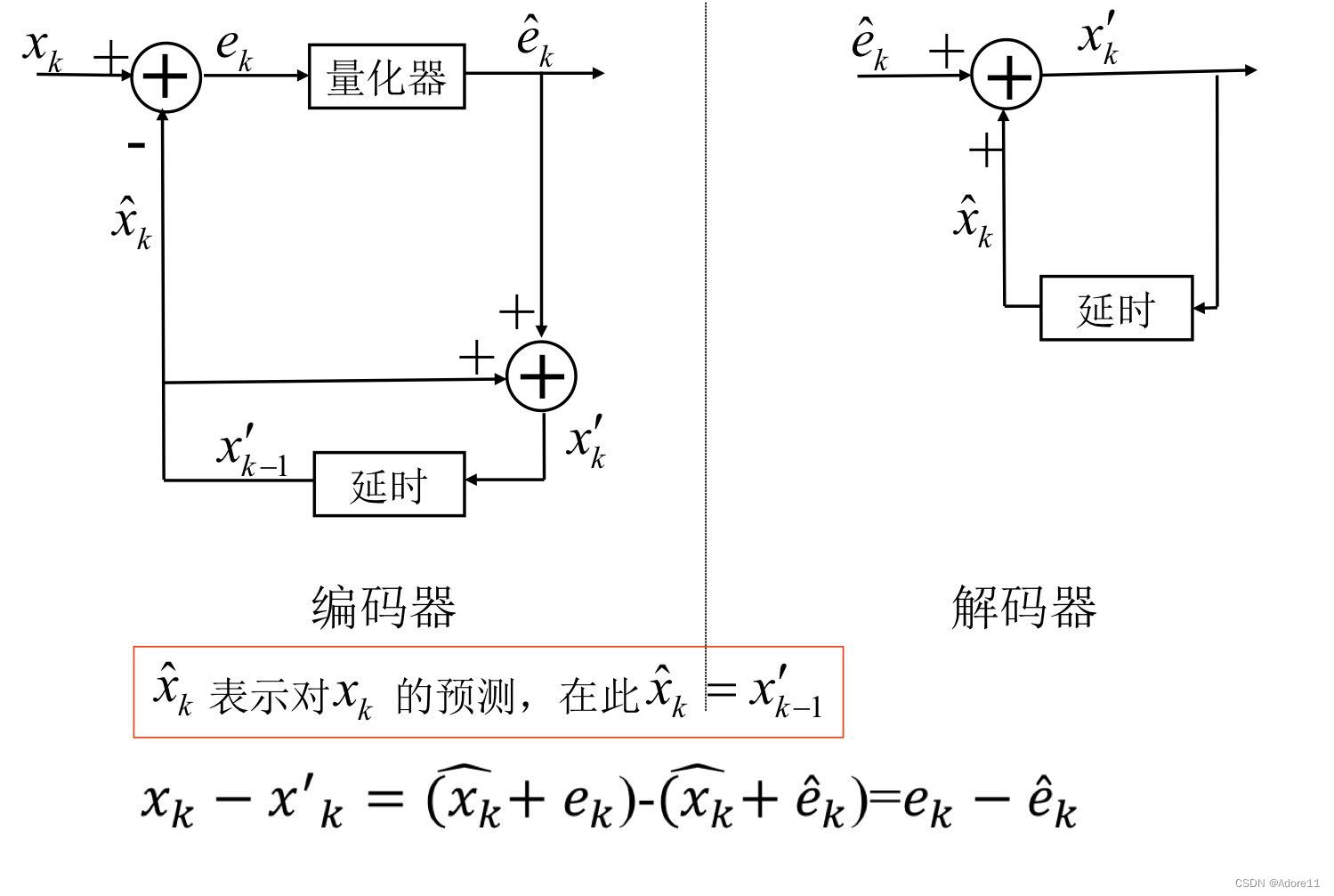
DPCM算法重点在于理解负反馈过程。注意这里的意思:

实验内容
在本次实验中,我们采用固定预测器和均匀量化器。
预测器采用左侧、上方预测均可,量化器采用8比特均匀量化,还可对预测误差进行1比特、2比特和4比特的量化设计(提高要求)。
本实验的目标是验证DPCM编码的编码效率。在DPCM编码器实现的过程中可同时输出预测误差图像和重建图像。将预测误差图像写入文件并将该文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。将原始图像文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。
最后比较两种系统(1.DPCM+熵编码和2.仅进行熵编码)之间的编码效率(压缩比和图像质量)。压缩质量以PSNR进行计算。
实验步骤
1.输入图片(提前将bmp文件转换为yuv文件)
2.根据给定的量化比特数进行量化和预测
3.输出预测误差图像和重建图像
4.将预测误差图像写入文件并将该文件输入Huffman编码器
5.根据输出码流画概率分布图、计算压缩比
4.度量失真程度(计算PSNR峰值信噪比)
5.对原始图像和预测误差图像进行Huffman编码
实验代码
1、将bmp文件转换为yuv文件(使用之前做的bmptoyuv代码)
以Birds.bmp为例,arg[1]表示输入,arg[2]表示输出,1表示读写次数1次,输入rgb文件,输出yuv文件
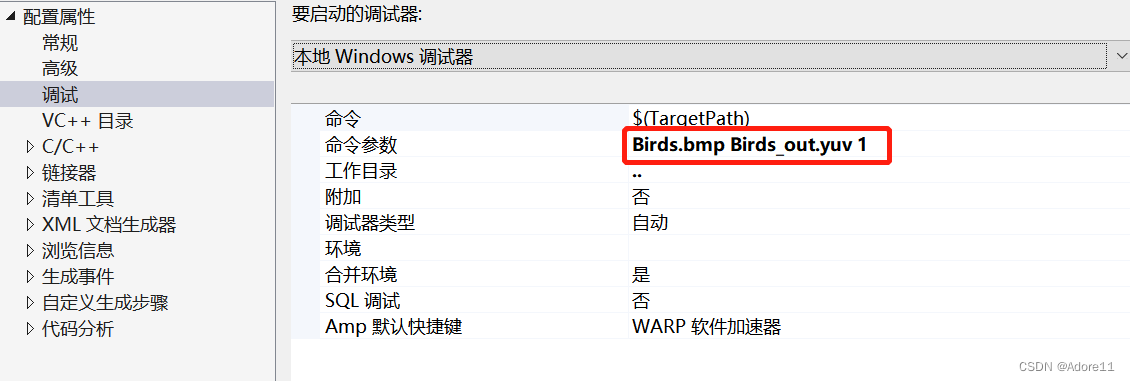
2、新建项目,设置命令行参数
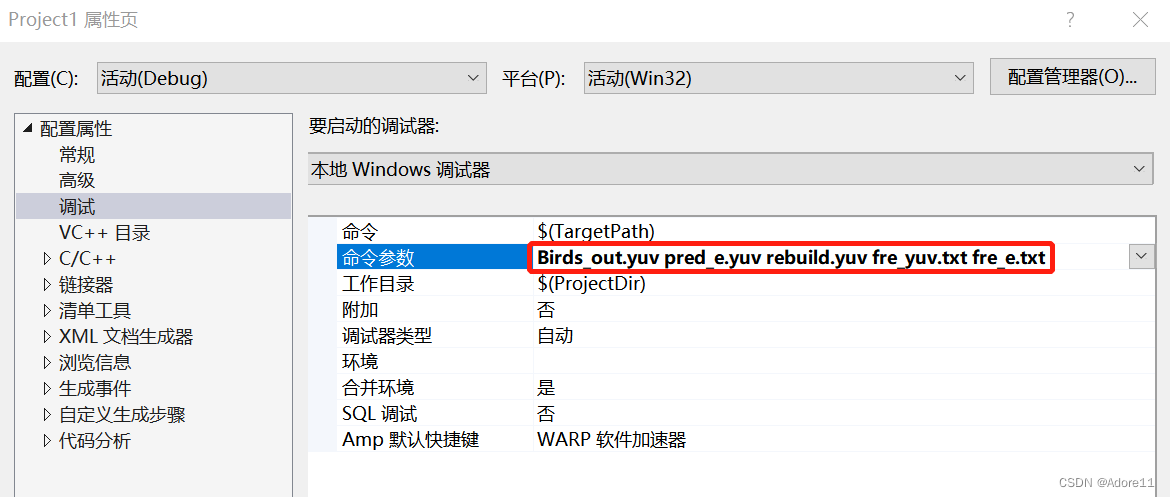
arg[1]表示输入原图,arg[2]表示预测误差,arg[3]表示重建图,arg[4]表示原图概率分布,arg[5]表示残差概率分布
3、main函数
int main(int argc, char* argv[])
{
//初始化
int height = 768;
int width = 512;
int bit = 8;
FILE* yuvname = NULL;
FILE* e_name = NULL;
FILE* rebuid_name = NULL;
FILE* freq_yuv = NULL;
FILE* freq_e = NULL;
//定义缓冲区
unsigned char* predict_buffer;
unsigned char* y_buffer;
unsigned char* u_buffer;
unsigned char* v_buffer;
unsigned char* rebuid_buffer;
y_buffer = (unsigned char*)malloc(width * height);
u_buffer = (unsigned char*)malloc(width * height / 4);
v_buffer = (unsigned char*)malloc(width * height / 4);
rebuid_buffer = (unsigned char*)malloc(width * height);
predict_buffer = (unsigned char*)malloc(width * height);
//打开文件
fopen_s(&yuvname, argv[1], "rb");
fopen_s(&e_name, argv[2], "wb");
fopen_s(&rebuid_name, argv[3], "wb");
fopen_s(&freq_yuv, argv[4], "wb");
fopen_s(&freq_e, argv[5], "wb");
if (yuvname == NULL || e_name == NULL || rebuid_name == NULL)
{
cout << "Open Error!" << endl;
return 0;
}
//读取文件
fread(y_buffer, 1, width * height, yuvname);
fread(u_buffer, 1, (width * height) / 4, yuvname);
fread(v_buffer, 1, (width * height) / 4, yuvname);
//预测差分编码
DPCM(y_buffer, predict_buffer, rebuid_buffer, width, height, bit);
//计算PSNR
PSNR(y_buffer, rebuid_buffer, height, width, bit);
//计算概率分布
int size = height * width;
int count[256] = { 0 };
int pro_y[256] = { 0 };
int pro_e[256] = { 0 };
for (int i = 0; i < size; i++) {
int color = *(y_buffer + i);// (int_buf + i)点的灰度值
count[color]++;
}
for (int j = 0; j < 256; j++)//灰度概率
{
pro_y[j] = (double(count[j]) / size);//原图的概率分布
}
for (int i = 0; i < size; i++) {
int color = *(predict_buffer + i);// (int_buf + i)点的灰度值
count[color]++;
}
for (int j = 0; j < 256; j++)//灰度概率
{
pro_e[j] = (double(count[j]) / size);//预测误差的概率分布
}
//写预测误差文件
fwrite(predict_buffer, 1, width * height, e_name);
fwrite(u_buffer, 1, (width * height) / 4, e_name);
fwrite(v_buffer, 1, (width * height) / 4, e_name);
//写预重建图像文件
fwrite(rebuid_buffer, 1, width * height, rebuid_name);
fwrite(u_buffer, 1, (width * height) / 4, rebuid_name);
fwrite(v_buffer, 1, (width * height) / 4, rebuid_name);
//写概率分布
for (int i = 0; i < 256; i++) {
fprintf(freq_yuv, "%f\n", pro_y[i]);
fprintf(freq_e, "%f\n", pro_e[i]);
}
free(y_buffer);
free(u_buffer);
free(v_buffer);
free(predict_buffer);
free(rebuid_buffer);
fclose(yuvname);
fclose(e_name);
fclose(rebuid_name);
return 0;
}4、定义DPCM函数:
采用左向预测


原始值取值范围(0,255),减去预测值(0,255),预测误差的范围为(-255,255),为保证传入的误差值为正,(预测误差+255),范围为(0,510)-->所需要的bit数为9bit。如果之后想要用4bit、16bit量化可以按照
int Quality(int error, int bit) {///量化
return (error + 255) / pow(2, (9 - bit));//这里pow就是2的(9-bit)次方
}
int FanQuality(int bit, unsigned char rebuid_buffer) {反量化
return rebuid_buffer *pow(2,(9-bit))-255;
}
void DPCM(unsigned char* y_buffer, unsigned char* predict_buffer, unsigned char* rebuid_buffer, int width, int height, int bit)
{
int error;
for (int i = 0; i < height; i++) {///行
for (int j = 0; j < width; j++) {列
if (j == 0) { //第一列以128进行预测
error = (y_buffer[i * width + j]) - 128; //误差值
predict_buffer[i * width + j] = Quality(bit, error); //量化误差值
rebuid_buffer[i * width + j] = FanQuality(bit, predict_buffer[i * width + j]) + 128; //重建值(反量化之后)
}
else { //其他列都以前一列进行预测
error = (y_buffer[i * width + j]) - rebuid_buffer[i * width + j - 1]; //误差值,左侧-右侧
predict_buffer[i * width + j] = Quality(bit, error); //量化误差值
rebuid_buffer[i * width + j] = FanQuality(bit, predict_buffer[i * width + j]) + rebuid_buffer[i * width + j - 1]; //重建值
}
}
}
}5、PSNR峰值信噪比函数
在客观评价图像质量时,我们经常会遇到峰值信噪比PSNR,计算PSNR需要提前计算MSE,这里给出下面两个的公式:
PS:这里的MAX为图像的灰度级,一般等于255。
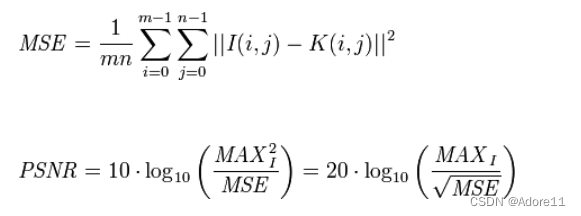
double PSNR(unsigned char* y_buffer, unsigned char* rebuid_buffer, int height, int width, int dep) {
double max = 255;
double mse = 0;
double psnr=0;
for (int i = 0; i < height; i++)
for (int j = 0; j < width; j++) {
mse += (y_buffer[i * width + j] - rebuid_buffer[i * width + j]) * (y_buffer[i * width + j] - rebuid_buffer[i * width + j]);
}
mse = mse / (double)(width * height);
psnr = 10 * log10((double)(max * max) / mse);
return psnr;
}得到PSNR结果:
| 量化比特数 | PSNR(客观评价) | 预测误差图像 | 重建图像(主观评价) | 概率分布 |
| 8bit | 51.1408 |  |  | 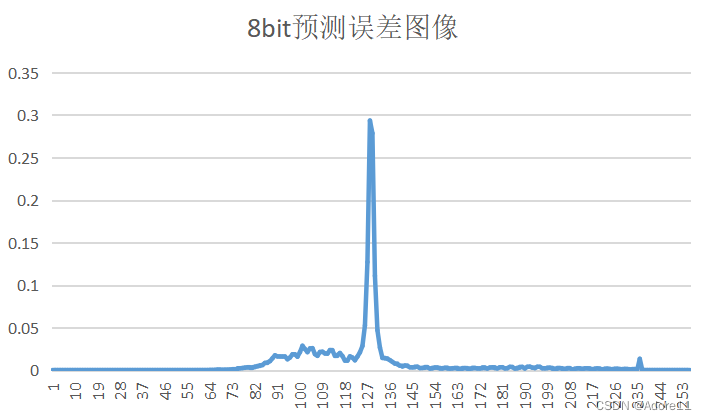 |
| 4bit | 23.0487 |  |  |  |
| 2bit | 9.91007 |  |  |  |
| 1bit | 9.73155 |  |  | 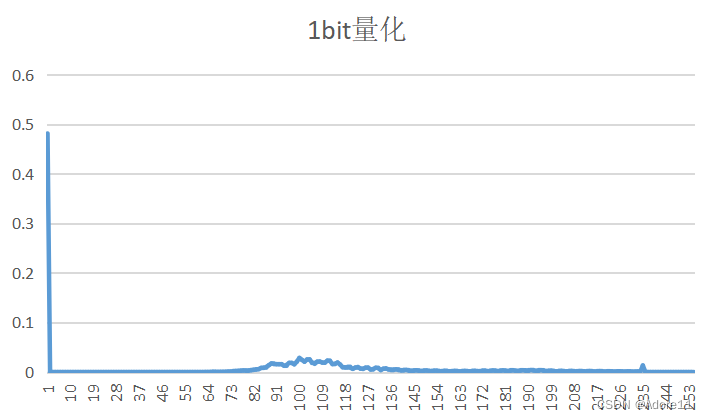 |
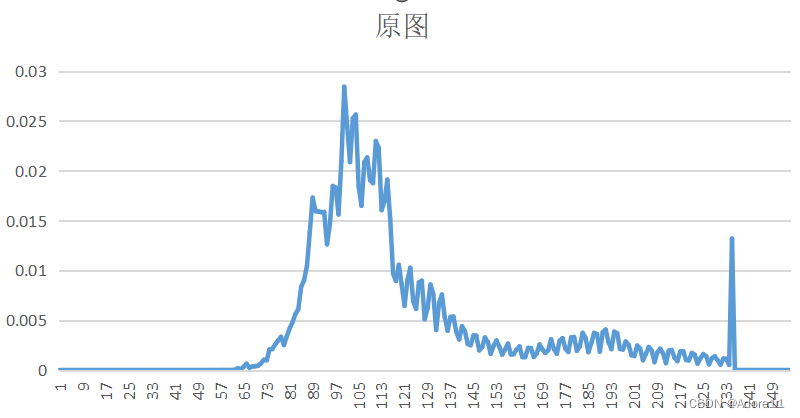
原图的概率分布计算:
#include<iostream>
#include<math.h>
using namespace std;
int main(int argc, char* argv[])
{
//初始化
int height = 768;
int width = 512;
int bit = 1;
FILE* yuvname = NULL;
FILE* out = NULL;
//定义缓冲区
unsigned char* y_buffer;
unsigned char* u_buffer;
unsigned char* v_buffer;
y_buffer = (unsigned char*)malloc(width * height);
u_buffer = (unsigned char*)malloc(width * height / 4);
v_buffer = (unsigned char*)malloc(width * height / 4);
//打开文件
fopen_s(&yuvname, argv[1], "rb");
fopen_s(&out, argv[4], "rb");
if (yuvname == NULL )
{
cout << "Open Error!" << endl;
return 0;
}
//读取文件
fread(y_buffer, 1, width * height, yuvname);
fread(u_buffer, 1, (width * height) / 4, yuvname);
fread(v_buffer, 1, (width * height) / 4, yuvname);
//计算概率分布
int size = height * width;
double count[256] = { 0 };
double pro_y[256] = { 0 };
double pro_e[256] = { 0 };
for (int i = 0; i < size; i++) {
int color = *(y_buffer + i);// (int_buf + i)点的灰度值
count[color]++;
}
for (int j = 0; j < 256; j++)//灰度概率
{
pro_y[j] = (double(count[j]) / size);//原图的概率分布
}
//写概率分布
for (int i = 0; i < 256; i++) {
fprintf(out, "%f\n", pro_y[i]);
}
free(y_buffer);
free(u_buffer);
free(v_buffer);
fclose(yuvname);
return 0;
} 
总结:
观察原图概率分布和预测误差图像概率分布,我们可以看出,原图的概率分布“范围”更广,取值相比于预测误差图像而言,分布更均匀,因此其熵也更大。
对于无失真编码而言,由于香农第一定理,信源符号平均码长的下界为信源熵,如果想达到最好的压缩效果,就希望平均码长最小;利用信源符号间的相关性,减小编码的信息冗余,将均匀分布的信源符号转换为非均匀分布,减少信源熵,提高压缩效率。
补充实验:
比较DPCM+熵编码和仅进行熵编码之间的编码效率(压缩比和图像质量)
---> 打开Huffmancode.bat,写入输入、输出,利用Huffman编码器进行熵编码,将熵编码后的结果保存在birds.txt和birds_DPCM.txt中(保存后点击.bat文件)
保存、运行Huffmancode.bat,得到结果

Birds_out.huff为仅进行熵编码的文件、birds_DPCM为进行DPCM+熵编码的文件,对这两个文件比较压缩比:
DPCM+8bit量化+熵编码-----压缩比: 576/340=2.1
仅进行熵编码---------压缩比:576/488=1.6
由此可见,经过熵编码后图像的压缩比更大,即系统的压缩效果更好。
Final总结:
通过本次实验我深刻理解了预测-熵编码的过程。预测尽可能利用信源符号的相关性,减小信息冗余,最大程度的减小信源符号熵。聪明的DPCM系统,通过只传误差,对误差进行编码等,提高了压缩效率。同时在编码器里引入解码器,保证编解码端同步,减少产生误差漂移。















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









