







leetcode 数据库习题练习
- 简单难度
- 175. 组合两个表(left join ... on)
- 176*. 第二高的薪水(ifnull ; )类似题目177
- 181. 超过经理收入的员工(判断是否为空(is null); 自联表)
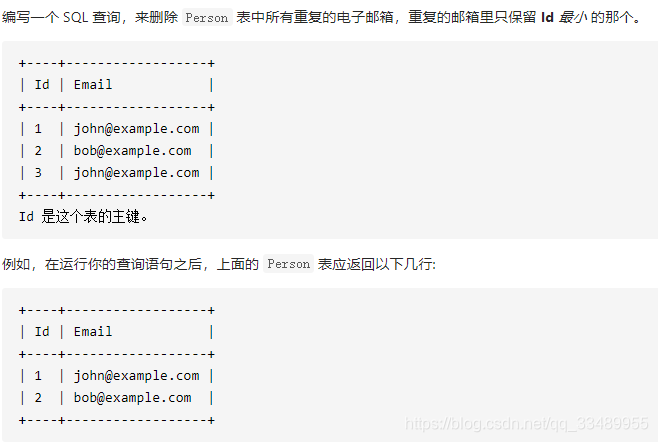
- 182.查找重复的电子邮箱(group by)
- 183. *从不订购的客户(子查询,not in)
- 196. 删除重复的电子邮箱 (delete , 自联表)
- 197*. 上升的温度(cross join ; datediff() )
- 595. 大的国家(弱智题,没营养的)
- 596. (group by ,having ; 子查询)
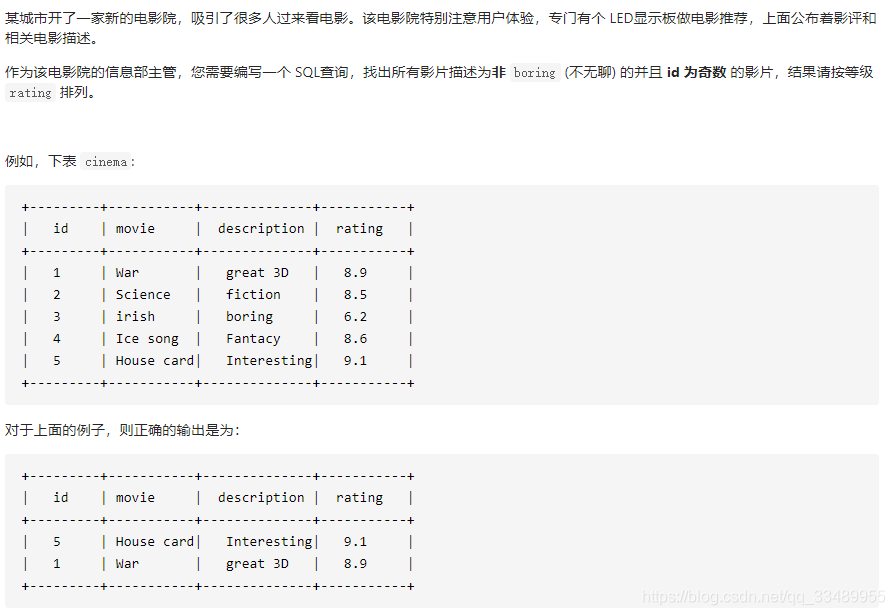
- 620. 有趣的电影(按位与(&)|mod(num,2) 判断奇偶;order by 默认升序,且只能放在后边)
- 627*. 变更性别(update set ; case when)
- 1179. 重新格式化部门表(group by 与 sum() ; case when; )
- 中等难度:
- 困难难度
sql的运行顺序: from -> where -> group by -> select -> order by -> limit
简单难度
175. 组合两个表(left join … on)
题目描述


为避免数据丢失,故使用外连接,考虑到地址信息表可能有人没有填写(即地址表中没有该人员信息)。所以用Person 表 左外连接 Adress 表。
select FirstName,LastName,City,State
from Person as t1
left join Address as t2
on t1.PersonId = t2.PersonId;
176*. 第二高的薪水(ifnull ; )类似题目177
题目:

题解:需要关注的点有两个,一个是ifnull 的位置,还有无论如何都要有select
select ifnull(
(select Salary
from Employee
group by Salary
order by Salary desc
limit 1,1),null) as `SecondHighestSalary`; # limit offset,count
方法二:窗函数
select
ifnull((select distinct Salary from
(
select Salary,dense_rank() over( order by Salary desc) as rn from Employee
)as temp
where rn = 2
),null) as `SecondHighestSalary`;
181. 超过经理收入的员工(判断是否为空(is null); 自联表)

方法一:(自己边分析边写的,多此一举了,自联表更快,请移步方法二):
t1表:
select Name,Salary,ManagerId from Employee where ManagerId is not null;
| Name | Salary | ManagerId |
|---|---|---|
| Joe | 70000 | 3 |
| Henry | 80000 | 4 |
最终:
select t1.Name as `Employee` from
(select Name,Salary,ManagerId from Employee where ManagerId is not null) t1 , Employee t2
where t1.ManagerId=t2.Id and t1.Salary > t2.Salary;
方法二:(自联表)
select t1.Name as `Employee` from
Employee t1 , Employee t2
where t1.ManagerId=t2.Id and t1.Salary > t2.Salary;
方法三:使用 join 连表
select t1.Name as `Employee` from
Employee t1 join Employee t2
on
t1.ManagerId=t2.Id and t1.Salary > t2.Salary;
182.查找重复的电子邮箱(group by)

方法一:(group by)
这道题比较有意思的地方是,求的是重复出现过的邮箱,需要一个中间表来记录 Email,Email 对应出现的次数.
select Email from
(select Email,count(Email) as num from Person group by Email) temp
where num != 1;
方法二:(group by + having)重要*
select Email from Person group by Email having count(Email)>1;
顺序:温(where)哥(group by)华(having)ol(order by limit)
183. *从不订购的客户(子查询,not in)
题目描述:

法一:(子查询 + not in )
select t1.Name as `Customers` from Customers as t1
where t1.Id not in (
select CustomerId from Orders
);
法二:(左外连接)
select Name as `Customers`
from Customers t1
left join Orders t2
on t1.Id = t2.CustomerId
where t2.CustomerId is null;
196. 删除重复的电子邮箱 (delete , 自联表)
delete p1
from Person p1,Person p2
where p1.Email = p2.Email and p1.Id > p2.Id;
197*. 上升的温度(cross join ; datediff() )
题目解析 及 cross join ;datediff 介绍
题目介绍:


题解:
select t1.id
from Weather as t1 cross join Weather as t2 on datediff(t1.recordDate,t2.recordDate)=1
where t1.temperature > t2.temperature;
题解2:cross join 只是生成笛卡尔集,使用join也可以
cross join ; join ; inner join 区别
select t1.id
from Weather t1 join Weather t2 on datediff(t1.recordDate,t2.recordDate)=1
where t1.Temperature > t2.Temperature;
# datediff 的值是前 - 后
595. 大的国家(弱智题,没营养的)
题目:


题解:
select name,population,area from World
where area>3000000 or population>25000000;
596. (group by ,having ; 子查询)
题目描述:


题目解析链接
方法一:group by + having
select class
from courses
group by class
having count(distinct student)>=5;
方法二:子查询
先根据课程分组,查询课程及该课程的学生人数(去重后)作为临时表。再查询课程名称,条件是人数大于或者等于5
select class from(
select class,count(distinct student) as `count` from courses group by class
) as temp
where `count`>=5;
620. 有趣的电影(按位与(&)|mod(num,2) 判断奇偶;order by 默认升序,且只能放在后边)
select * from cinema
where id&1 and description!='boring'
order by rating desc ;
mod(id,2) = 1 返回id号是奇数的id
select id,movie,description,rating
from cinema
where description!='boring' and mod(id,2)=1
order by rating desc;
627*. 变更性别(update set ; case when)
题目描述:

题解: 注意update set的使用
update salary
set
sex =
case sex
when 'm' then 'f'
else 'm'
end;
1179. 重新格式化部门表(group by 与 sum() ; case when; )

select id,
sum(case when month='Jan' then revenue end )as Jan_Revenue,
sum(case when month='Feb' then revenue end )as Feb_Revenue,
sum(case when month='Mar' then revenue end )as Mar_Revenue,
sum(case when month='Apr' then revenue end )as Apr_Revenue,
sum(case when month='May' then revenue end )as May_Revenue,
sum(case when month='Jun' then revenue end )as Jun_Revenue,
sum(case when month='Jul' then revenue end )as Jul_Revenue,
sum(case when month='Aug' then revenue end )as Aug_Revenue,
sum(case when month='Sep' then revenue end )as Sep_Revenue,
sum(case when month='Oct' then revenue end )as Oct_Revenue,
sum(case when month='Nov' then revenue end )as Nov_Revenue,
sum(case when month='Dec' then revenue end )as Dec_Revenue
from Department
group by id
order by id;
理解:为什么使用sum聚合函数:

也就是说如果不使用聚合函数而是直接查询,那么第一组的数据(id=1)只有第一行会被检索到,后面两行不会被检索到,会使结果变为空值。
即:
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | … | Dec_Revenue |
|---|---|---|---|---|---|
| 1 | 8000 | null | null | … | null |
| 2 | 9000 | null | null | … | null |
| 3 | null | 10000 | null | … | null |
而非正确答案
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | … | Dec_Revenue |
|---|---|---|---|---|---|
| 1 | 8000 | 7000 | 6000 | … | null |
| 2 | 9000 | null | null | … | null |
| 3 | null | 10000 | null | … | null |
中等难度:
177*. 第N高的薪水(mysql函数 ;窗口函数;)
题目描述:

解法一(窗函数的使用):
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
select distinct Salary from
(
select Salary,dense_rank() over( order by Salary desc) as rn from Employee
)as temp
where rn = N
);
END
解法二 (单表查询,group by + order by + limit)

题解:注意赋值语句后面要加封号的
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
set N:= N-1;
RETURN (
# Write your MySQL query statement below.
select Salary
from Employee
group by Salary
order by Salary desc
limit N,1
);
END
其他解法
178. 分数排名(窗函数经典问题)
题目描述:


解析:
注意Rank 是关键字,作为变量需要引起来 `Rank`
select Score,dense_rank() over (order by Score desc) as `Rank` from Scores;
180*. 连续出现的数字(自联表 / 窗函数*(连续出现N次问题))
解析链接
使用自联表:
select distinct t1.num as ConsecutiveNums from
Logs as t1,
Logs as t2,
Logs as t3
where t1.id = t2.id-1
and t2.id = t3.id-1
and t1.num = t2.num
and t2.num = t3.num;
使用窗函数
考查窗口函数lag、lead的用法:(*重要)
使用lead()
select distinct num as `ConsecutiveNums`
from
(select num,
lead(num,1) over(order by id) as num2,
lead(num,2) over(order by id) as num3
from Logs
) as t
where t.num = t.num2 and t.num = t.num3;
使用lag()
select distinct num as `ConsecutiveNums`
from
(select num,
lag(num,1) over(order by id) as num2,
lag(num,2) over(order by id) as num3
from Logs
) as t
where t.num = t.num2 and t.num = t.num3;
184. 部门工资最高的员工(窗函数)–具体解析看185
使用窗函数解法:
select dname as `Department`,ename as `Employee`,Salary
from (
select t1.Name as ename,Salary,t2.Name as dname, dense_rank() over (partition by DepartmentId order by Salary desc) as rn from Employee as t1, Department as t2 where t1.DepartmentId = t2.Id
) as temp
where rn <=1;
非窗函数解法:
select t3.Name as `Department`,temp.Name as `Employee`,Salary from
(
select Name,t1.Salary,DepartmentId from Employee as t1
where 1 > (
select count(distinct Salary) from Employee as t2
where t1.Salary < t2.Salary and t1.DepartmentId = t2.DepartmentId
)
) as temp, Department as t3 where temp.DepartmentId = t3.Id;
626. 换座位(case when;可以 from表和查询出来的值)


分布题解:
首先计算座位数,因为后边要判断奇偶
select count(*) as counts from seat;
接下来搜索 id 和 学生 ,需要注意一点case when 语句可以引用counts ,但是引用seat_counts时会报错
select
(case
when id!= counts and mod(id,2)!=0 then id+1
when id = counts and mod(id,2)!=0 then id
else
id-1
end) as id, student
from seat,(select count(*) as counts from seat) as seat_counts;
| id | student |
|---|---|
| 2 | Abbot |
| 1 | Doris |
| 4 | Emerson |
| 3 | Green |
| 5 | Jeames |
最终:使用order by 重新调整顺序
select
(case
when id!= counts and mod(id,2)!=0 then id+1
when id = counts and mod(id,2)!=0 then id
else
id-1
end) as id, student
from seat,(select count(*) as counts from seat) as seat_counts
order by id;

困难难度
185. 部门工资前三高的员工(窗函数)
使用窗函数查询
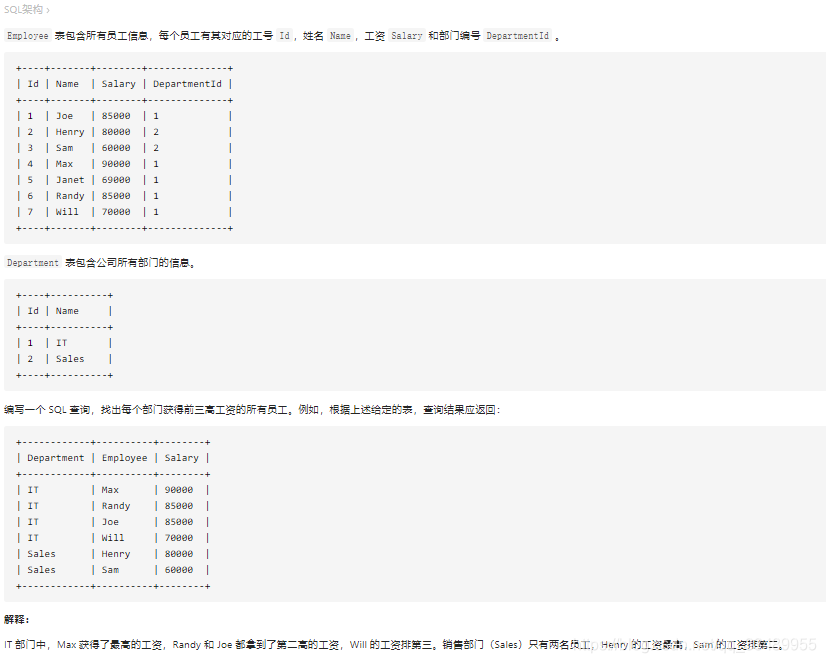
使用窗函数:

先使用窗函数求出分部门并以工资排序的新表,再利用该中间表做查询
select t2.Name as dname,t1.Name as ename,Salary,dense_rank() over(partition by DepartmentId order by Salary desc) as rn
from Employee as t1, Department as t2 where t1.DepartmentId=t2.Id;
| dname | ename | Salary | rn |
|---|---|---|---|
| IT | Max | 90000 | 1 |
| IT | Joe | 85000 | 2 |
| IT | Randy | 85000 | 2 |
| IT | Will | 70000 | 3 |
| IT | Janet | 69000 | 4 |
| Sales | Henry | 80000 | 1 |
| Sales | Sam | 60000 | 2 |
最终查询:
select dname as `Department` ,ename as `Employee`,Salary from
(select t2.Name as dname,t1.Name as ename,Salary,dense_rank() over(partition by DepartmentId order by Salary desc) as rn
from Employee as t1, Department as t2 where t1.DepartmentId=t2.Id) temp
where rn <=3;
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
补充:rank(),dense_rank(),row_num()
不使用窗函数查询 (自连表)
先自连表查出薪资前三的姓名,工资,部门编号作为新表
select Name,t1.Salary,DepartmentId from Employee as t1
where 3 > (
select count(distinct Salary) from Employee as t2
where t1.Salary < t2.Salary and t1.DepartmentId = t2.DepartmentId
);

| Name | Salary | DepartmentId |
|---|---|---|
| Joe | 85000 | 1 |
| Henry | 80000 | 2 |
| Sam | 60000 | 2 |
| Max | 90000 | 1 |
| Randy | 85000 | 1 |
| Will | 70000 | 1 |
select t3.Name as `Department`, temp.Name as `Employee`, Salary
from
(select Name,t1.Salary,DepartmentId from Employee as t1
where 3 > (
select count(distinct Salary) from Employee as t2
where t1.Salary < t2.Salary and t1.DepartmentId = t2.DepartmentId
)
) as temp, Department as t3
where temp.DepartmentId = t3.Id;
| Department | Employee | Salary |
|---|---|---|
| IT | Joe | 85000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Will | 7000 |
262 .行程和用户*
题目:




题目解析:



解法:
select request_at as `Day`,
round(sum(if(t.status = 'completed',0,1))/count(t.status),2) as `Cancellation Rate`
from Trips as t
join Users as u1 on (t.client_id = u1.users_id and u1.banned = "No")
join Users as u2 on (t.driver_id = u2.users_id and u2.banned = "No")
where request_at between "2013-10-01" and "2013-10-03"
group by request_at;
其他解法:这里
601.体育馆的人流量
题目:


方法一:自联表
select distinct s1.* from Stadium s1,Stadium s2, Stadium s3
where s1.people >= 100 and s2.people >= 100 and s3.people >= 100
and (
(s1.id + 1 = s2.id and s1.id + 2 = s3.id and s2.id + 1 = s3.id) or -- s1是巅峰期第一天
(s1.id - 1 = s2.id and s1.id + 1 = s3.id and s2.id + 2 = s3.id) or -- s1是巅峰期第二天
(s1.id - 2 = s2.id and s1.id - 1 = s3.id and s2.id + 1 = s3.id) -- s1是巅峰期第三天
)
order by id;
方法二:(待补充)















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









